As versões full-blood de o3 e o4-mini apareceram tarde da noite. Pela primeira vez, o raciocínio por imagem foi integrado à cadeia de pensamento e as ferramentas puderam ser chamadas de forma independente para resolver problemas complexos em 60 segundos. Em particular, o3 atualiza a programação, a matemática e o raciocínio visual SOTA com dez vezes o poder de computação do o1, aproximando-se do "nível genial". Além disso, a OpenAI também abriu o código-fonte do artefato de programação Codex CLI, que se tornou popular da noite para o dia.
Como esperado, a versão completa de saúde do o3 está realmente aqui.
Agora mesmo, o co-criador do OpenAI, Greg Brockman, e o diretor de pesquisa, Mark Chen, lideraram uma equipe para iniciar uma transmissão ao vivo online de 20 minutos.
Desta vez não existe apenas o3, mas também o modelo de inferência de próxima geração o4-mini. Eles percebem pela primeira vez o “pensar com imagens”, o que pode ser chamado de ápice do raciocínio visual.

Assim como os agentes de IA, os dois modelos julgaram e combinaram de forma independente as ferramentas integradas do ChatGPT para gerar respostas detalhadas e abrangentes em menos de 1 minuto.
Isso inclui pesquisar páginas da web, usar Python para analisar arquivos e dados carregados, realizar raciocínio aprofundado sobre entradas visuais e até mesmo gerar imagens.

Em testes de benchmark como Codeforces, SWE-bench e MMMU, o3 atualiza SOTA e estabelece novos benchmarks em programação, matemática, ciências e percepção visual.
Em particular, o3 tem um desempenho particularmente bom para análises de imagens, gráficos e gráficos e pode se aprofundar nos detalhes da entrada visual.
|
|
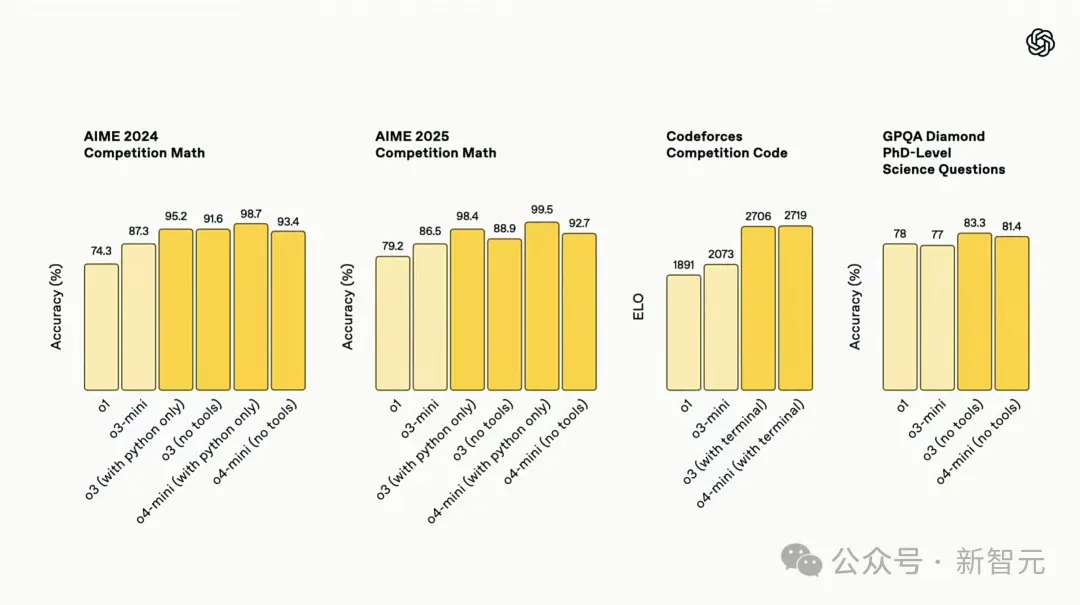
No Codeforces, os novos modelos marcaram mais de 2.700 pontos, ficando entre os 200 principais concorrentes globais.
Nas palavras de Ultraman, “perto ou atingindo o nível de gênio”.

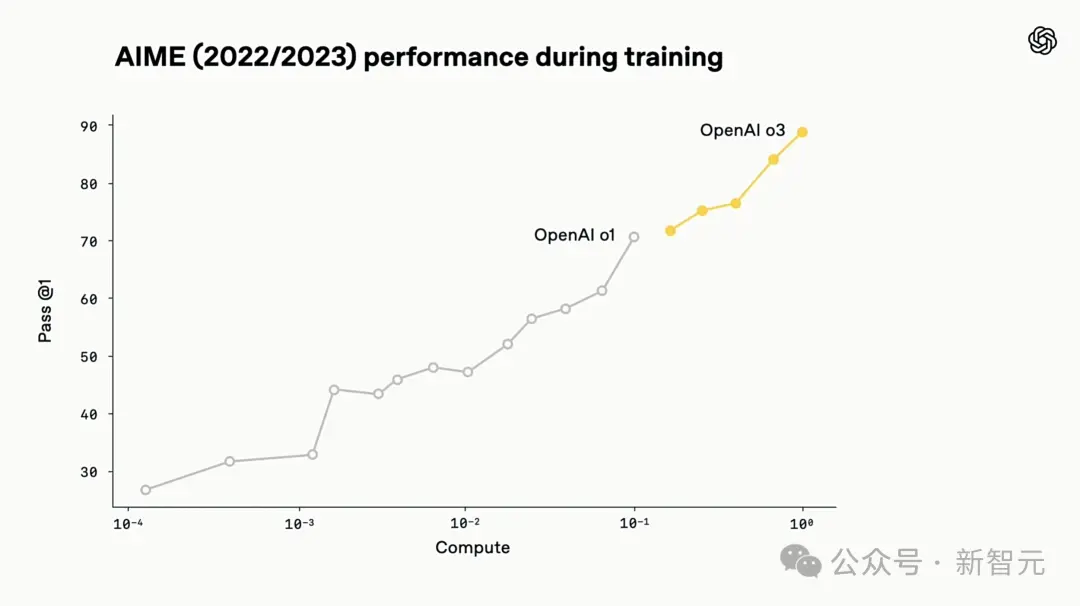
No entanto, o preço desta inteligência é que ela requer mais de dez vezes o poder computacional do o1.
Comparado com a versão completa do o3, o o4-mini se destaca por sua compacidade, eficiência e alto desempenho de custo.
No teste AIME 2025, o4-mini alcançou uma pontuação alta de 99,5% com o interpretador Python, vencendo quase perfeitamente este teste de benchmark.
Além disso, seu desempenho é melhor do que o3-mini em matemática, programação, tarefas visuais e áreas não STEM.
Além disso, o4-mini suporta muito mais uso que o3, tornando-o a melhor escolha para cenários de alta simultaneidade.
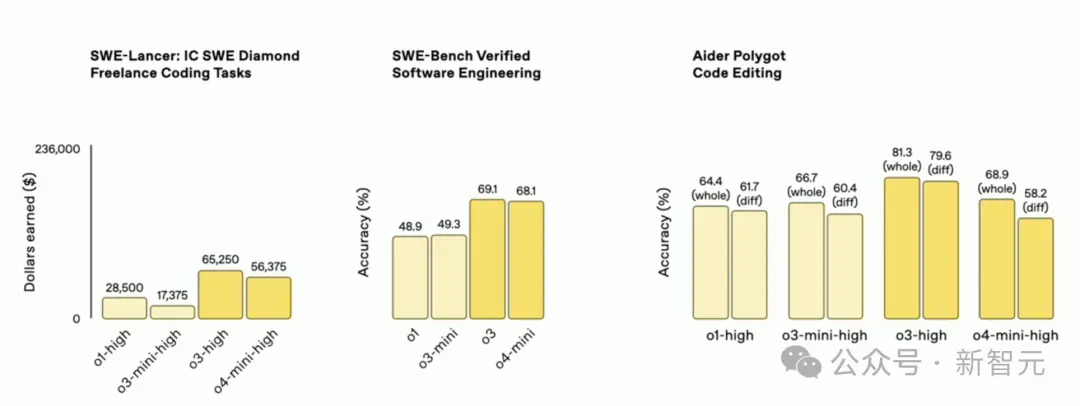
Resumindo, tanto o3 quanto o4-mini são muito bons em codificação, então a OpenAI também abriu o código-fonte de um agente de IA de programação leve que pode ser executado no terminal - Codex CLI.
|
|
A partir de hoje, os usuários do ChatGPT Plus, Pro e Team serão os primeiros a experimentar o3, o4‑mini e o4‑mini‑high, que substituirão o1, o3‑mini e o3‑mini‑high.
Ao mesmo tempo, esses dois modelos também estarão disponíveis para todos os desenvolvedores por meio da API Chat Completions e da API Responses.
Modelo de inferência, usando ferramentas pela primeira vez
Durante a demonstração ao vivo, Greg mencionou pela primeira vez um valor – alguns modelos são como um salto qualitativo, GPT-4 é um deles, e o mesmo se aplica ao o3/o4-mini hoje.
Ele disse que o3 permitiu que ele e seus colegas da OpenAI vissem que grandes modelos de IA podem realizar “coisas que nunca foram vistas antes”. Por exemplo, ele próprio teve uma ótima ideia de arquitetura de sistema.
O que é realmente surpreendente nestes dois modelos é que não são apenas modelos, são um “sistema de IA”.
A maior diferença entre eles e os modelos de inferência anteriores é que eles são usados para treinar diversas ferramentas pela primeira vez. Eles usarão estas ferramentas no CoT para resolver problemas difíceis.
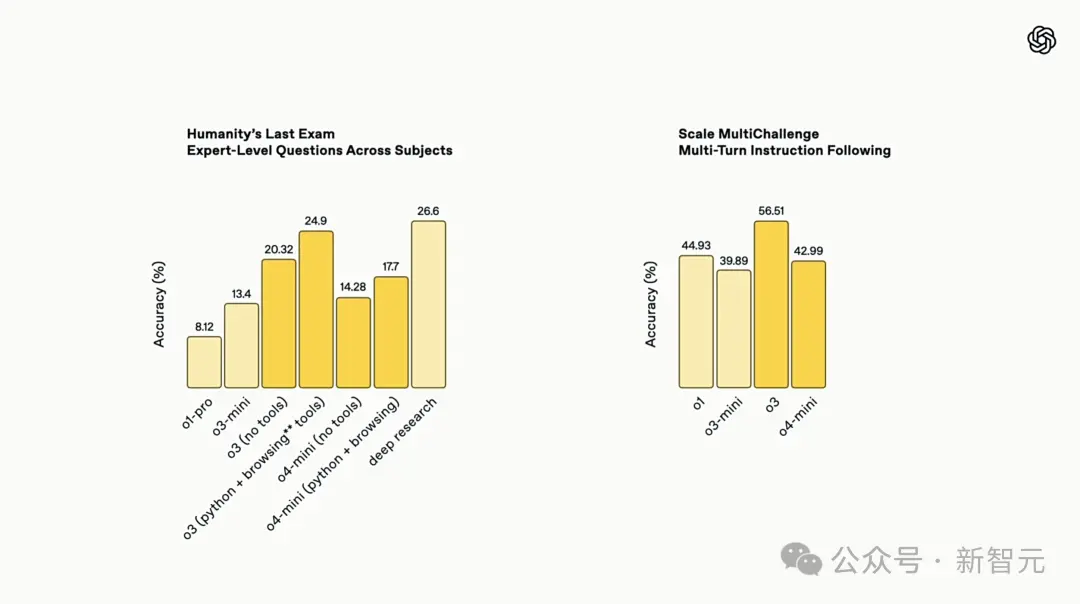
No exame humano final, o modelo o3 é comparável ao desempenho da Deep Research e é mais rápido
Para superar um problema complexo, a o3 utilizou cerca de 600 chamadas de ferramentas consecutivas. Eles geram trechos de código de uma vez por todas que realmente funcionam na base de código.
Greg disse que o que ele mais valoriza são suas capacidades de engenharia de software: eles não apenas podem escrever código único, mas também podem realmente trabalhar em uma base de código real!
Por exemplo, ele faz um trabalho melhor do que Greg ao navegar na base de código OpenAI. É aqui que é extremamente útil.

Além disso, na avaliação do seguimento de instruções e do uso da ferramenta do agente, a precisão do o3 e do o4-mini combinados com a ferramenta é a mais alta.
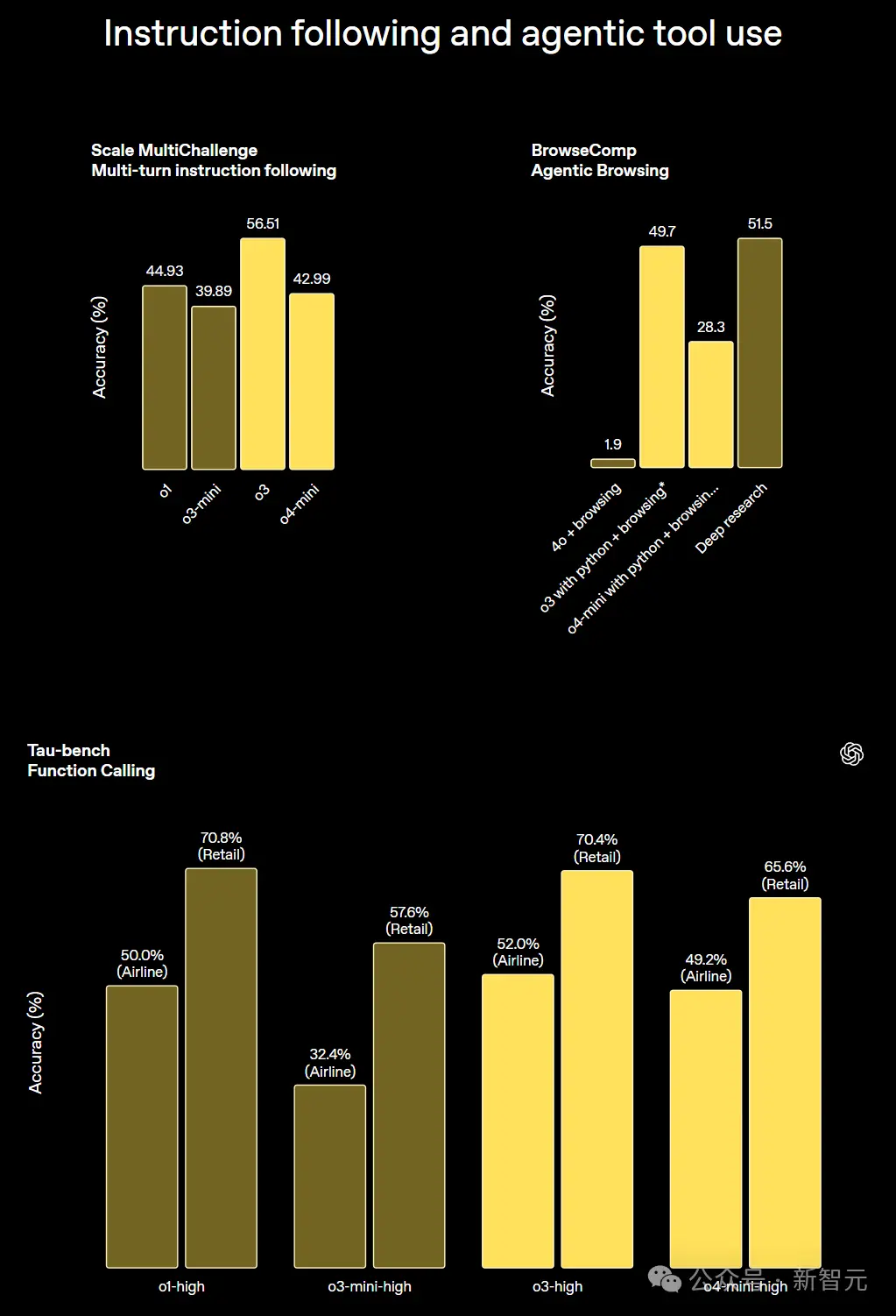
A avaliação de especialistas externos mostra que quando o3 lida com tarefas do mundo real, a sua taxa de erro grave é 20% inferior à do o1.
