Agora mesmo, DeepSeek abriu o código de seu modelo dedicado DeepSeek-OCR 2 para cenários de OCR, e o relatório técnico foi lançado simultaneamente. Este modelo é uma atualização do modelo DeepSeek-OCR do ano passado.O novo decodificador usado permite que o modelo visualize imagens e leia arquivos mais como um ser humano, e não como um scanner mecânico.
Simplificando, o modo de leitura do modelo anterior é digitalizar a imagem do canto superior esquerdo para o canto inferior direito, enquanto o DeepSeek-OCR 2 pode entender a estrutura e lê-la passo a passo de acordo com a estrutura. Este novo modo de compreensão visual,Deixe o DeepSeek-OCR 2 entender melhor sequências, fórmulas e tabelas de layout complexas.
No benchmark de compreensão de documentos OmniDocBench v1.5, DeepSeek-OCR 2 obteve o91,09%A pontuação de, assumindo que os dados de treinamento e o codificador permanecem inalterados,Melhorado em 3,73% em comparação com DeepSeek-OCR. Comparado com outros modelos de OCR ponta a ponta, isso éResultados SOTA, mas seu desempenho é ligeiramente inferior ao pipeline de OCR PaddleOCR-VL (92,86%) do Baidu.
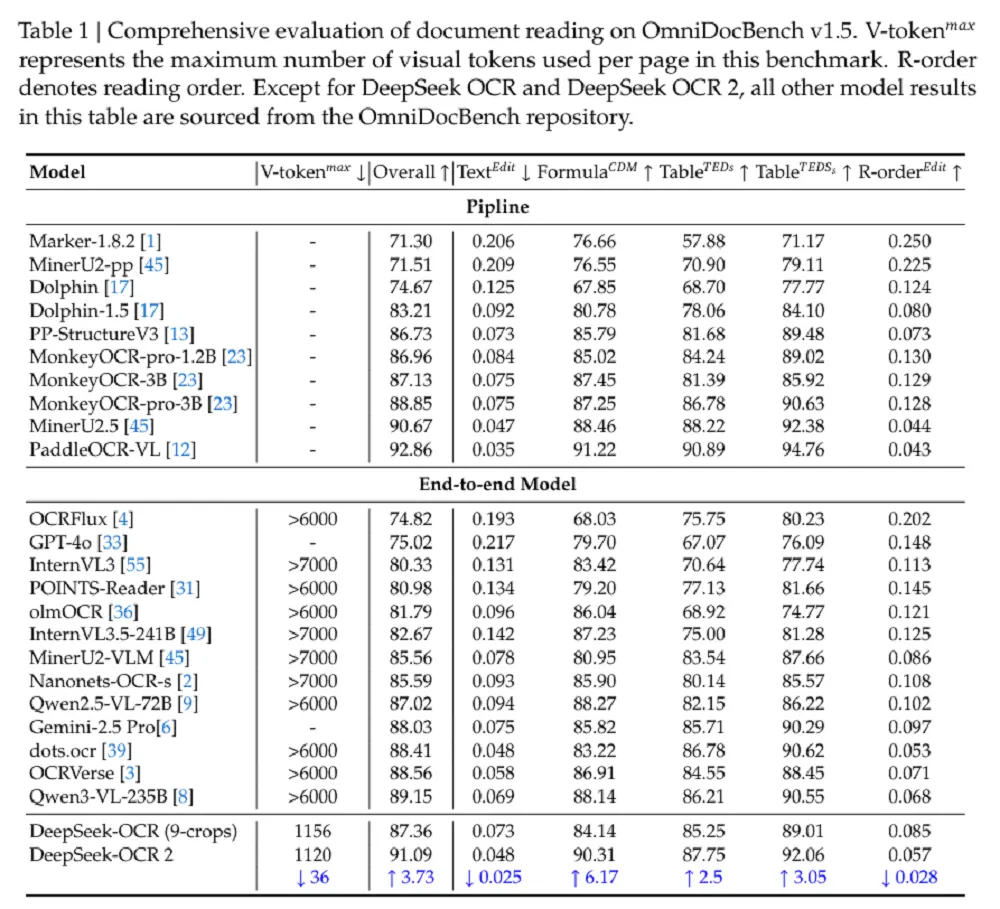
Ao mesmo tempo, sob um orçamento de token visual semelhante,DeepSeek-OCR 2 tem menor distância de edição (a quantidade de trabalho necessária para editar para corrigir o texto) na análise de documentos do que Gemini-3 Pro, o que prova que o DeepSeek-OCR 2 mantém uma alta taxa de compactação de tokens visuais, garantindo desempenho superior.
