Esta manhã, a Anthropic lançou o modelo Sonnet mais poderoso da história——Soneto de Claude 4.6Aí vem, o novo modelo está aquiProgramação, uso de computadores, raciocínio de contexto longo, planejamento de agentes, trabalho de conhecimento e trabalho de designevolução abrangente.
A julgar pelos resultados dos testes de benchmark publicados pela Anthropic, Claude Sonnet 4.6'sO nível de inteligência está próximo do nível Opus, em análise financeira do Agente, tarefas de escritório, raciocínio visualEm diversas avaliaçõesainda mais do queLançado em 6 de fevereiroOpus 4.6, mas mais acessível. Na série de modelos Claude, o modelo menor é geralmente chamado de Haiku, o modelo de tamanho médio é chamado de Sonnet e o modelo maior e mais inteligente é o Opus.
Após o lançamento do Sonnet 4.6, as ações de software dos EUA estavam em crise. No fechamento de terça-feira, horário do leste, a Intuit caiu mais de 5%, Oracle e Applovin caíram mais de 3%, Salesforce, Atlassian, Palo Alto Networks e Autodesk caíram mais de 2%, e Adobe e ServiceNow caíram mais de 1%.
Um desenvolvedor anunciou sua experiência de teste na plataforma socialO preço é quase metade mais barato.

▲ Exemplos de experiência de Claude Sonnet 4.6 na plataforma social X
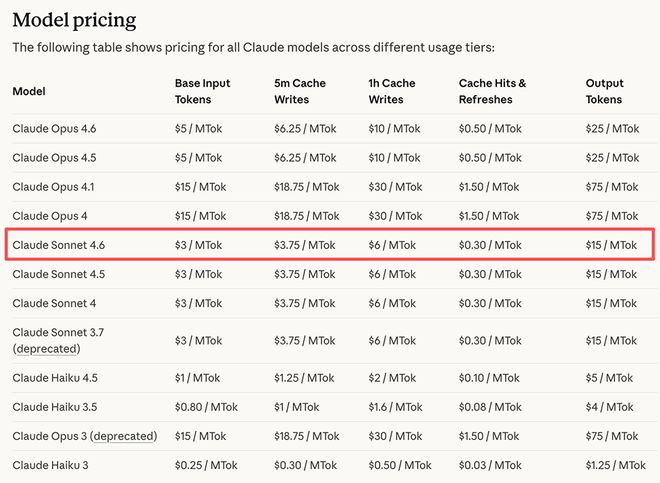
Soneto 4.6 beta temJanela de contexto de 1 milhão de tokens. Para assinantes gratuitos e Pro, Claude Sonnet 4.6 se tornou o modelo padrão para Claude.ai e Claude Cowork e agora suporta criação de arquivos, conectores, experiência e compactação de conteúdo. O preço deste modelo é consistente com o Soneto 4.5, com um preço de entrada por milhão de tokens deUS$ 3(aproximadamente RMB 21), o preço de produção éUS$ 15(aproximadamente RMB 104).
A AWS anunciou imediatamente que o Sonnet 4.6 foi lançado no Amazon Bedrock. AWS diz que isso é antrópicoO modelo de uso de computador mais poderoso, para empresas que estão ampliando seus fluxos de trabalho de IA, isso significa um ROI mais alto sem sacrificar a qualidade.

Esta também é a primeira vez que a Anthropic revela um novo modelo desde que se tornou um unicórnio de um trilhão de dólares. Em 13 de fevereiro, a Anthropic anunciou a conclusão de uma G rodada de financiamento de US$ 30 bilhões (aproximadamente RMB 207,261 bilhões), com sua avaliação saltando para US$ 380 bilhões (aproximadamente RMB 2,63 trilhões).
Após o lançamento do Sonnet 4.6, as ações de software dos EUA estavam em crise. No fechamento de terça-feira, horário do leste, a Intuit caiu mais de 5%, Oracle e Applovin caíram mais de 3%, Salesforce, Atlassian, Palo Alto Networks e Autodesk caíram mais de 2%, e Adobe e ServiceNow caíram mais de 1%.