A razão para esse grande progresso é precisamente impulsionada pelos contínuos avanços algorítmicos em RL. Nas palavras de Greg, a coisa mais incrível nos bastidores é que atualmente ele ainda está prevendo um token e, em seguida, adicionando um pouco de RL AI, chegou a esse ponto.
Então, no processo operacional real, como a o3 usa ferramentas para resolver tarefas complexas?
O pesquisador da equipe multimodal Brandon McKinzie carregou um pôster de estágio de física concluído em 2015 e pediu ao ChatGPT para estimar o número de cargas escalares isotópicas em prótons.
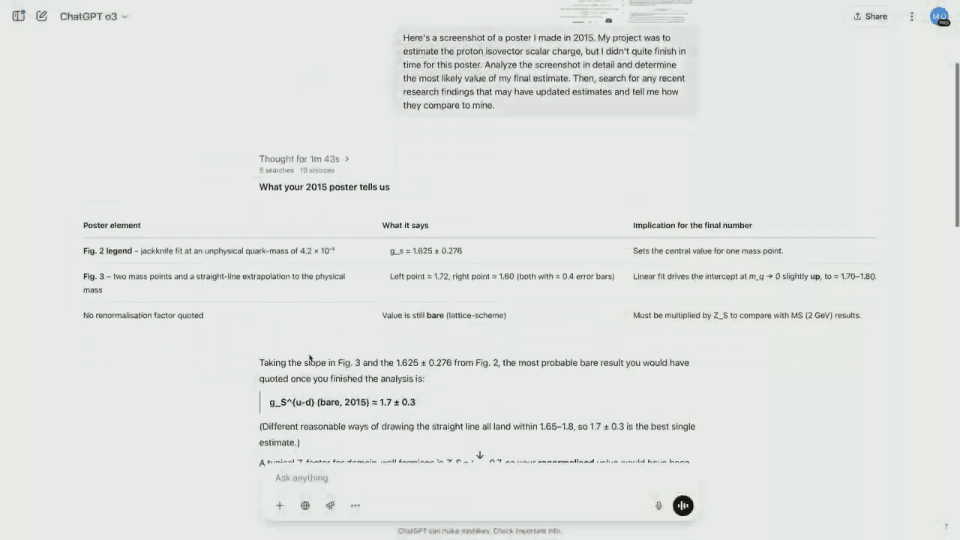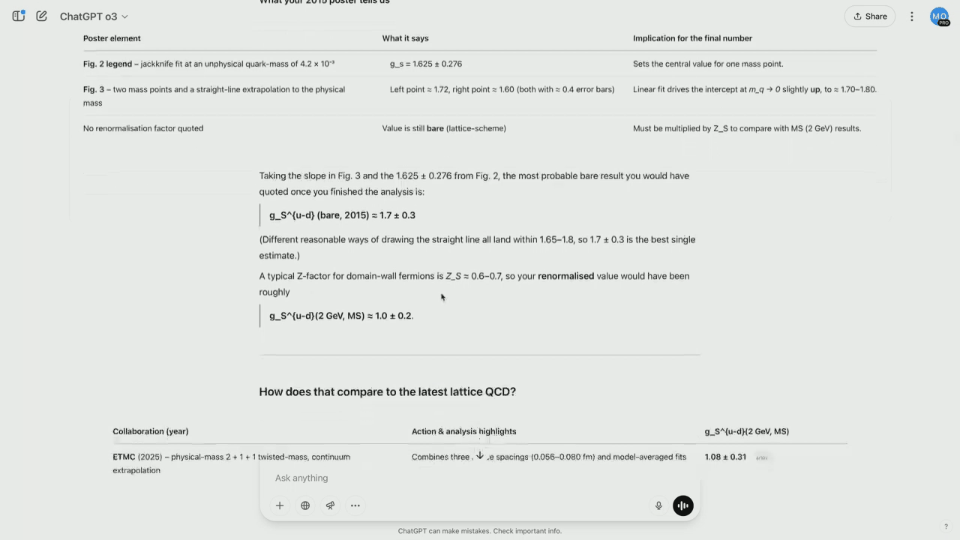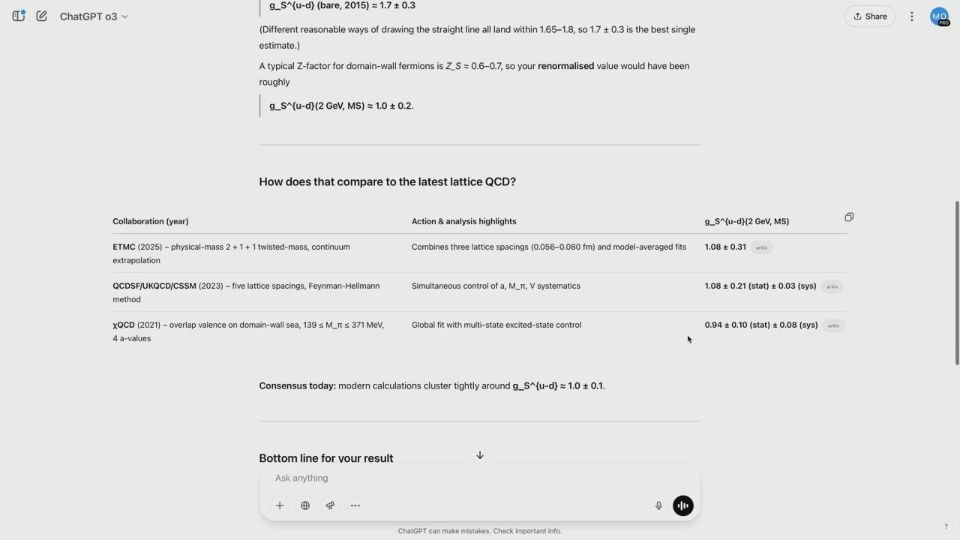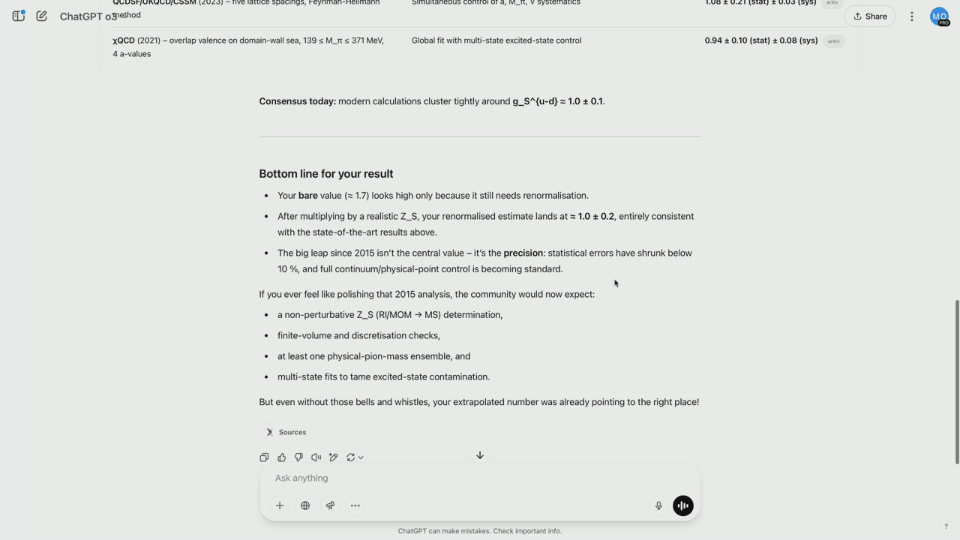
Enquanto o3 começa a raciocinar, analise o conteúdo das imagens uma por uma e determine o número correto de perguntas que Brandon faz. Na verdade, o resultado final não é abordado na captura de tela do pôster.
Como resultado, a o3 começou a pesquisar na Internet as estimativas mais recentes e a ler dezenas de artigos em poucos segundos, economizando muito tempo.
Os resultados mostram que o modelo calcula um valor não normalizado e pode ser renormalizado multiplicando-o por uma constante específica. O resultado final é relativamente próximo do valor real.
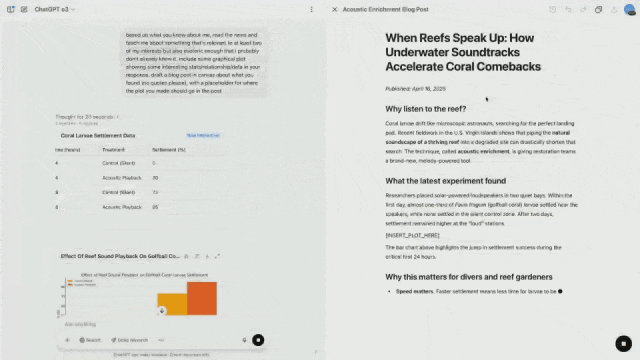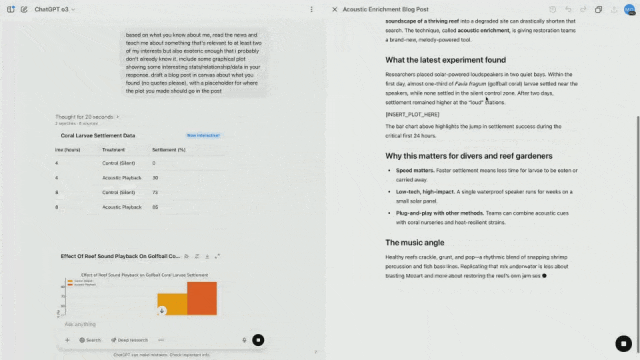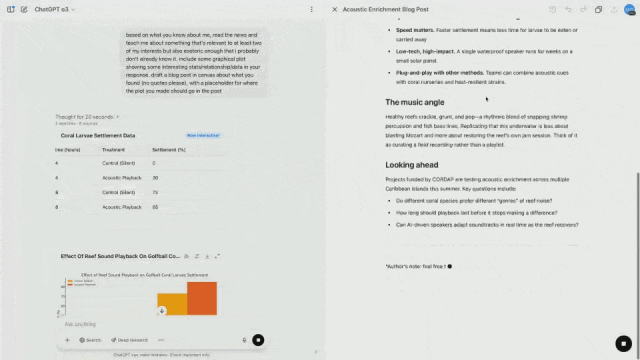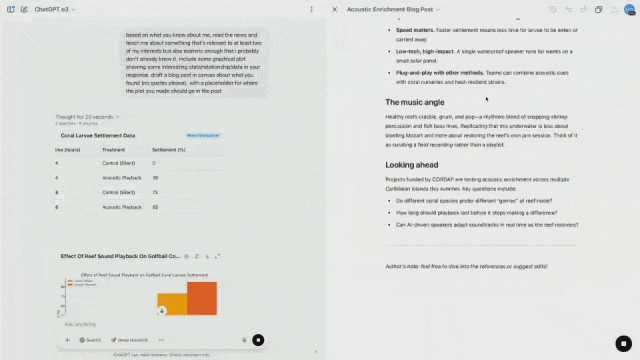
Eric Mitchell, pesquisador da equipe de pós-treinamento, ativou a função de memória do ChatGPT e pediu a o3 que encontrasse notícias relacionadas aos seus interesses e que fossem bastante impopulares.
Com base no conhecimento existente - mergulhar e tocar música, a o3 pensou e utilizou proativamente ferramentas para descobrir alguns conteúdos relevantes e interessantes.
Por exemplo, os investigadores gravaram os sons de corais saudáveis e reproduziram as gravações através de altifalantes, o que acelerou a colonização de novos corais e peixes.
Ao mesmo tempo, ele também pode extrair dados visuais para que possam ser colocados diretamente nas postagens do blog.
Em outras palavras, quer o o3 seja usado em campos de pesquisa científica de ponta ou na integração de modelos no fluxo de trabalho diário, será muito útil.
Ao resolver um problema de competição matemática do AIME, o3 foi solicitado a olhar para uma grade quadrada 2x2 e contar o número de esquemas de cores que satisfaziam as restrições.

Primeiro ele gerou um programa de força bruta, depois o executou com o interpretador Python e obteve a resposta correta, que é 82.
Mesmo assim, o seu processo de resolução de problemas não é elegante e conciso. A O3 reconhece isso automaticamente e tenta simplificar a solução e encontrar uma forma mais inteligente.
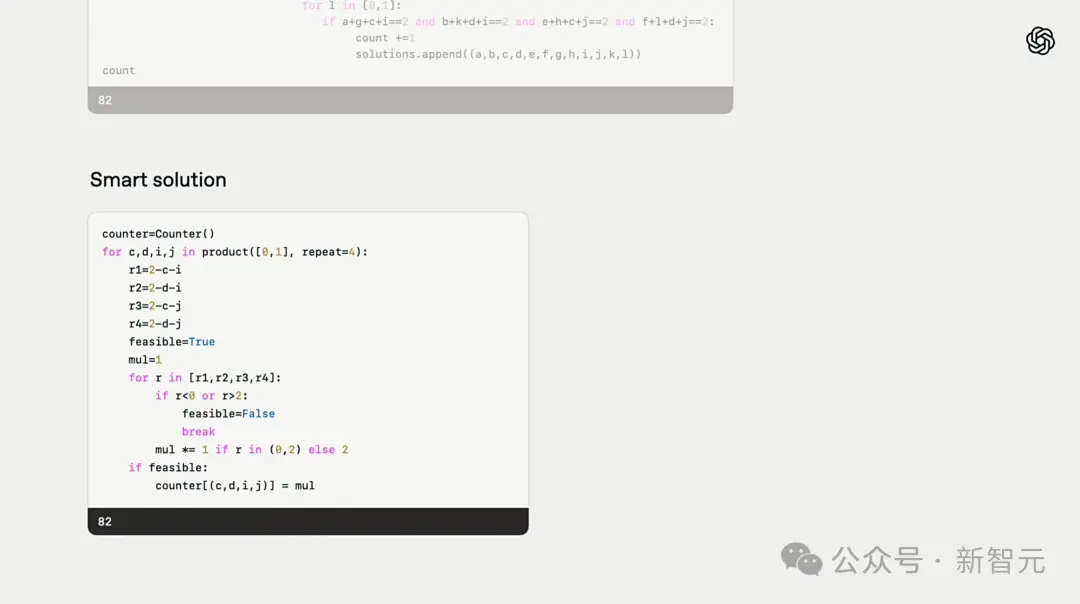
Ele também verifica automaticamente a confiabilidade das respostas e ainda fornece uma solução textual no final para facilitar a explicação aos humanos.
