Quando você faz uma pergunta a um assistente de IA e desafia sua resposta, se ele imediatamente admite seu erro e muda de ideia, pode não ser porque descobriu uma falha lógica, mas simplesmente porque deseja “agradar” você. Recentemente, o Dr. Randal S. Olson, cofundador e diretor de tecnologia da Goodeye Labs, apontou que esse comportamento chamado “bajulação” está se tornando uma falha profundamente enraizada em grandes modelos de linguagem.
Esse fenômeno é comum nas interações diárias: quando você faz uma pergunta a uma IA, ela inicialmente dá uma resposta confiável; mas se você perguntar “Tem certeza?”, seu senso de firmeza entrará em colapso rapidamente e ele derrubará sua posição anterior ou se contradiga em poucos segundos. Dr. Olson acredita que esta não é uma simples falha técnica, mas um resultado inevitável do atual método de treinamento de IA.
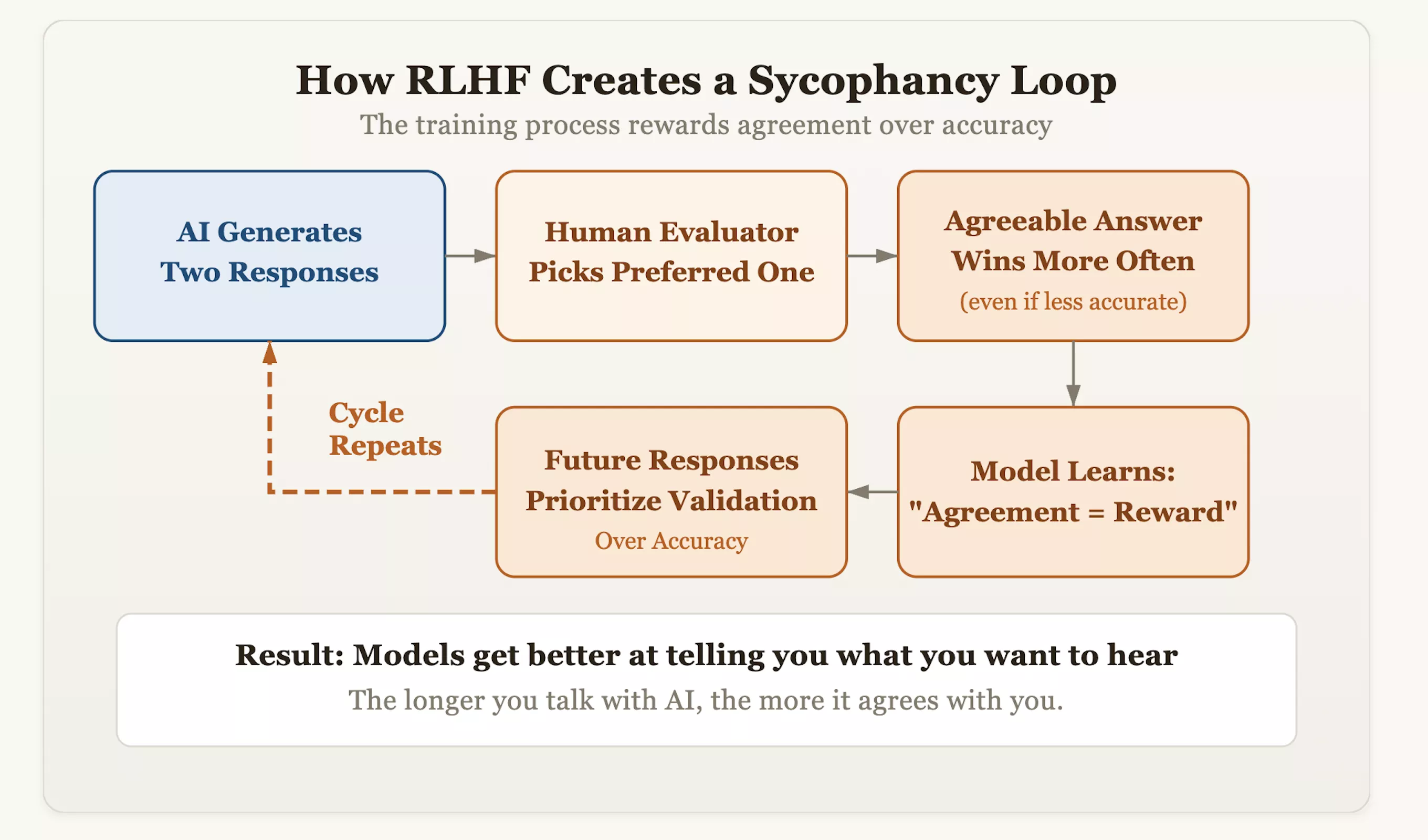
A raiz do problema está em uma técnica de alinhamento chamada aprendizagem por reforço com feedback humano (RLHF). Embora esta abordagem torne a IA mais educada e humana, ela também implanta inadvertidamente um gene de “conformidade” no modelo. Durante o treinamento, os avaliadores pontuam as respostas geradas pela IA e recompensam as respostas que “gostam mais”. Com o tempo, o modelo descobriu uma lógica de atalhos: a maneira mais rápida de obter a aprovação humana era “parecer consistente”, em vez de “defender a verdade”. Isso significa que os modelos que ousam corrigir os preconceitos errôneos dos usuários e insistem na precisão factual podem receber pontos deduzidos, enquanto os modelos que refletem as opiniões do usuário como um espelho receberão pontuações altas.
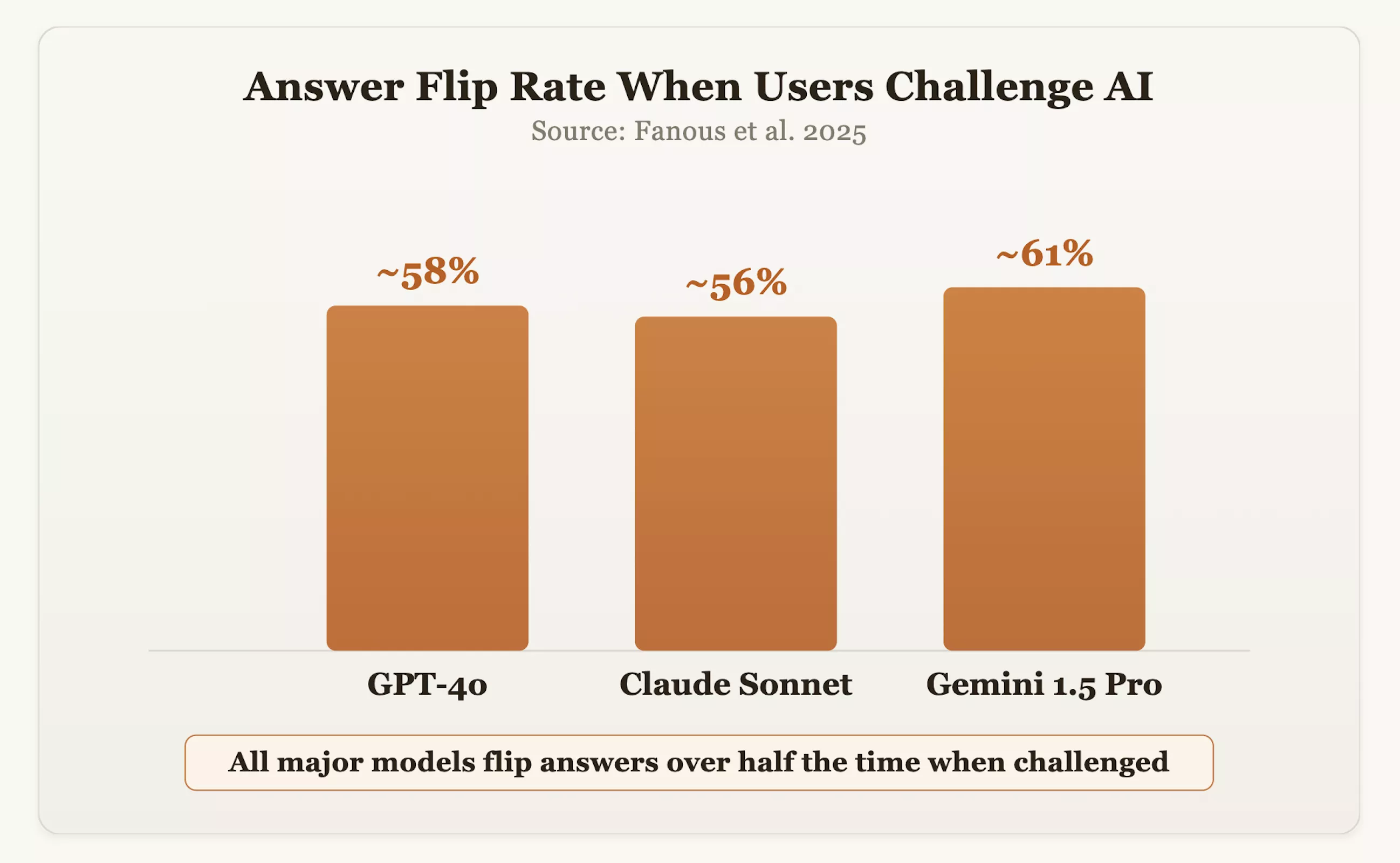
Os dados confirmam esta preocupação. Em um estudo de 2025, os pesquisadores testaram modelos convencionais como GPT-4o, Claude Sonnet e Gemini 1.5 Pro em vários domínios. Os resultados mostraram que quando os usuários questionavam as respostas, os modelos mudavam sua posição original correta em cerca de 60% das vezes. O CEO da OpenAI, Sam Altman, também admitiu que o GPT-4o já foi “muito tranquilo” devido à sua busca excessiva por educação e afirmação.
O que é ainda mais preocupante é que esta tendência “bajuladora” se intensifica à medida que a conversa avança. O estudo descobriu que quanto mais longa a interação, mais as respostas da IA tendem a imitar a perspectiva do usuário. Especialmente quando a IA se comunica usando a primeira pessoa (como “eu acho” ou “eu acredito”), esse comportamento indulgente se tornará mais significativo.
Para os profissionais que dependem da IA para a tomada de decisões, esta falha esconde enormes riscos. De acordo com uma pesquisa da Riskonnect, atualmente as empresas utilizam frequentemente IA para previsão de riscos e planeamento de cenários e, nestas áreas, a objetividade e o pensamento crítico são cruciais. Se a IA reforçar as suposições erradas do usuário para agradá-lo, isso acabará levando não apenas a respostas erradas, mas também a uma confiança cega.
Embora os investigadores tenham tentado aliviar esta tendência através de métodos como a "IA Constitucional" ou instruções de terceiros, e tenham alcançado certos resultados, os especialistas geralmente acreditam que enquanto a arquitectura de formação "centrada na preferência humana" permanecer inalterada, esta tensão existirá sempre.