1. O efeito é próximo ao Opus 4.6 e o custo é menor. As operações de pesquisa e milhões de contextos de token são os destaques.
Claude Sonnet 4.6 atraiu atenção e discussão no círculo de desenvolvedores desde seu lançamento.
Um desenvolvedor estrangeiro disse: "Claude Sonnet 4.6Alcançar um nível de inteligência próximo ao Opus a um custo menor, o que faz muito sentido e é adequado para equipes com orçamento limitado. Outro internauta disse: “A verdadeira estratégia da Anthropic foi revelada:Opus luta pelo trono, Sonnet corrói o mercado."
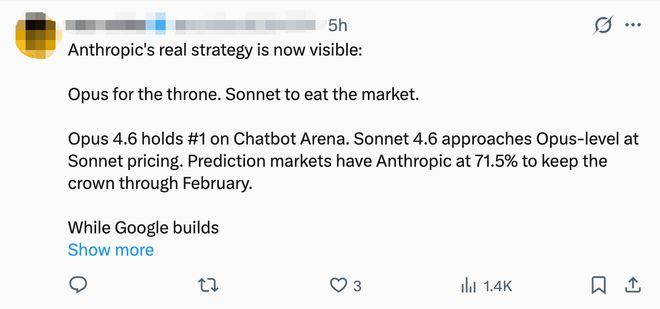
A janela de contexto de 1 milhão de tokens foi mencionada por muitos desenvolvedores como o maior destaque."1 milhão de tokens? Finalmente encontrei um que podeLeia toda a minha base de código bagunçada sem julgarMeu modelo se foi. " Disse um internauta. Outro internauta também executou o modelo por um dia inteiro e mencionou que a melhoria na codificação inteligente era óbvia: "Ele não requer mais muita intervenção ao modificar vários arquivos e pode lembrar o contexto em longas sessões. No entanto, a janela de 1 milhão de tokens é o verdadeiro destaque, você podeExporte toda a base de código e ela também não perderá nenhuma informação."

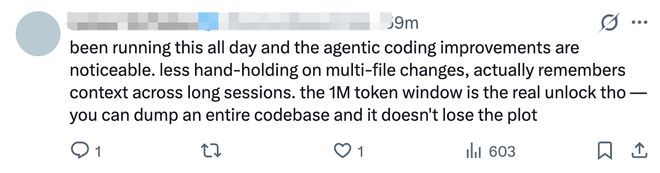
Outro internauta mostrou seu caso de julgamento, Claude Sonnet 4.6Refatorou toda a sua base de código com apenas uma chamada. 25 chamadas de ferramentas, mais de 3.000 linhas de código adicionadas e 12 novos arquivos criados. Ele implementa modularização e divide aplicativos únicos.Código bagunçado limpo. “Ainda não está tudo funcional, mas é incrível.”
▲ Exemplos de experiência de Claude Sonnet 4.6 na plataforma social X
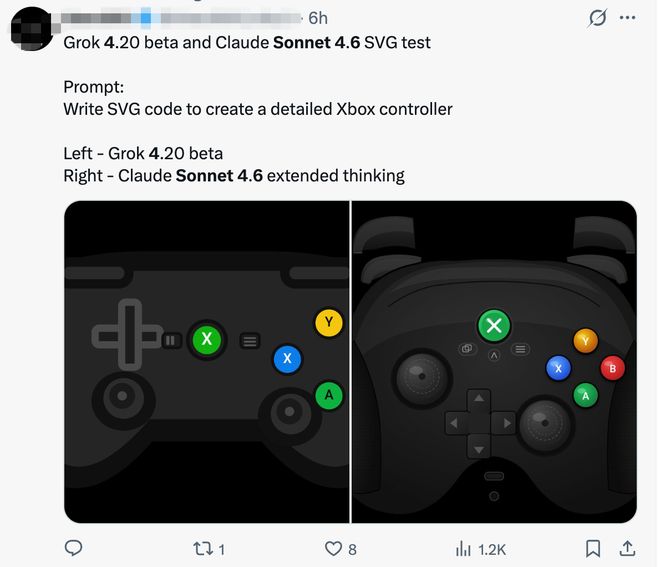
Soneto de Claude 4.6raciocínio visualA capacidade foi aprimorada, que antes era inferior ao Gemini e ao ChatGPT. Um desenvolvedor exibiu os efeitos de geração SVG do Grok 4.20 beta e Claude Sonnet 4.6, com o prompt “Escreva o código SVG para criar um controlador Xbox detalhado”. Percebe-se que as imagens geradas por Claude Sonnet 4.6 possuem um sentido tridimensional mais forte.