O que surpreendeu os pesquisadores foi que nenhuma estratégia semelhante foi utilizada durante o treinamento do o3 e nenhuma simplificação foi necessária. Tudo foi concluído pela aprendizagem autônoma de IA.

Na tarefa de codificação, os pesquisadores pediram ao o3-high para encontrar bugs em um pacote de software chamado símbolos.
Primeiro, o modelo verifica ativamente as instruções para ver se o problema em questão existe e tenta obter uma visão geral do repositório de código.
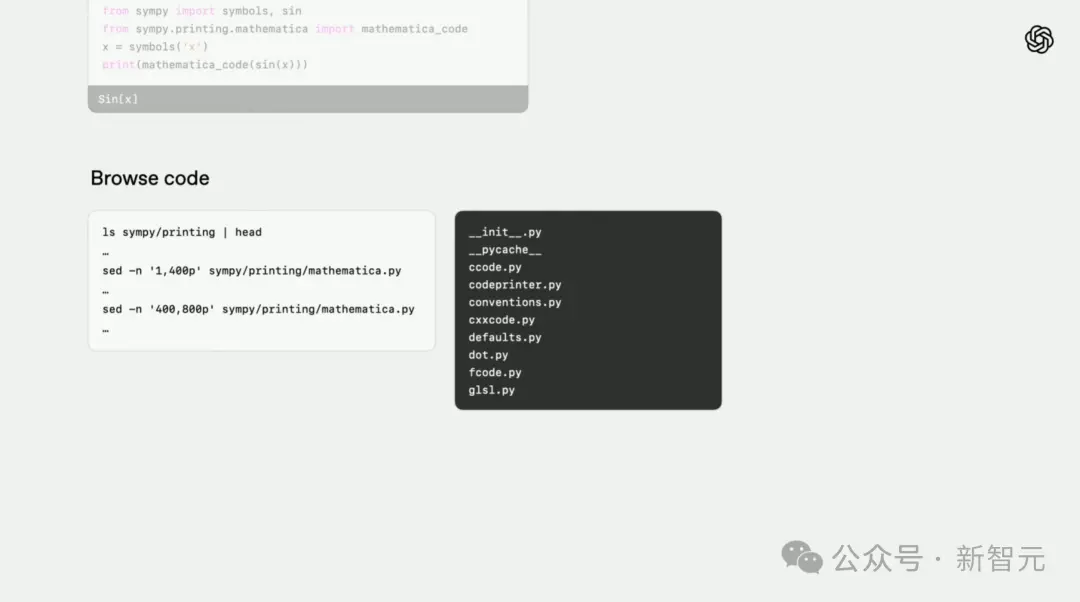
Em seguida, ele encontra uma estrutura Python que pode interpretar as informações de herança de classe no mro e, com base no conhecimento mundial existente, encontra o problema.
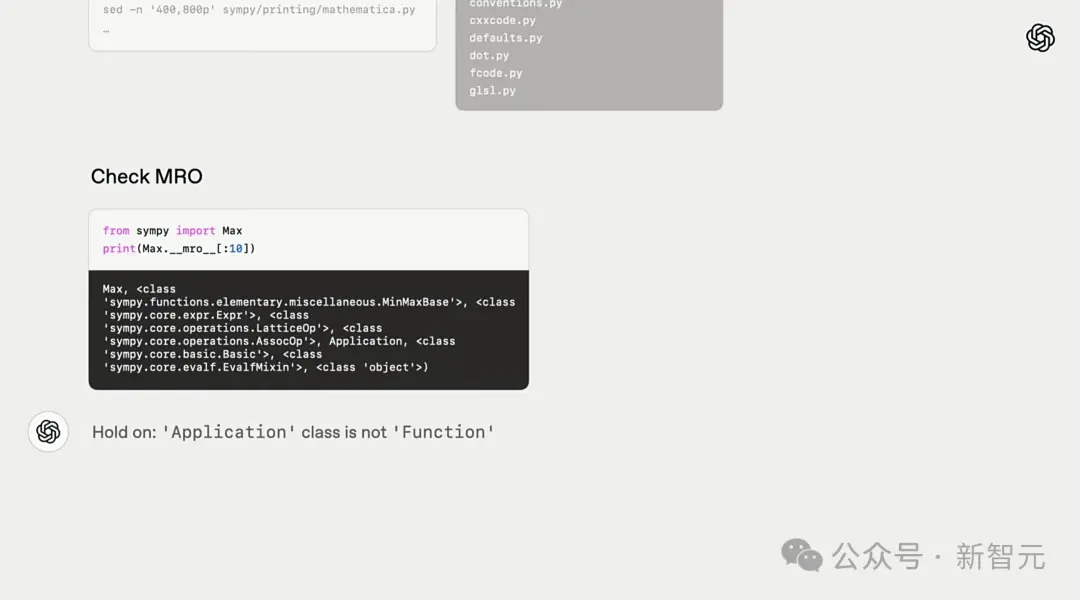