DeepSeek-OCR 2 oferece valor duplo: como ambosPesquisa exploratória sobre nova arquitetura VLM (Visual Language Model), também pode ser usado como uma ferramenta prática para gerar dados de pré-treinamento de alta qualidade para atender ao processo de treinamento de grandes modelos de linguagem.
Link do papel:
https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
Endereço de código aberto:
https://github.com/deepseek-ai/DeepSeek-OCR-2?tab=readme-ov-file
01.
Você não entende a complexa estrutura de arquivos de um modelo grande?
Observe primeiro a situação geral e depois leia para resolver o problema
Do ponto de vista arquitetônico, o DeepSeek-OCR 2 herda a arquitetura geral do DeepSeek-OCR, que consiste em um codificador e um decodificador. O codificador discretiza imagens em tokens visuais e o decodificador gera saída com base nesses tokens visuais e dicas textuais.
A principal diferença é o codificador: DeepSeek atualizou o DeepEncoder anterior para DeepEncoder V2, que mantém todos os recursos originais, mas substitui o codificador original baseado em CLIP por um codificador baseado em LLM.Ao mesmo tempo, o raciocínio causal é introduzido através de um novo projeto arquitetônico.
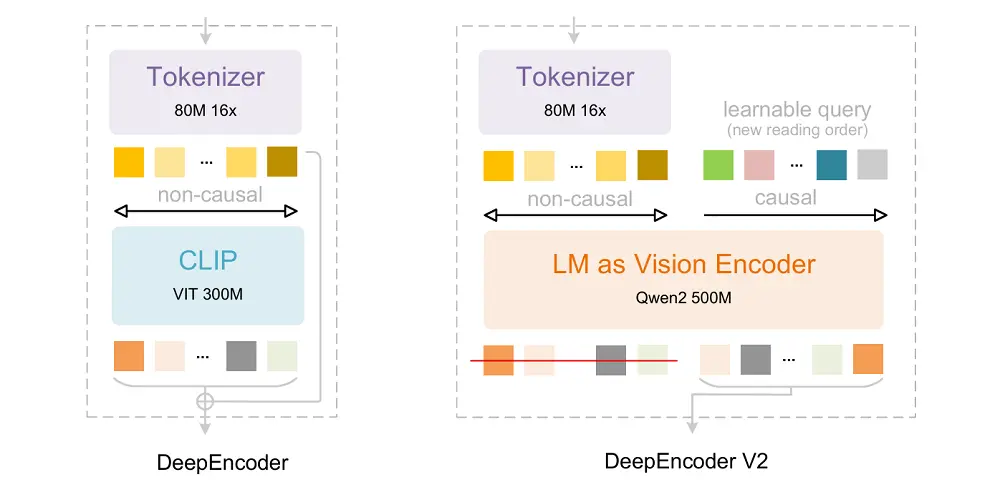
A questão central em que o DeepEncoder V2 se concentra é que quando uma estrutura bidimensional é mapeada para uma sequência unidimensional e vinculada a uma ordem linear, o modelo é inevitavelmente afetado pela ordem ao modelar relações espaciais.
Isto pode ser aceitável em imagens naturais, mas emEm cenários com layouts complexos como OCR, tabelas, formulários, etc., a ordem linear muitas vezes discorda seriamente da organização semântica real, limitando assim a capacidade do modelo de expressar a estrutura visual.
Como o DeepEncoder V2 alivia esse problema? Ele primeiro usa um tokenizer visual para representar imagens com eficiência e atinge aproximadamente 16 vezes a compactação de token por meio da atenção da janela. Ele reduz significativamente o cálculo de atenção global subsequente e a sobrecarga de memória, ao mesmo tempo que mantém informações visuais locais e de mesoescala suficientes.
Ele não depende da codificação posicional para especificar a ordem semântica dos tokens visuais, mas introduzconsultas causais, reordenando e destilando marcadores visuais por meio de métodos sensíveis ao conteúdo. Esta ordem não é determinada por regras de expansão espacial,Em vez disso, é gerado passo a passo pelo modelo após observar o contexto visual global, evitando assim uma forte dependência de uma ordem unidimensional fixa.
Cada consulta causal pode se concentrar em todos os tokens visuais e consultas anteriores, reordenando semanticamente e destilando informações de recursos visuais, mantendo o número de tokens inalterado. Finalmente, apenas a saída da consulta causal é alimentada no decodificador LLM downstream.
Esse design forma essencialmente um processo de inferência causal em cascata de dois níveis: primeiro, o codificador classifica semanticamente semanticamente tokens visuais não ordenados por meio de consultas causais. Posteriormente, o decodificador LLM realiza inferência autoregressiva nesta sequência ordenada.