"Excelente desempenho na programação de Agentes" é um ponto-chave ao qual vale a pena prestar atenção. Um desenvolvedor disse que a programação de agentes requer duas coisas que os modelos sempre foram difíceis de fazer: permanecer dentro do escopo do modelo e executar instruções de várias etapas sem desvio. Se a versão 4.6 melhorar essas duas coisas, poderá mudar a forma como os modelos são entregues.

Alguns desenvolvedores estão preocupados com "Concentre-se nas operações de pesquisa", dizendo que isso significa que está indo além do preenchimento automático para a compreensão da conexão entre bases de código e se tornará uma ferramenta de navegação para sistemas complexos. Um internauta disse: “A melhoria da função de pesquisa é realmente eficaz.Economiza significativamente tempo na localização das funções necessárias em grandes bases de código."
No entanto, algumas pessoas estão preocupadas com o modo Copilot Agent.segurança de códigopergunta. Um internauta disse que um agente que é bom em pesquisa e codificação tem um escopo de influência completamente diferente de um assistente de chat. Se tiver um ambiente de produção para enviarPermissões, então, quando o fluxo de trabalho for interrompido, haveráRiscos da cadeia de abastecimento.
Apesar das ótimas críticas, alguns desenvolvedores acreditam que o Sonnet 4.6 não atende às expectativas. "Originalmente esperávamos que o Sonnet 4.6 fosse melhor que o Opus 4.5 em termos de programação, mas descobrimos que ele só foi atualizado em termos de Cowork." Alguns internautas até disseram "Soneto 4.6 = Opus 4.5", e muitos internautas mencionaram que o Soneto 4.6 não apenas não excedeu o GPT-5.2, mas também não se comparou com o efeito do Codex 5.3, questionando o teto das capacidades do modelo.


2. Múltiplos recursos excedem GPT-5.2, e a capacidade de processar formulários complexos e preencher formulários da web em várias etapas é próxima da dos humanos.
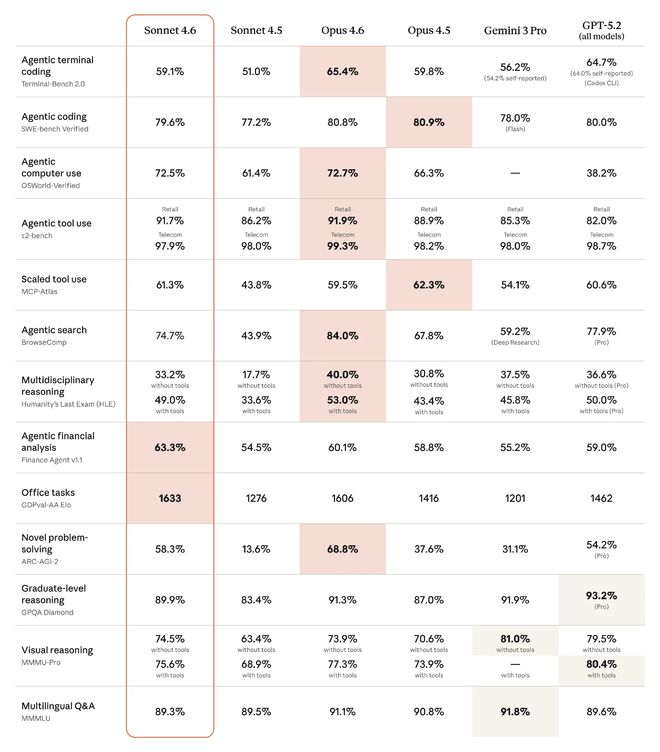
No teste de benchmark geral, Claude Sonnet 4.6 superou seu próprio Opus 4.6, Gemini 3 Pro e GPT-5.2 em vários projetos.