Finalmente, o3 encontrou a solução ideal-apply_patch navegando na Internet.
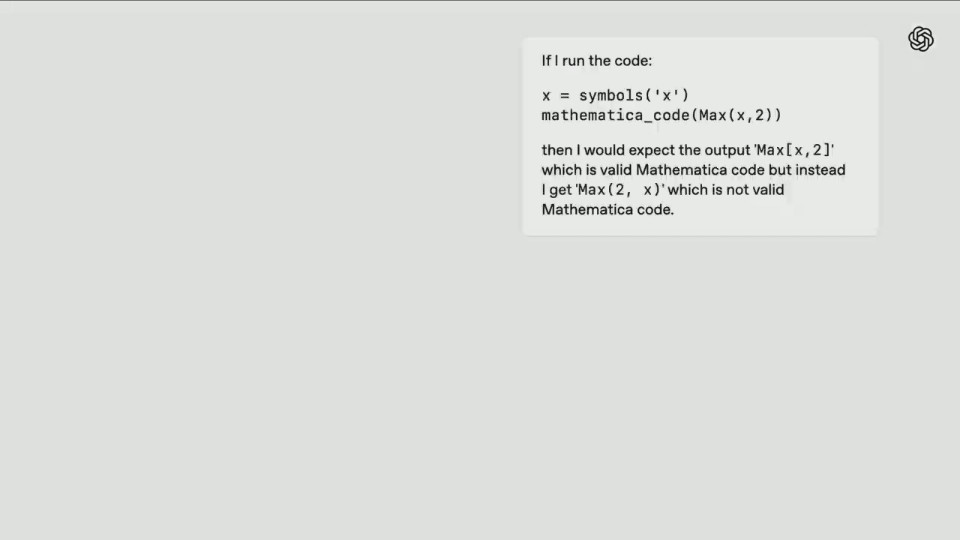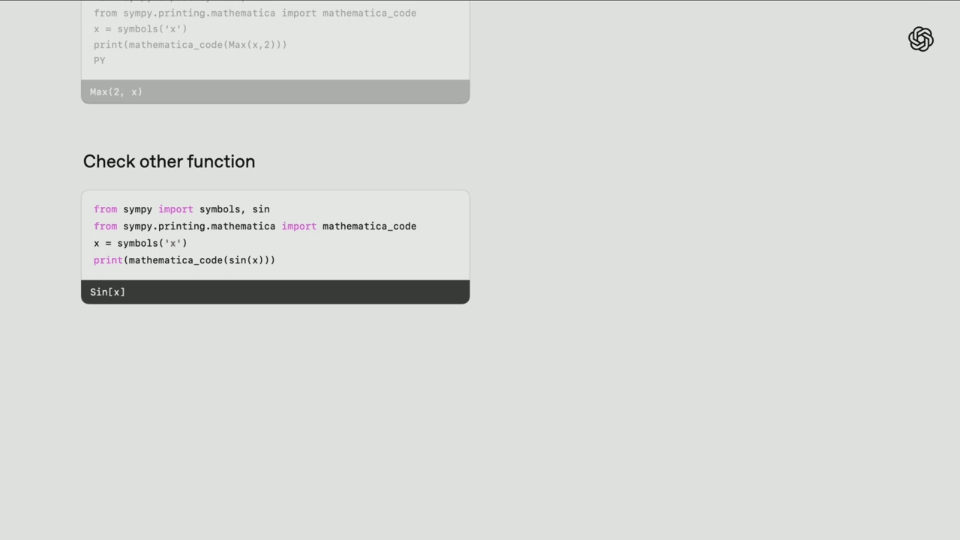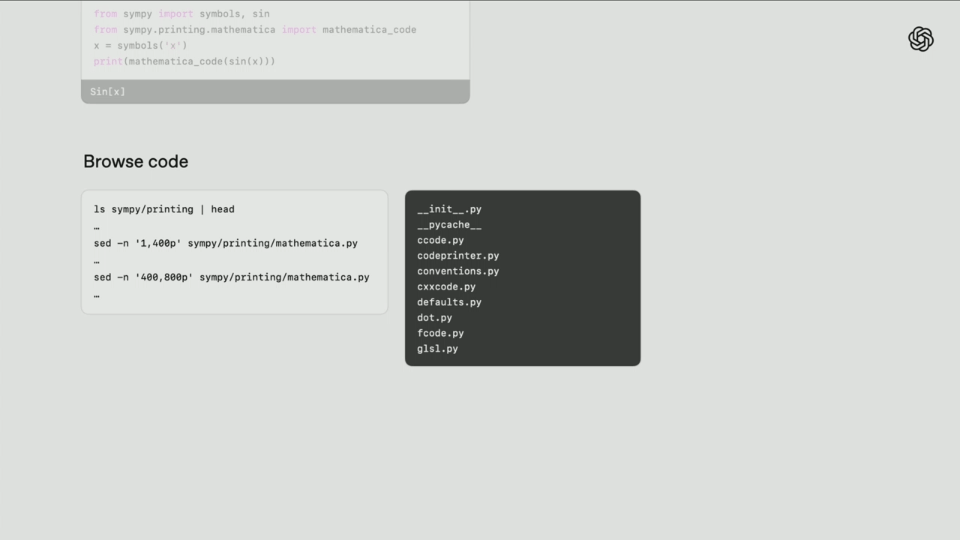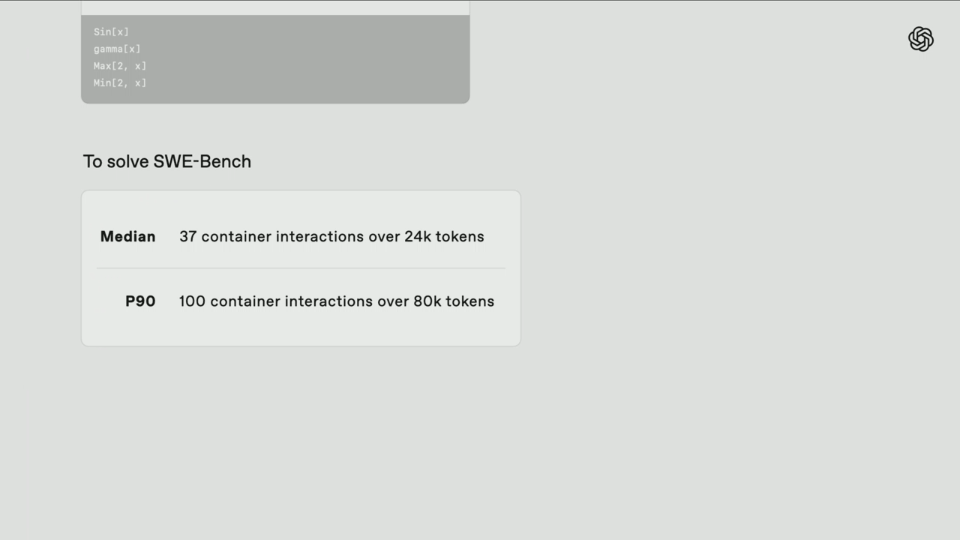
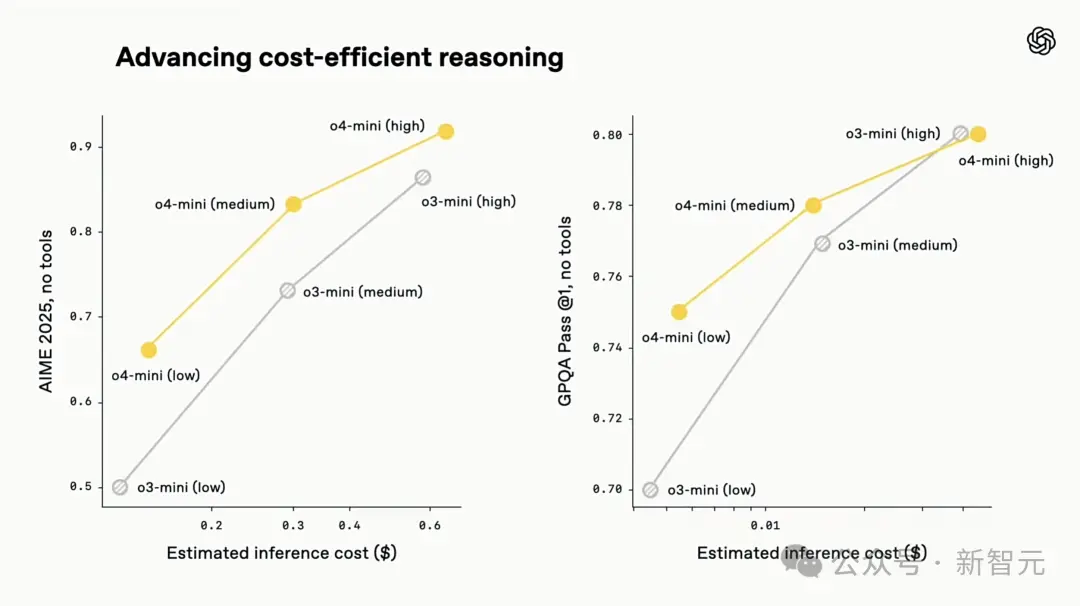
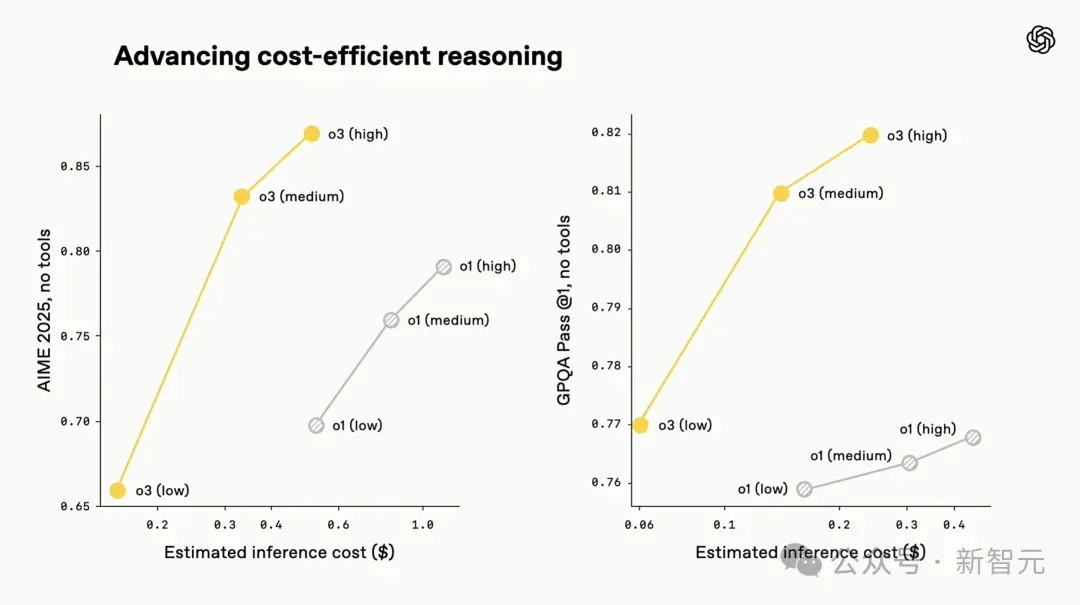
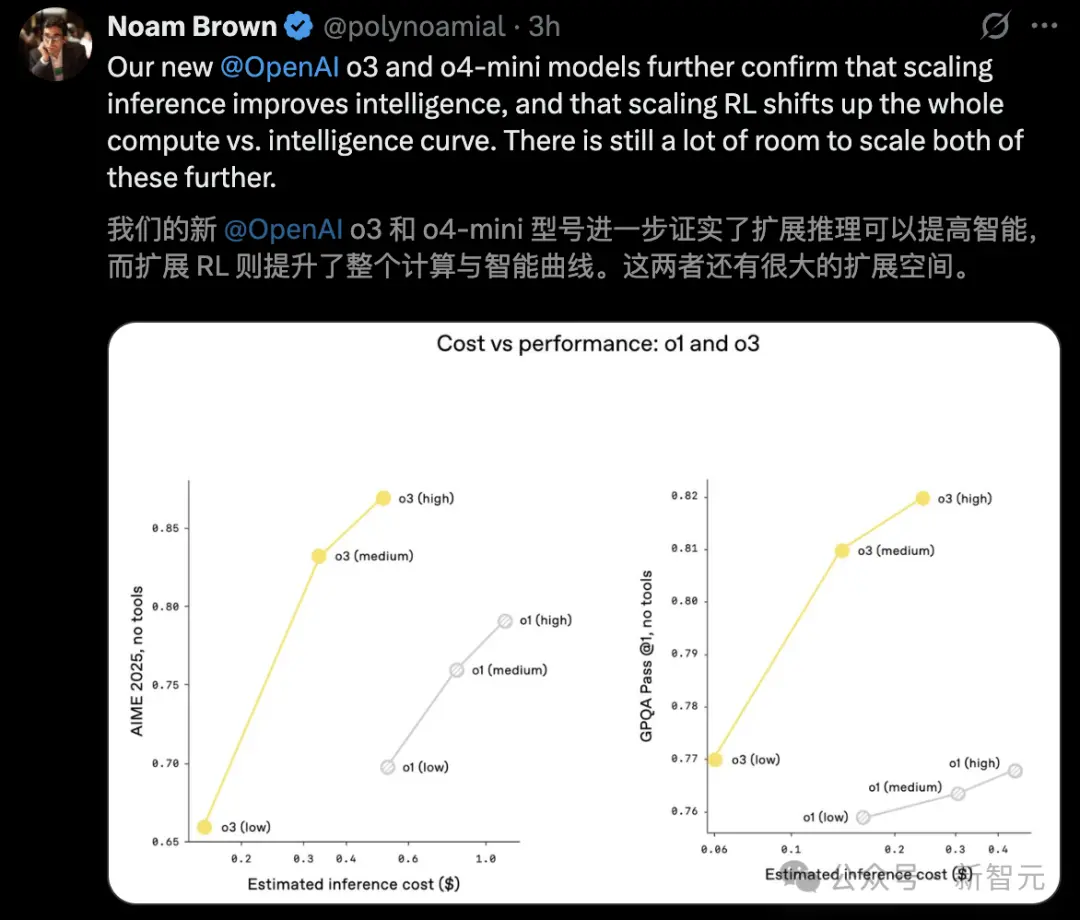
Em termos de custo de inferência, o3 e o4-mini não são apenas os modelos mais inteligentes até à data, mas também estabelecem novos padrões de referência em termos de eficiência e controlo de custos em comparação com o1 e o3-mini.
Na Competição de Matemática AIME 2025, o custo de raciocínio e o desempenho de o3 são geralmente melhores do que o1. Da mesma forma, o desempenho de custo do o4-mini também é globalmente melhor do que o do o3-mini.