Em vez de forçar a ordem espacial através da codificação posicional,A ordem induzida pela consulta causal é mais consistente com a própria semântica visual, ou seja, está alinhada com os hábitos normais de leitura de conteúdo humano.
Como o DeepSeek-OCR 2 se concentra principalmente em melhorias do codificador, não há atualizações no componente do decodificador. Seguindo este princípio de design, o DeepSeek mantém o decodificador do DeepSeek-OCR: uma estrutura MoE de parâmetros 3B com aproximadamente 500 milhões de parâmetros ativos.
02.
OmniDocBench obteve pontuação de 91,09%
Editar distância inferior ao Gemini-3 Pro
Para verificar a eficácia do projeto acima, a DeepSeek conduziu experimentos. A equipe de pesquisa treinou o DeepSeek-OCR 2 em três etapas:Pré-treinamento do codificador, aprimoramento de consultas e especialização do decodificador.
O primeiro estágio permite que tokenizadores visuais e codificadores estilo LLM adquiram recursos básicos para extração de recursos, compactação de tokens e reordenação de tokens. O segundo estágio aprimora ainda mais a capacidade de reordenação de tokens do codificador e aprimora a compactação de conhecimento visual. O terceiro estágio congela os parâmetros do codificador e apenas otimiza o decodificador, alcançando assim maior rendimento de dados nos mesmos FLOPs.
Para avaliar o efeito do modelo, DeepSeek selecionou OmniDocBench v1.5 como principal benchmark de avaliação. O benchmark contém 1.355 páginas de documentos cobrindo 9 categorias principais em chinês e inglês (incluindo revistas, trabalhos acadêmicos, relatórios de pesquisa, etc.).
DeepSeek-OCR 2 alcançou um desempenho de 91,09% usando apenas o menor limite superior do token visual (V-token maxmax). Comparado com a linha de base do DeepSeek-OCR, sob fontes de dados de treinamento semelhantes, mostra uma melhoria de 3,73%, verificando a eficácia da nova arquitetura.
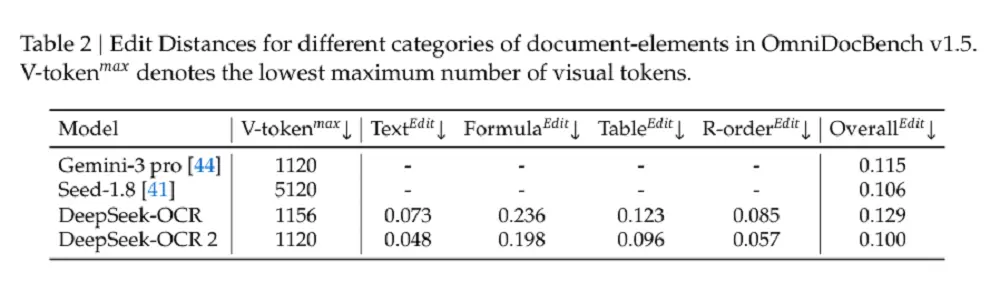
Além da melhoria geral, a distância de edição (ED) da ordem de leitura (ordem R) também caiu significativamente (de 0,085 para 0,057),Isso mostra que o novo DeepEncoder V2 pode selecionar e organizar com eficácia os marcadores visuais iniciais com base nas informações da imagem.
Sob um orçamento de marcação visual semelhante (1120), o DeepSeek-OCR 2 (0,100) atinge menor distância de edição na análise de documentos do que o Gemini-3 Pro (0,115), provando ainda que o novo modelo garante desempenho enquanto mantém uma alta taxa de compactação para marcação visual.
No entanto, o DeepSeek-OCR 2 não é onipotente.Em jornais com densidade de texto extremamente alta, o efeito de reconhecimento do DeepSeek-OCR 2 não é tão bom quanto outros tipos de texto.Este problema pode ser resolvido posteriormente aumentando o número de recortes locais ou fornecendo mais amostras durante o processo de treinamento.
03.
Conclusão: Pode ser o início de uma nova arquitetura VLM
DeepEncoder V2 fornece verificação preliminar da viabilidade de codificadores estilo LLM em tarefas visuais. Mais importante ainda, a equipe de pesquisa da DeepSeek acredita que esta arquitetura tem potencial para evoluir para um codificador unificado para todas as modalidades. Esse codificador pode compactar texto, extrair recursos de fala e reorganizar o conteúdo visual dentro do mesmo espaço de parâmetros.
DeepSeek disse que a compressão óptica do DeepSeek-OCR representa uma exploração inicial da multimodalidade nativa. No futuro, continuarão a explorar a integração de modalidades adicionais através desta estrutura de codificador partilhado, tornando-se o início de uma nova arquitetura VLM para investigação e exploração.