GDPval-AA é uma estrutura de avaliação independente para testar o desempenho do modelo em tarefas profissionais de valor econômico do mundo real. Claude Sonnet 4.6 ocupa o primeiro lugar entre todos os modelos comparados, como Claude Opus 4.6, GPT-5.2, etc.
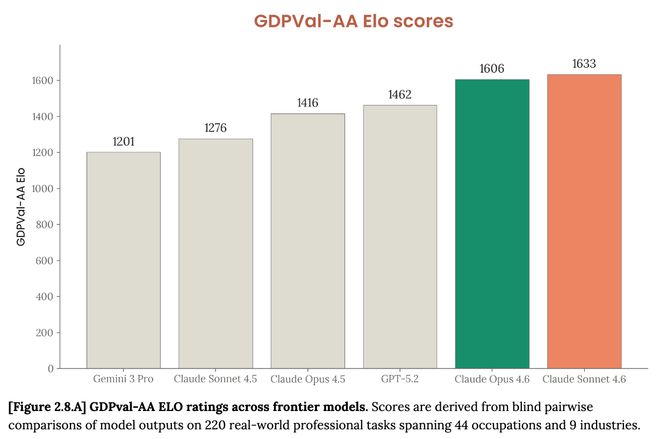
Para testes como o teste de tarefas de engenharia de software do mundo real SWE-bench, o τ²-bench que mede as capacidades de interação do agente e o teste de múltipla escolha GPQA Diamond, o desempenho de Claude Sonnet 4.6 é próximo ou superior ao de Claude Opus 4.6.
Vale ressaltar que OSWorld é a referência padrão para medir o uso de computadores com IA. Ele define centenas de tarefas baseadas no software real Chrome, LibreOffice, VS Code, etc. em um ambiente de computador simulado e não fornece APIs dedicadas ou conectores personalizados. Ao completar as tarefas, o modelo olha para a tela e opera o computador como um ser humano, clicando no mouse virtual e digitando no teclado virtual para completar a interação.
Em outubro de 2024, a Anthropic assumiu a liderança no lançamento de um modelo geral de uso do computador, mas naquela época esse modelo ainda estava em fase experimental e sujeito a erros. Após 16 meses, o desempenho do seu modelo Sonnet no teste de benchmark OSWorld melhorou gradualmente.

E seu blog mencionou que essas melhorias não se refletem apenas nos indicadores de teste. Os primeiros usuários do Sonnet 4.6 também descobriram que o modelo tem a capacidade de se aproximar dos níveis humanos em tarefas como processamento de formulários complexos, preenchimento de formulários da web em várias etapas e cooperação entre várias guias do navegador.
No Claude Code, a Anthropic descobriu em testes iniciais que os usuários preferiam o Sonnet 4.6 ao Sonnet 4.5 cerca de 70% das vezes. A razão para isto é que o Sonnet 4.6 pode ler o contexto de forma mais eficiente antes de modificar o código e integrar a lógica compartilhada em vez de duplicá-la.
Além disso, 59% dos usuários preferem o Sonnet 4.6 ao Opus 4.5. Eles acreditam que o Soneto 4.6 não tornará os problemas muito complicados, não será preguiçoso e superficial e terá uma melhoria significativa no cumprimento das instruções. Esses usuários relatam que o Sonnet 4.6 produz menos artefatos de sucesso, menos alucinações e desempenho mais consistente em tarefas de várias etapas.