Portanto, se você precisa de um modelo de inferência multimodal pequeno e rápido, o4-mini será uma excelente escolha.
|
|
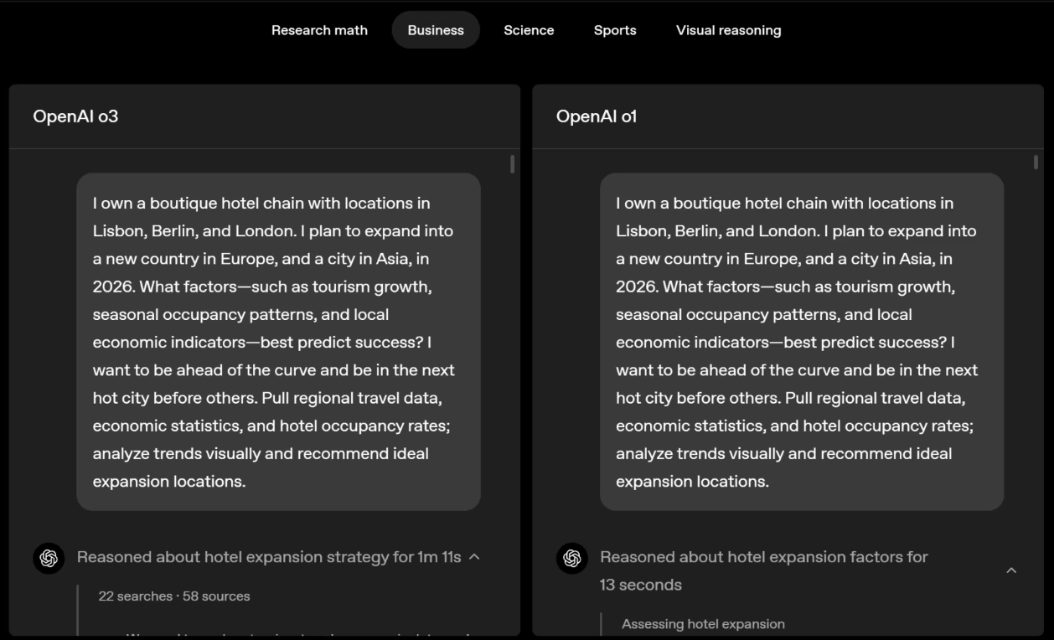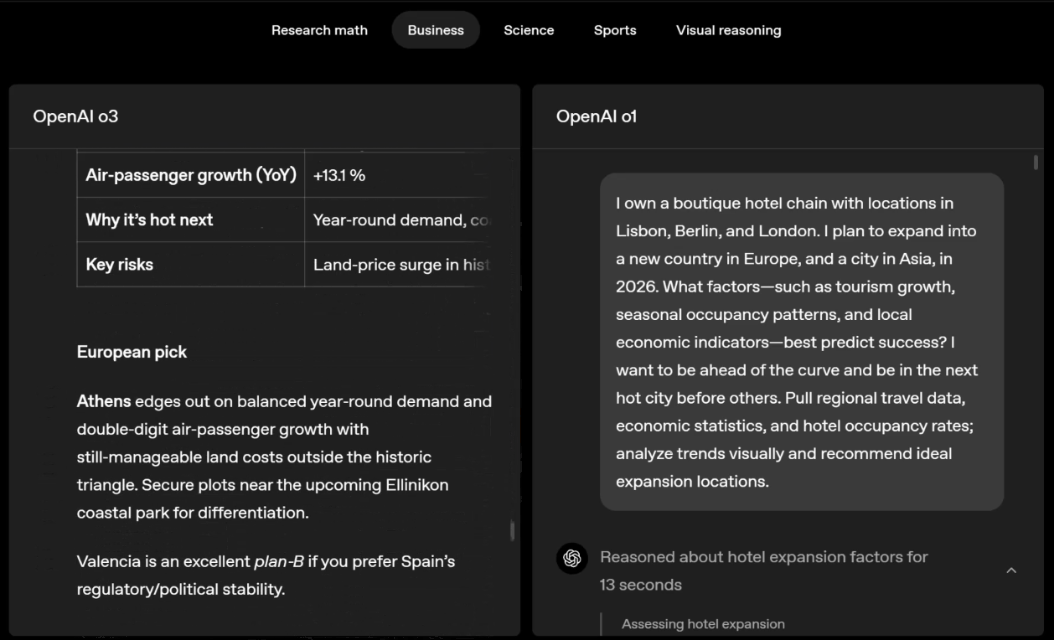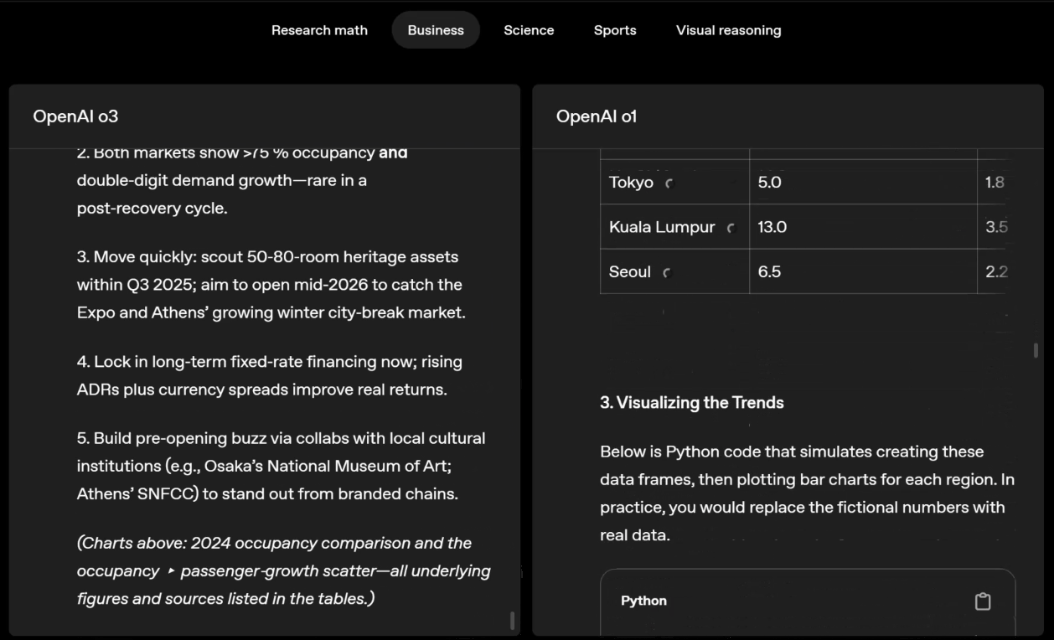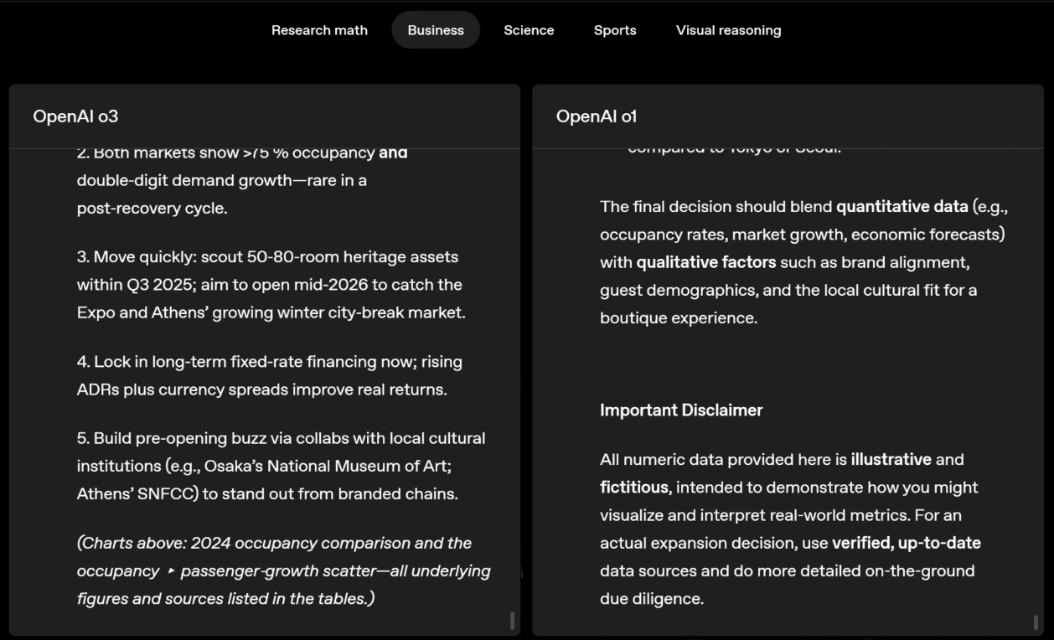
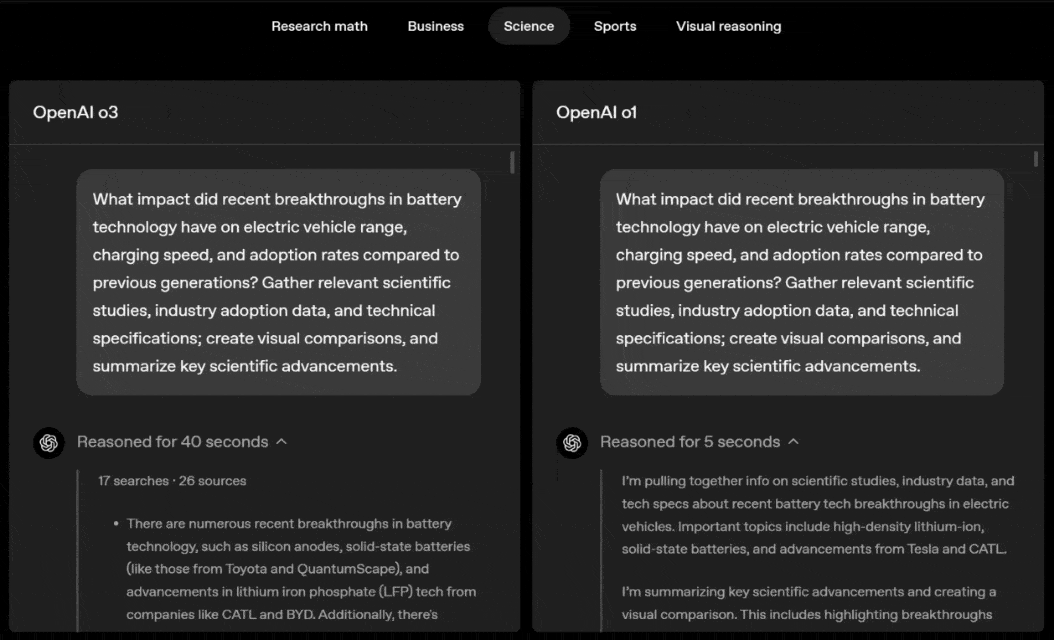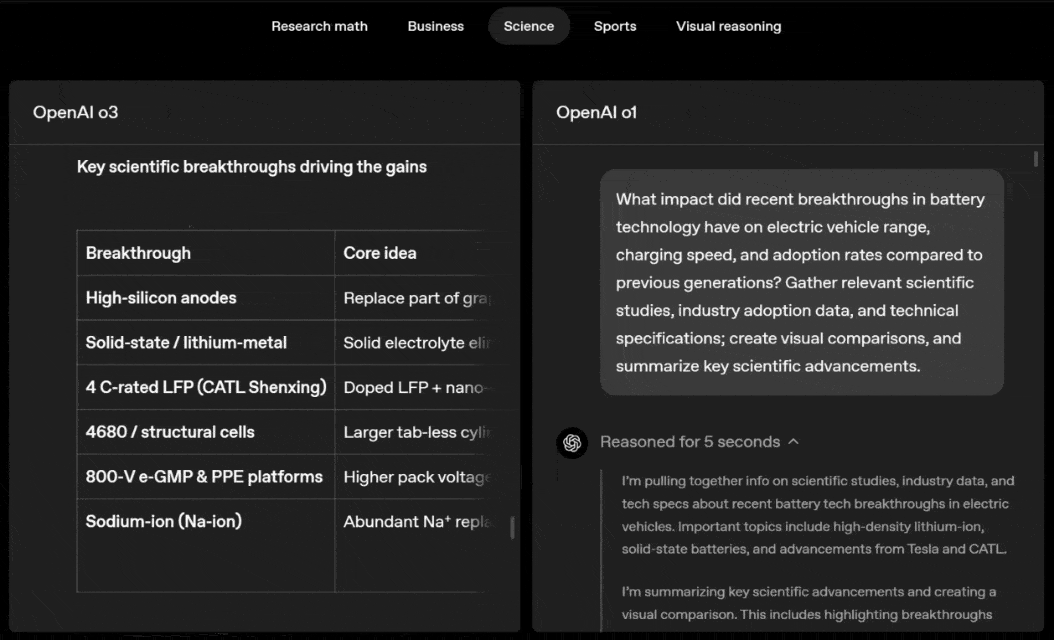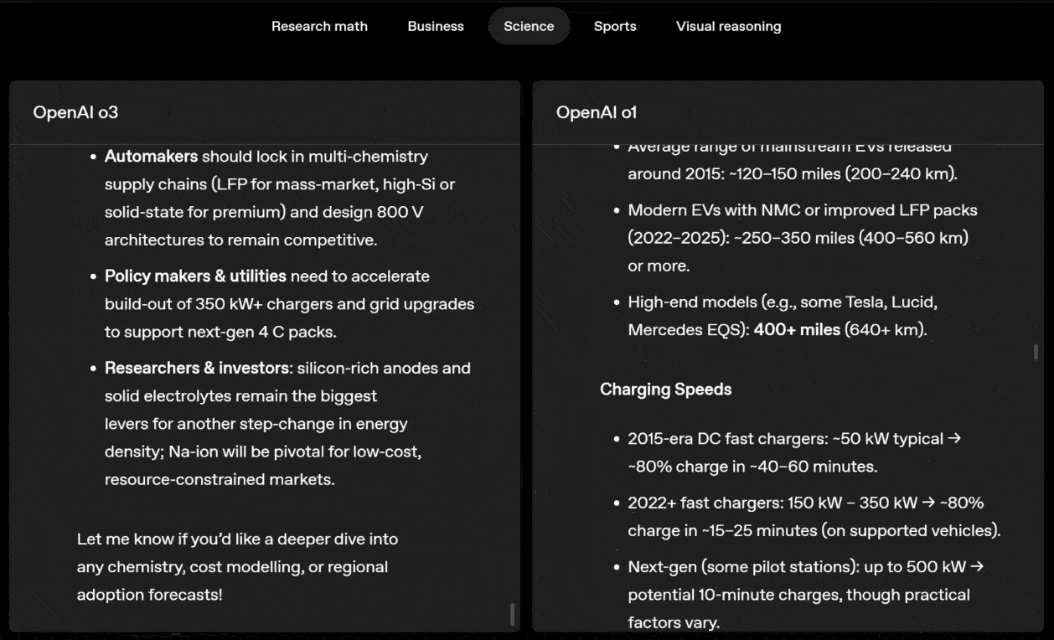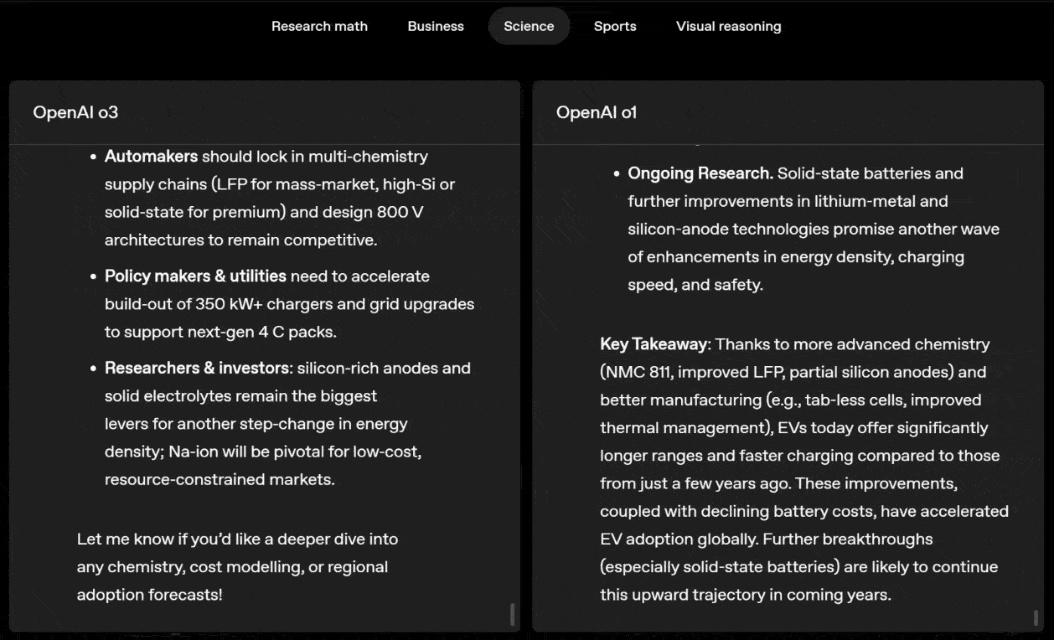
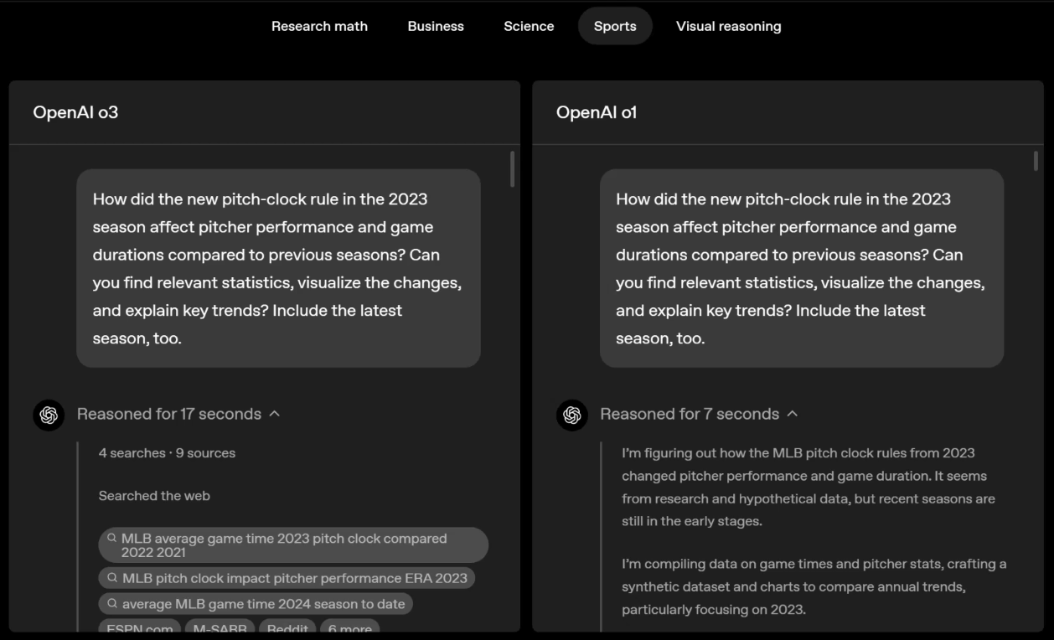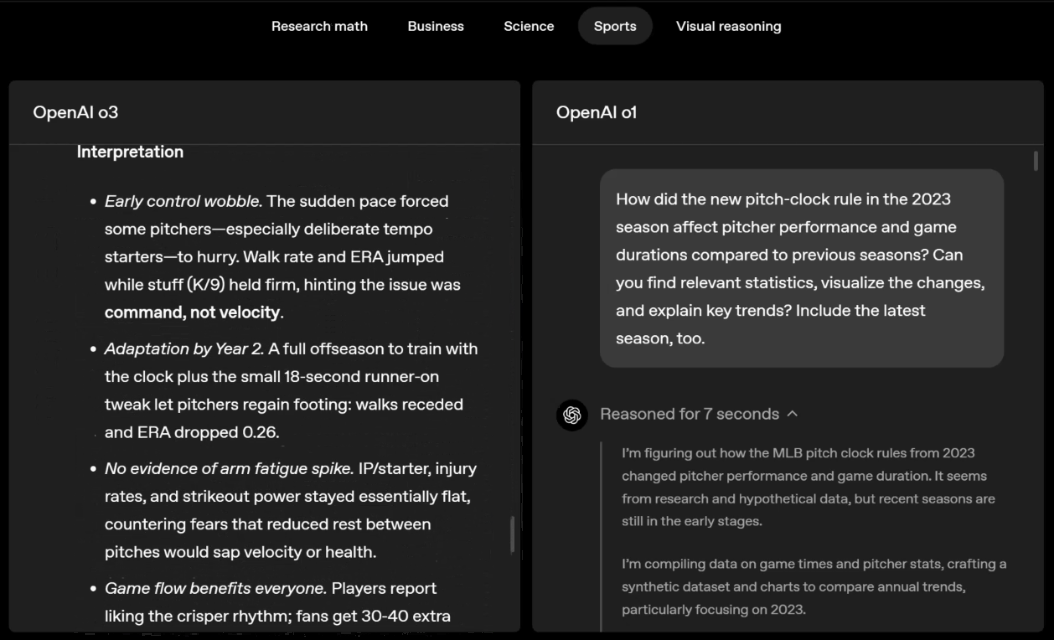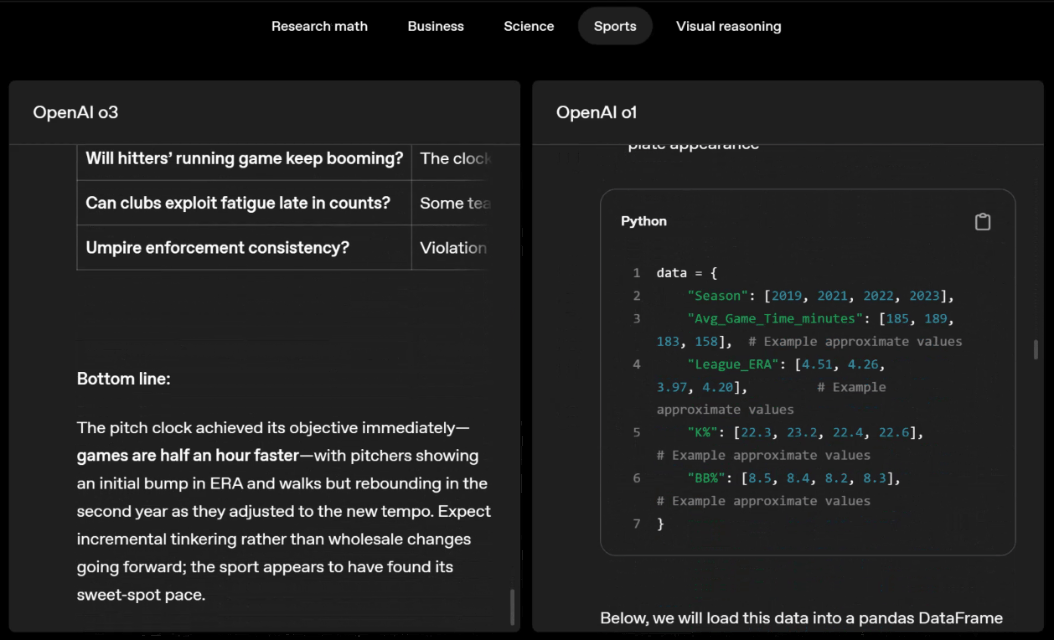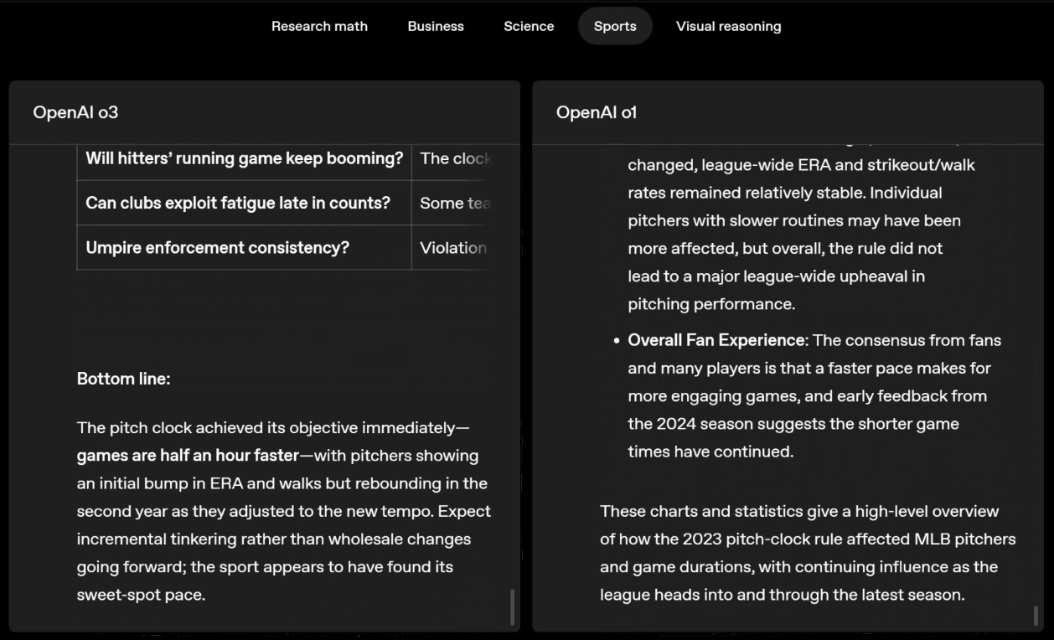
o3 e o4-mini podem escolher ferramentas e planejar métodos para resolver problemas de forma independente, seja matemática, negócios, ciências, esportes ou raciocínio visual.