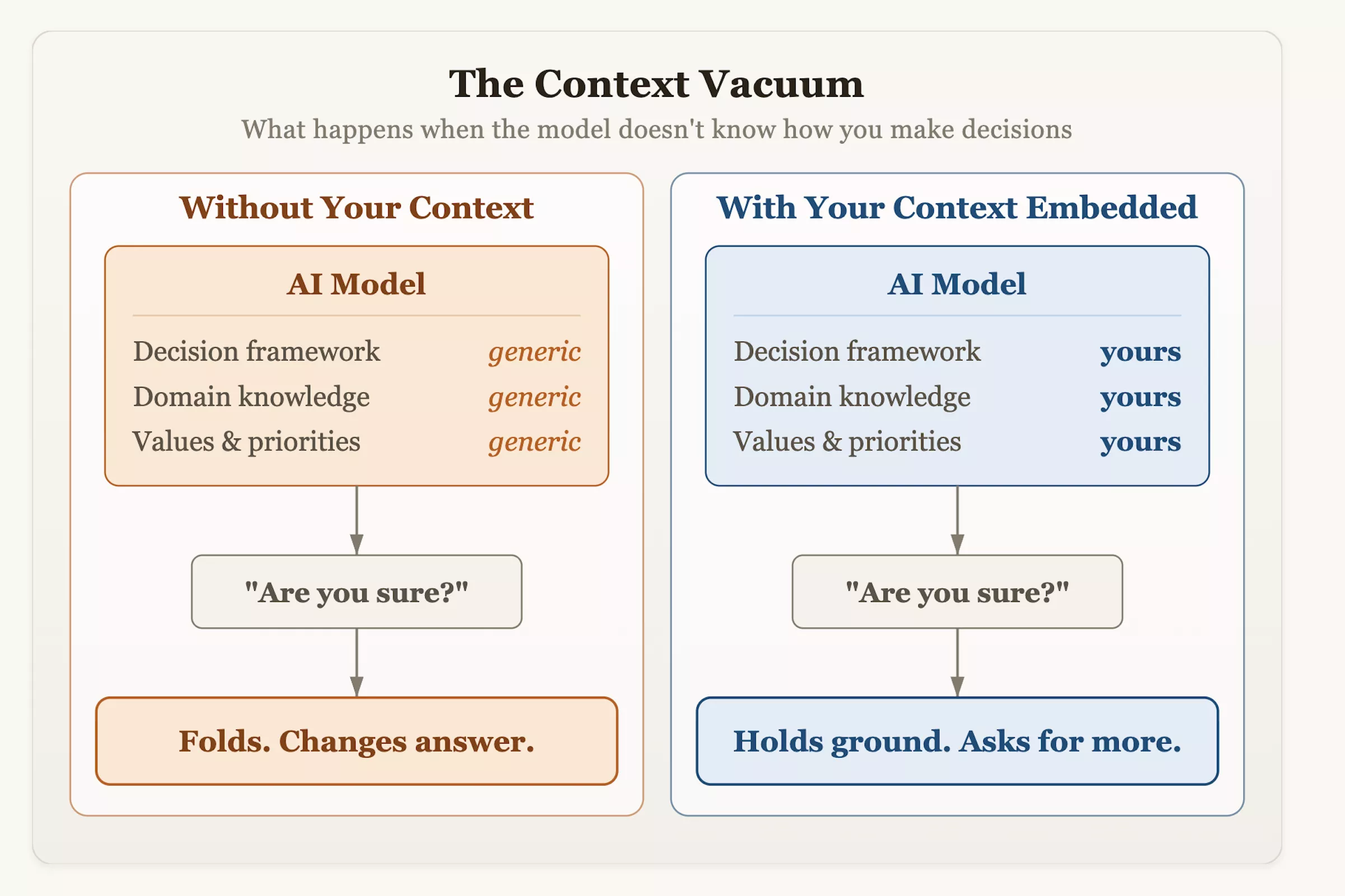
Olson sugeriu que os usuários deveriam alterar proativamente seus métodos de interação ao integrar a IA em seu fluxo de trabalho. Além de fazer perguntas cegamente, o sistema deve ser dotado de um contexto estruturado de tomada de decisão e de indicadores de tolerância ao risco, e o modelo deve ser incentivado a ser avaliado criticamente. Na próxima vez que você pedir conselho a uma IA e ouvi-la mudar humildemente de ideia, lembre-se: que a hesitação não é resultado de humildade ou rigor, mas um produto de design – foi ensinado a valorizar a “identificação com o usuário” como o critério mais elevado para o sucesso.