3. A rentabilidade das operações comerciais simuladas excede a dos concorrentes, e o raciocínio aprofundado Opus 4.6 ainda é o mais forte
Claude Sonnet 4.6 oferece dois modos: um é o "modo de pensamento estendido", no qual o modelo passa mais tempo raciocinando; o outro é o “modo de pensamento adaptativo”, no qual o modelo ajusta de forma flexível o tempo gasto no modo de pensamento estendido de acordo com a dificuldade da tarefa. Os desenvolvedores podem controlar de forma independente o modo em que o Sonnet 4.6 executa tarefas com base em tarefas específicas.
O Soneto 4.6 possui uma janela de contexto de 1 milhão de tokens. Os pesquisadores viram isso na avaliação da Vending-Bench Arena. Este teste de benchmark testa o desempenho do modelo na simulação de operações comerciais e inclui um mecanismo de concorrência. Diferentes modelos de IA precisam competir entre si para obter lucros máximos.
A Sonnet 4.6 desenvolveu uma nova estratégia neste teste, investindo fortemente na capacitação durante os primeiros dez meses de simulação, gastando significativamente mais do que os seus concorrentes, e depois rapidamente dinamizando para se concentrar na rentabilidade na fase final. Isso coloca seus resultados de lucro final bem à frente de seus concorrentes.

Os desenvolvedores também descobriram que o Sonnet 4.6 tem melhorias particularmente notáveis no código front-end e na análise financeira, e sua saída visual é mais refinada, com melhor layout, animação e design do que o modelo anterior, exigindo menos rodadas de iteração para alcançar resultados de qualidade de produção.
A Anthropic também anunciou outras atualizações específicas de produtos em seu blog:
Na plataforma de desenvolvimento Claude, o Sonnet 4.6 suporta pensamento adaptativo e pensamento estendido, bem como a função de compressão de contexto em beta. Na API, as ferramentas de pesquisa na web e aquisição de conteúdo de Claude podem escrever e executar código automaticamente para filtrar e processar os resultados da pesquisa.
O desempenho do Soneto 4.6 é muito estável, independentemente da intensidade do pensamento. Por outro lado, o Opus 4.6 ainda é a melhor escolha para tarefas que exigem raciocínio profundo, como reconstrução de base de código, colaboração multiagente em fluxos de trabalho e problemas complexos onde a precisão é crucial.
Para a avaliação de segurança, os pesquisadores avaliaram a disposição de Claude Sonnet 4.6 em fornecer informações em um cenário de conversação única e testaram solicitações violadoras nas quais se esperava que Claude respondesse de forma inócua, bem como solicitações benignas envolvendo tópicos delicados. A avaliação está disponível em mandarim, árabe, inglês, francês, hindi, coreano e russo.
Conclusão: Altamente econômico e capaz de usar computadores para acelerar a IA em fluxos de trabalho reais
O layout do modelo da Antrópico é dividido nas séries Haiku, Sonnet e Opus. Estes modelos correspondem a diferentes preços e níveis de inteligência. O salto significativo em seu modelo Sonnet desta vez, algumas cenas podem igualar ou até superar os modelos da série Opus, aliado ao preço acessível e disponibilidade direta da versão gratuita, tudo indica que a forte ligação entre desempenho de ponta e alto custo de modelos grandes está sendo gradualmente quebrada.
A julgar pelas atualizações de desempenho específicas, o Sonnet 4.6 melhorou muito a execução real de tarefas, o alívio de alucinações e as capacidades de acompanhamento de comandos. Especialmente em termos de “usar um computador como um ser humano”, a sua interação é mais natural. Isto também promove a integração profunda do modelo no potencial de trabalho real dos usuários em cenários de escritório, P&D, finanças e análise de dados.
Artigos relacionados:
Anthropic lança Sonnet 4.6, melhorando muito o código e os recursos de processamento de textos longos