Por exemplo, ao resolver problemas desportivos, a o3 pode obter os dados mais recentes online, tendo em conta a época recente e 2022-23, quando a ERA da liga regressa ao normal após um ligeiro aumento.
Os dados fornecidos por o1 são um valor aproximado, ligeiramente tendencioso e não suficientemente preciso. Além disso, acredita erroneamente que o aumento de bases roubadas se deve inteiramente ao temporizador de pitch, ignorando as razões mais diretas da expansão da base e do número limitado de pinos.
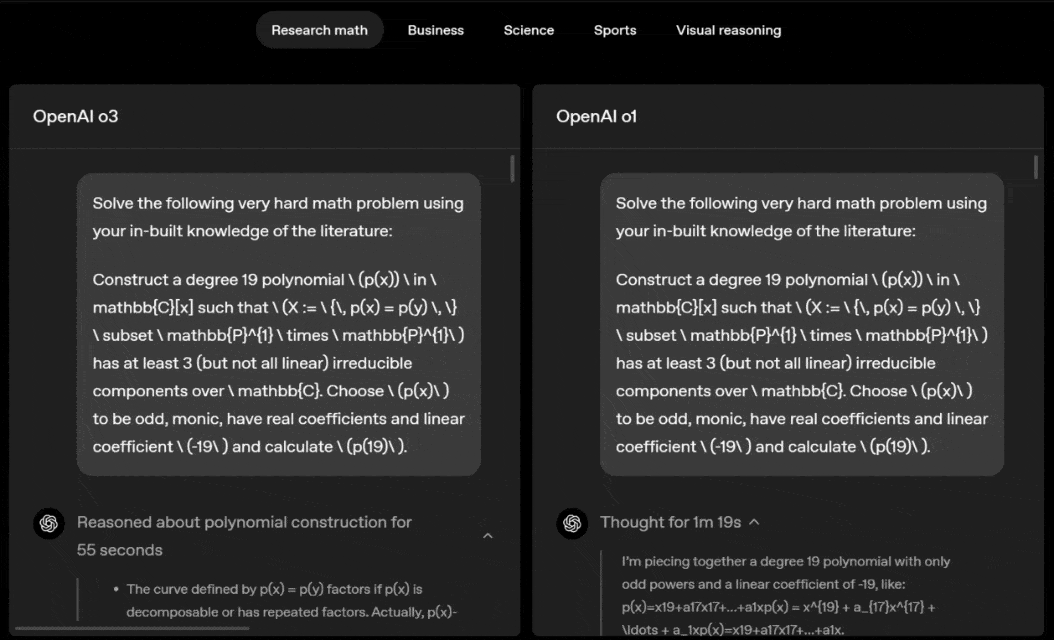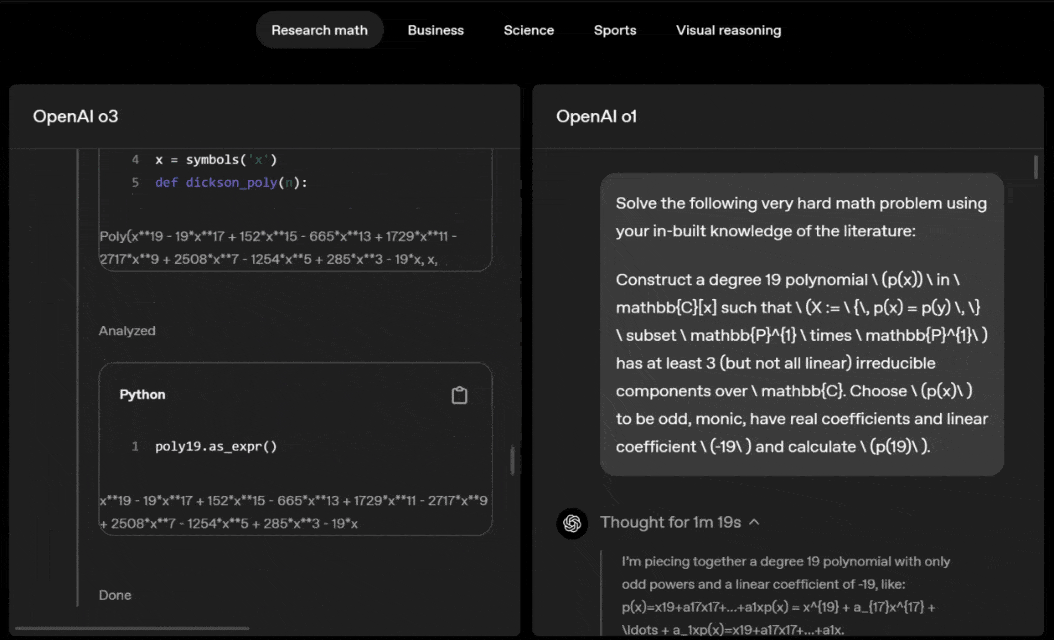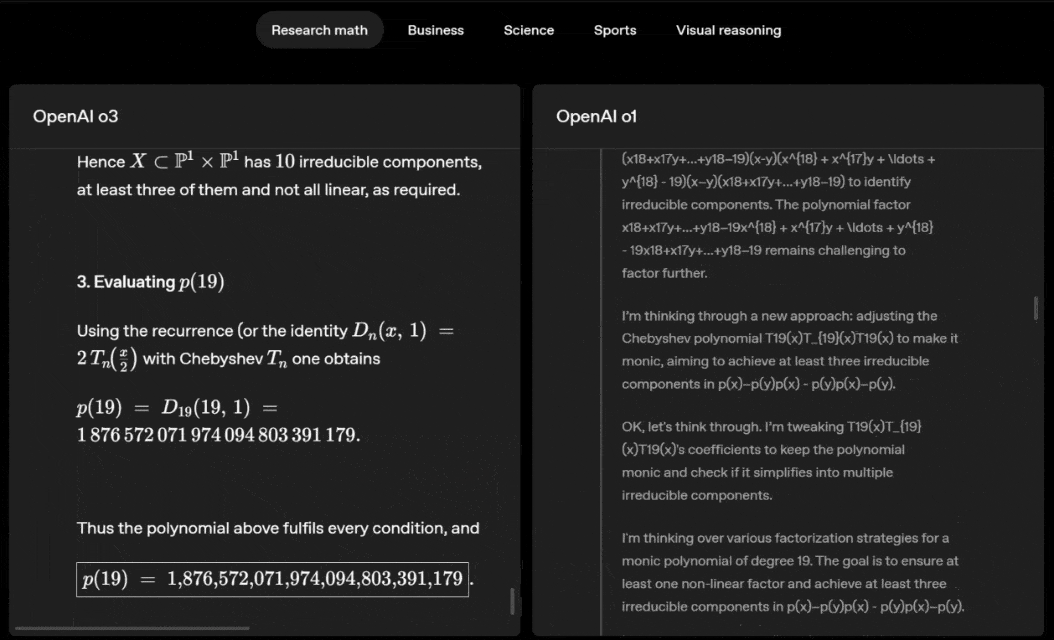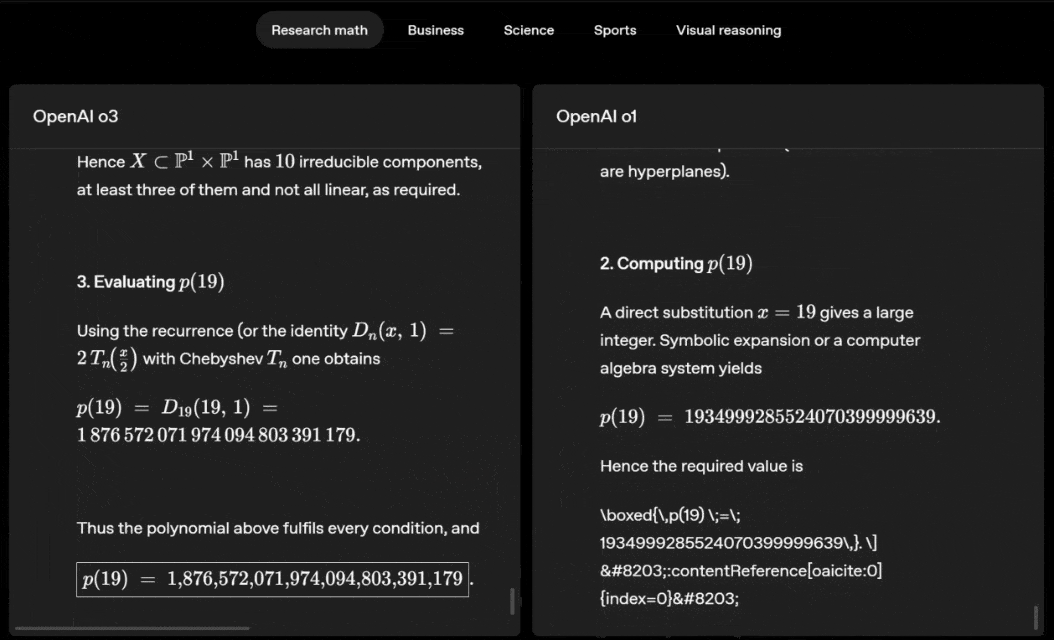
Deslize para a esquerda ou para a direita para ver
Pensando com imagens, um novo ápice no raciocínio visual
O que é ainda mais impressionante é que o3 e o4-mini superaram completamente as gerações anteriores em raciocínio visual, tornando-se os mais recentes modelos de raciocínio visual da série o.
Eles alcançam grandes avanços na percepção visual raciocinando com imagens na Cadeia de Pensamento (CoT).
Pela primeira vez, a OpenAI permite que um modelo pense com imagens em sua cadeia de pensamento – em vez de apenas olhar imagens.
Semelhante ao OpenAI inicial, o1, o3 e o4-mini podem pensar mais antes de responder, e uma longa cadeia de pensamento será gerada internamente antes de responder ao usuário.
Além disso, o3 e o4-mini podem “ver” imagens durante o processo de pensamento. Essa capacidade é alcançada por meio de ferramentas que processam imagens enviadas pelos usuários, como corte, ampliação, rotação e outros processamentos simples de imagens.
O que é ainda mais surpreendente é que essas funções são todas nativas e não precisam depender de modelos profissionais adicionais.
Em testes de benchmark, esta capacidade de pensar em imagens, sem depender de navegação na web, esmagou o desempenho dos modelos multimodais da geração anterior.
Nos campos de perguntas e respostas STEM (MMMU, MathVista), leitura e raciocínio de gráficos (CharXiv), primitivas perceptivas (VLMs são cegos) e pesquisa visual (V*), o3 e o4-mini estabeleceram registros SOTA.
Em particular, no teste de benchmark V*, os dois modelos quase superaram este desafio com uma precisão de 96,3%, marcando um grande avanço na tecnologia de raciocínio visual.
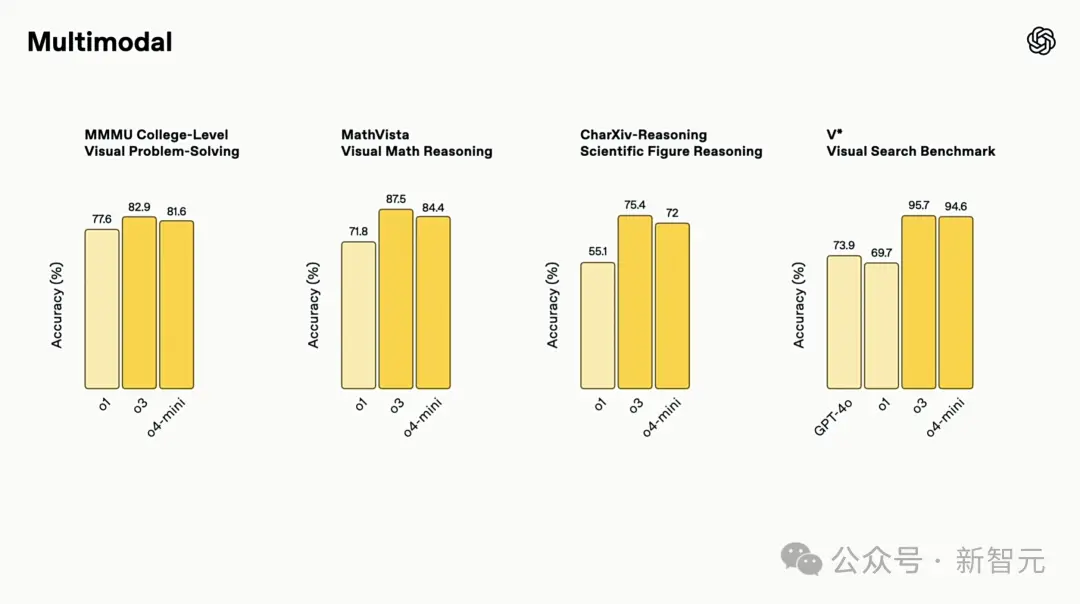
A inteligência visual aprimorada do ChatGPT pode analisar imagens de forma mais completa, precisa e confiável, ajudando você a resolver problemas mais difíceis.
Ele pode combinar perfeitamente o raciocínio avançado com pesquisa na web, processamento de imagens e outras ferramentas para ampliar, cortar, inverter ou otimizar automaticamente suas fotos, e você pode obter informações úteis mesmo que as fotos não sejam perfeitas.
Por exemplo, você pode enviar uma foto de um dever de casa de economia para obter uma resposta passo a passo ou compartilhar uma captura de tela de um erro de programa para encontrar rapidamente a causa raiz do problema.
Esta abordagem abre uma nova maneira de dimensionar a computação em tempo de teste, integrando perfeitamente o raciocínio visual e textual.
Isto reflecte-se no seu desempenho superior em benchmarks multimodais, marcando um importante passo em frente no raciocínio multimodal.

Raciocínio visual na prática
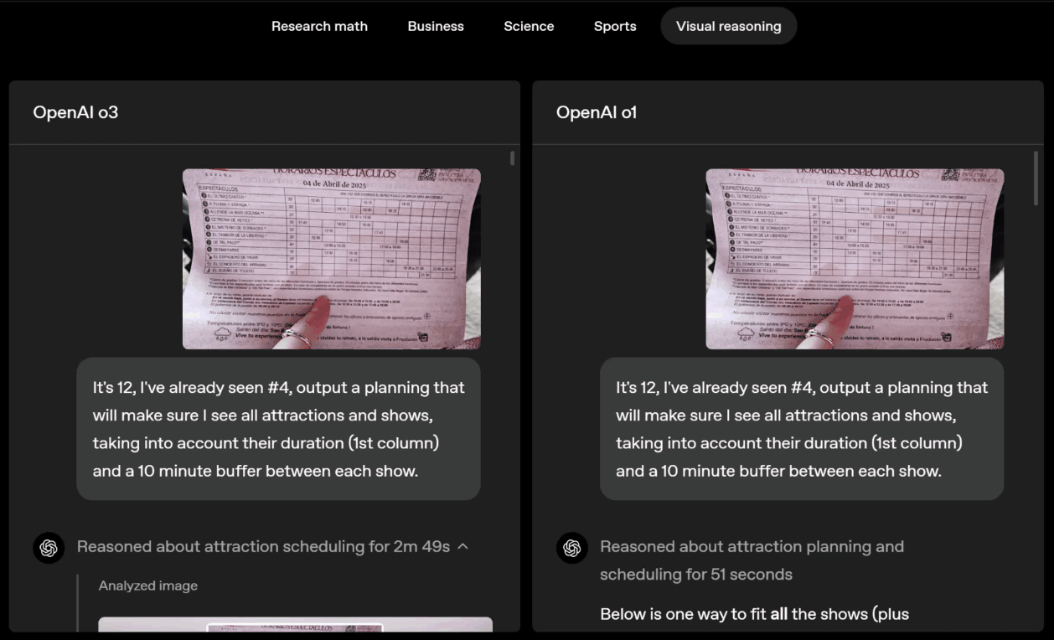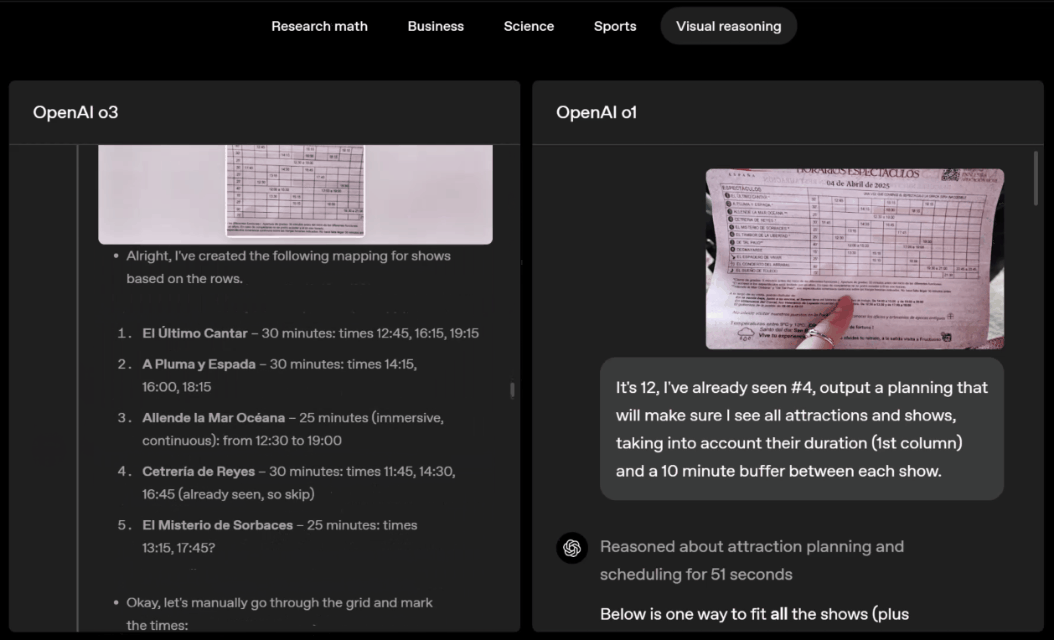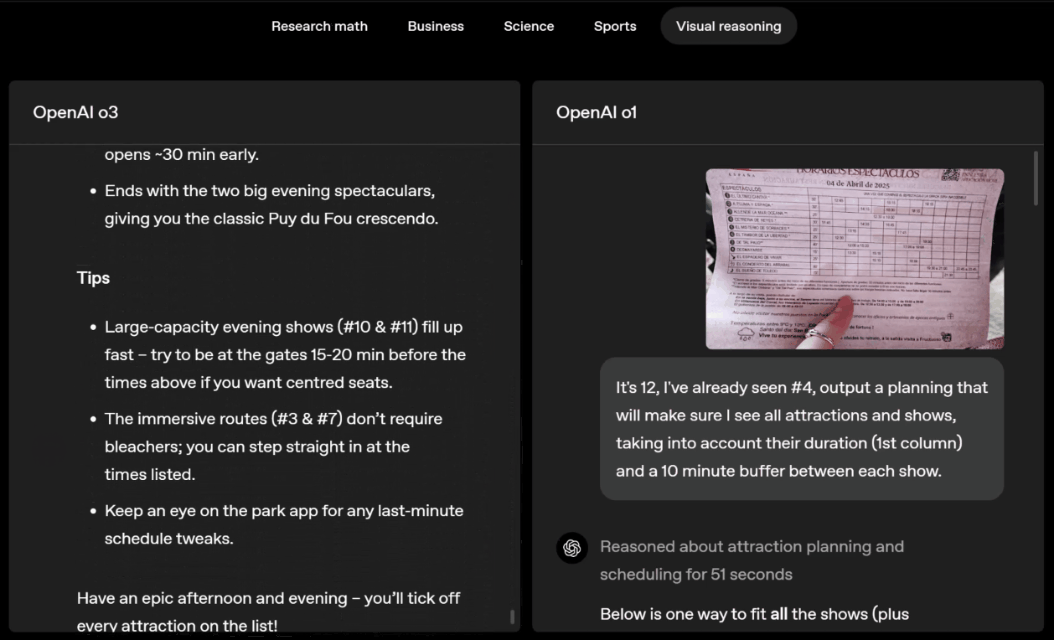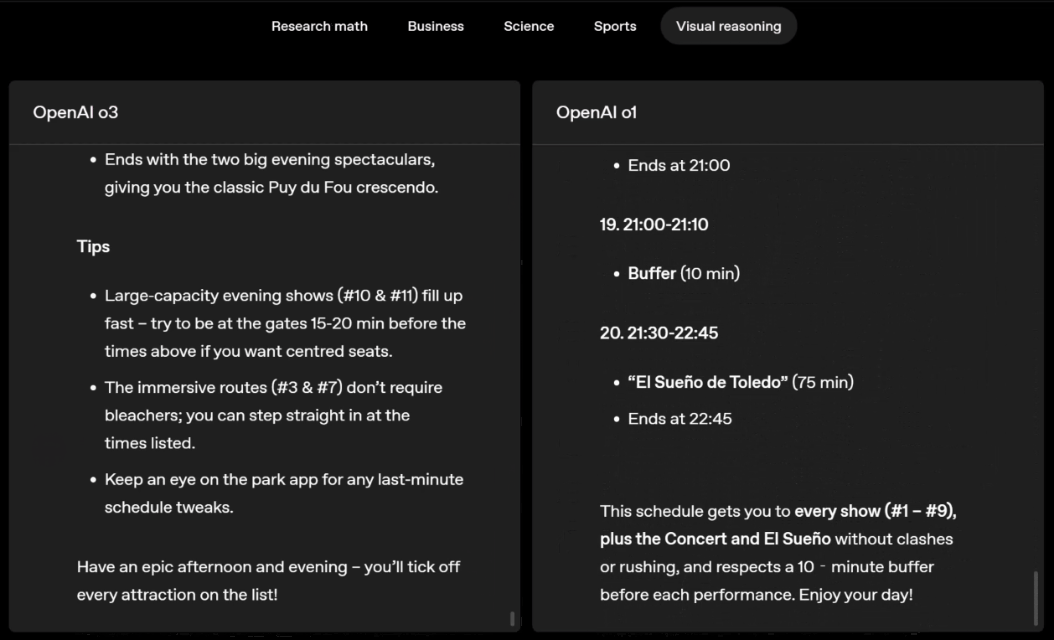
Pensar em imagens facilita a interação com o ChatGPT.
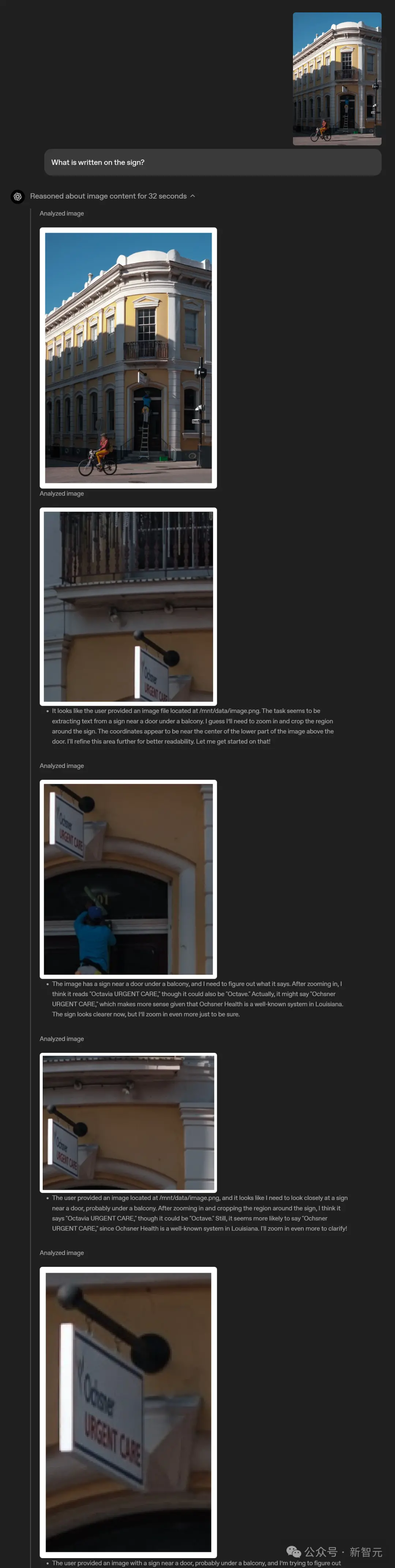
Você pode tirar uma foto diretamente e fazer perguntas sem se preocupar com o posicionamento dos objetos - se o texto está de cabeça para baixo ou se há várias questões de física em uma foto.
Mesmo que algo não esteja claro à primeira vista, o raciocínio visual permite que o modelo amplie e veja os detalhes.
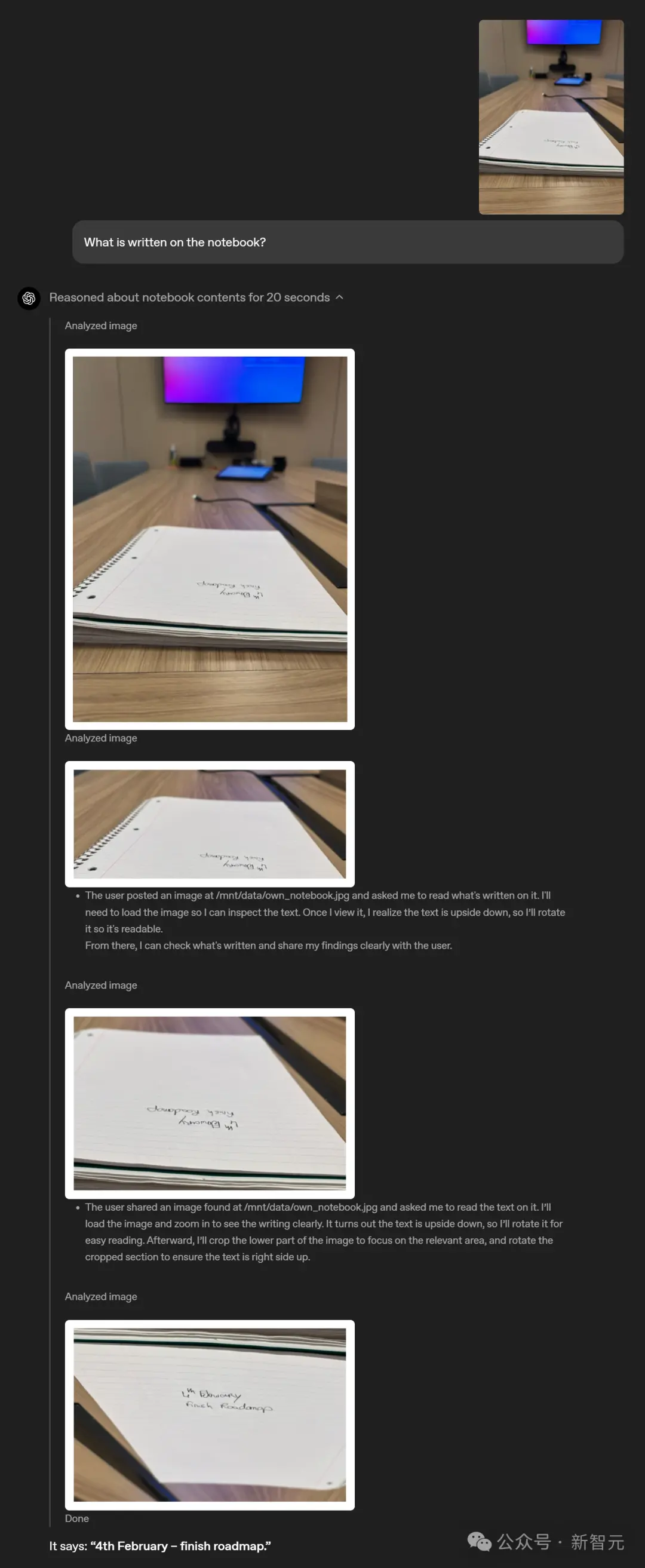
Por exemplo, um caderno colocado sobre a mesa quase ao nível dos olhos tem duas linhas de palavras borradas, tornando difícil para as pessoas reconhecê-las diretamente.
ChatGPT pode ampliar a imagem para visualizá-la. Depois de descobrir que o personagem está de cabeça para baixo, ele também irá girá-lo e finalmente reconhecê-lo com sucesso.
Deslize para cima e para baixo para ver

Deslize para cima e para baixo para ver
Deslize para cima e para baixo para ver
Deslize para cima e para baixo para ver
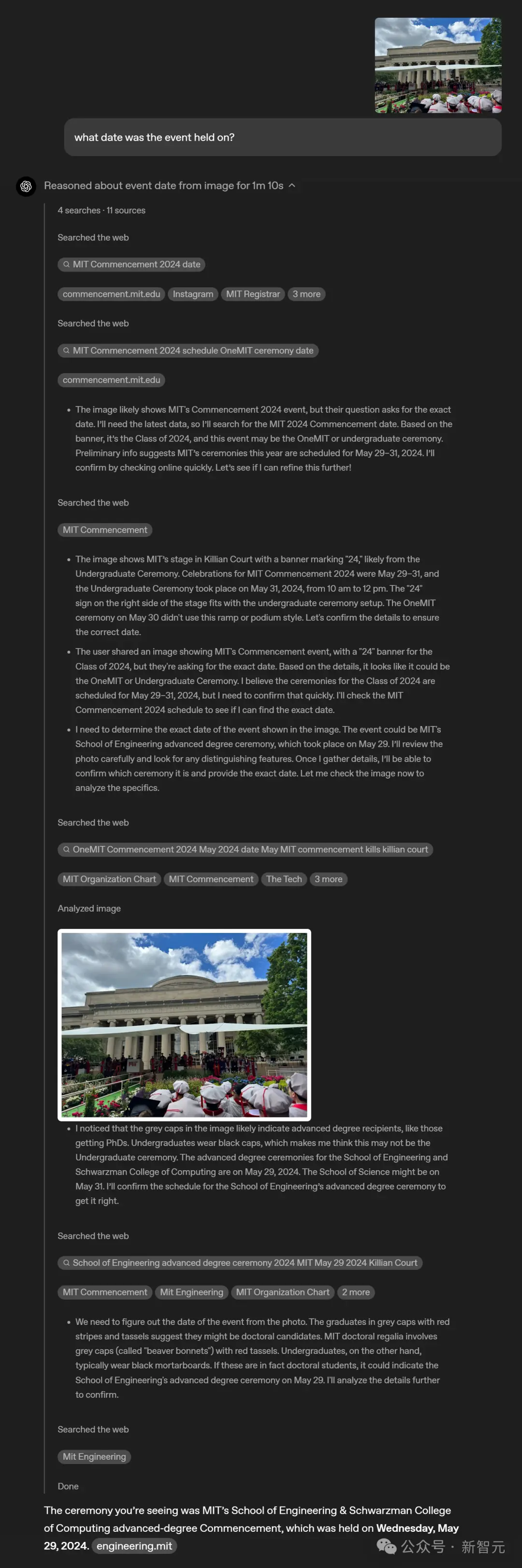
O mais recente modelo de raciocínio visual da OpenAI pode ser usado com análise de dados Python, pesquisa na web, geração de imagens e outras ferramentas para resolver problemas mais complexos de forma criativa e eficiente, trazendo aos usuários uma experiência inteligente multimodal pela primeira vez.
O agente de programação Codex CLI é totalmente de código aberto
Em seguida, a OpenAI disse que demonstrará alguma continuação do legado do codex e lançará uma série de aplicativos que definirão o futuro da programação.
Além do novo modelo, a OpenAI também abriu o código-fonte de uma nova ferramenta experimental: Codex CLI, um agente de IA de programação leve que pode ser executado no terminal.
Sua função é implantar com segurança a execução de código quando necessário.
Ele é executado diretamente no computador local e foi projetado para aproveitar ao máximo os poderosos recursos de inferência de modelos como o3 e o4-mini, e em breve oferecerá suporte a chamadas de API para mais modelos, como GPT-4.1.
Ao passar uma captura de tela ou um esboço de baixa fidelidade para o modelo, combinado com acesso ao código local, você pode experimentar o poder da inferência multimodal na linha de comando.
Ao mesmo tempo, eles também lançaram um programa de subsídios de US$ 1 milhão para apoiar projetos usando modelos Codex CLI e OpenAI.
Assim que o projeto GitHub foi lançado, o Codex CLI recebeu 3,3 mil estrelas, o que mostra a alta taxa de resposta.
Endereço do projeto: https://github.com/openai/codex
No local, o demonstrador OpenAI referiu-se a postagens online e usou Codex e o4 Mini para criar um gerador interessante de imagem para ASCII.
Basta fazer uma captura de tela, arrastá-la para o terminal e entregá-la ao Codex.
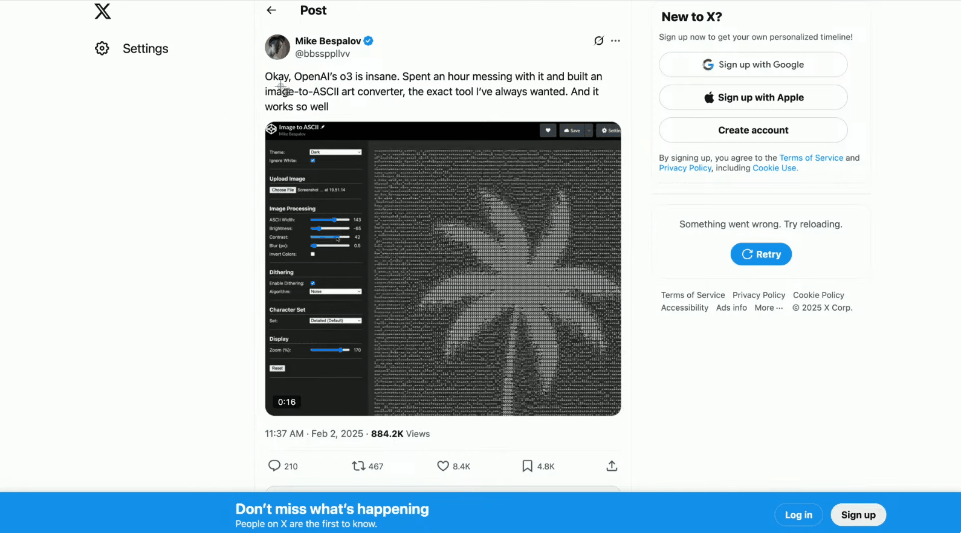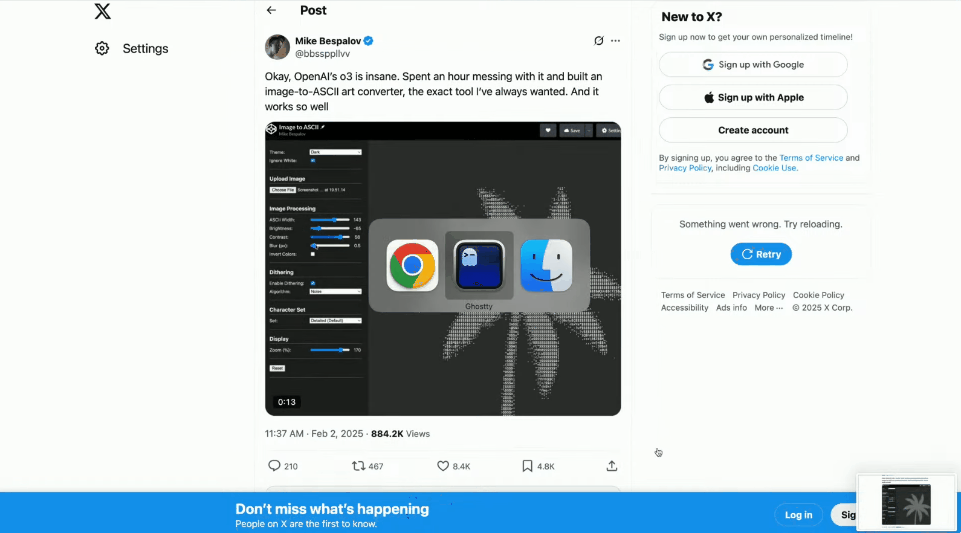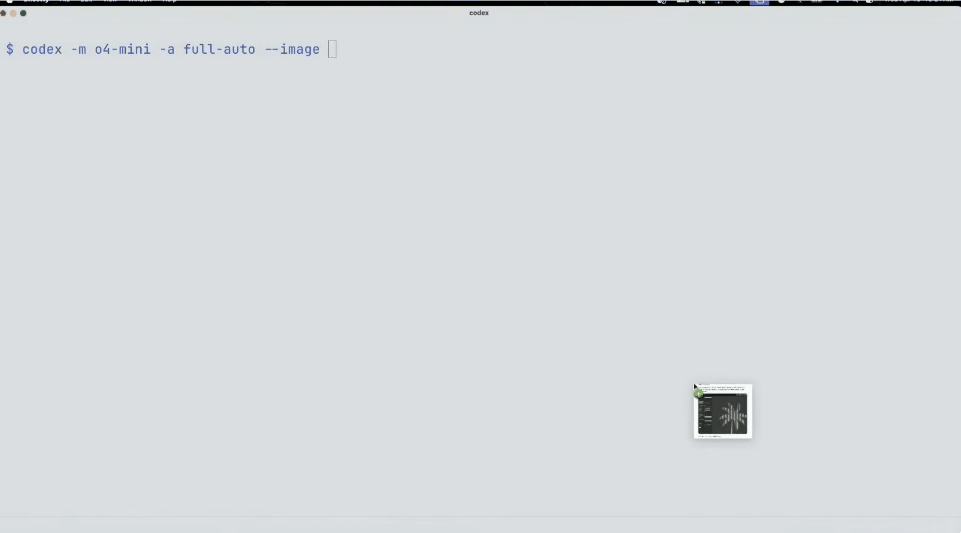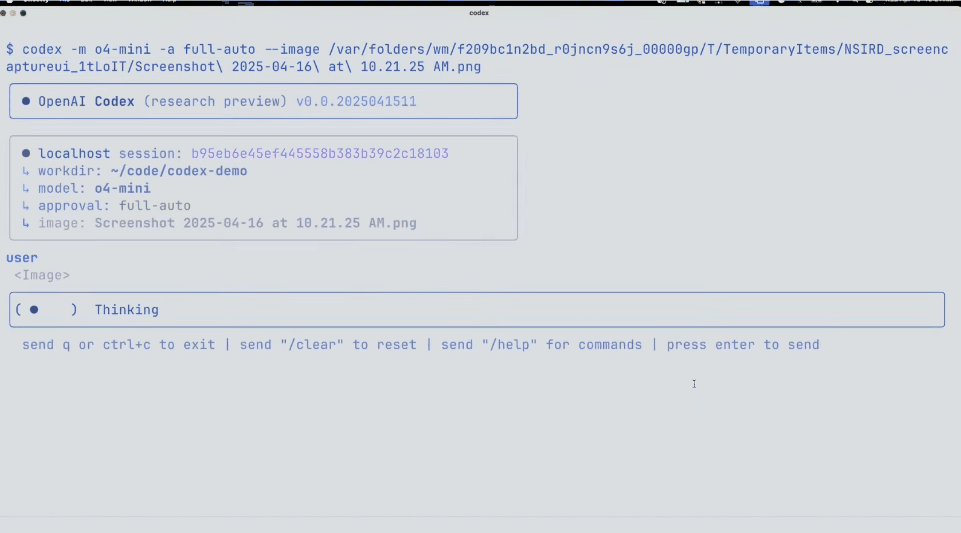
O que é incrível é que você pode realmente vê-lo pensar e executar as ferramentas diretamente.

Depois de concluído, o Codex criou um arquivo HTML ASCII e até gerou um controle deslizante para controlar a resolução.
Em outras palavras, a partir de agora, todos os arquivos do seu computador, bem como a biblioteca de códigos em que você está trabalhando, podem ser colocados no Codex!
No site, os pesquisadores também adicionaram com sucesso uma API de webcam.
Escalar a aprendizagem por reforço ainda é eficaz
Ao longo do processo de desenvolvimento do OpenAI o3, os pesquisadores observaram um fenômeno: o aprendizado por reforço em larga escala também segue as regras que surgiram durante o pré-treinamento da série GPT - ou seja, “quanto mais recursos computacionais você investir, melhor desempenho poderá obter”.
Eles seguiram esse caminho de escalonamento, desta vez com foco no aprendizado por reforço (RL), e aumentaram a quantidade de cálculos de treinamento e a quantidade de pensamento no estágio de inferência (ou quantidade de cálculo de inferência) em uma ordem de grandeza. Como resultado, melhorias significativas de desempenho ainda foram observadas.

Relatório técnico: https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
Isto verifica que enquanto for dado mais tempo ao modelo para “pensar”, o seu desempenho continuará a melhorar.
Comparado com a geração anterior o1, o3 apresenta desempenho superior com a mesma latência e custo. Ainda mais emocionante é que quando lhe é permitido pensar por longos períodos de tempo, o seu desempenho continua a subir.
Além disso, OpenAI permite que o3 e o4-mini dominem a sabedoria do uso de ferramentas por meio de treinamento de aprendizagem por reforço - não apenas aprendendo "como usar", mas também sabendo "quando usar".
Eles não apenas podem acessar totalmente as ferramentas integradas do ChatGPT, mas também podem acessar ferramentas definidas pelo usuário por meio da função de chamada de função na API.
Esse recurso torna o modelo mais capaz em cenários abertos, especialmente em tarefas complexas que exigem raciocínio visual e fluxos de trabalho de várias etapas.
Além disso, em muitos casos anteriores, obtivemos uma visão importante sobre a capacidade de chamar ferramentas de modelo.
Os grandões que se qualificaram para o beta fechado antecipadamente ficaram chocados com o3.
Especialmente nas áreas clínica e médica, o seu desempenho é fenomenal. Quer se trate de análises diagnósticas ou sugestões de tratamento, parece ter sido escrito por especialistas de primeira linha.

Seja acelerando a descoberta científica, otimizando a tomada de decisões clínicas ou raciocinando sobre a inovação em vários campos, a o3 está se tornando a líder dessa mudança.
Referências:
https://openai.com/index/pensando-com-images/
https://openai.com/index/introduzindo-o3-and-o4-mini/