Gracenote, uma empresa de serviços de metadados e identificação de conteúdo de propriedade da Nielsen, entrou com uma ação contra a OpenAI no Tribunal Federal dos EUA para o Distrito Sul de Nova York, acusando a empresa de inteligência artificial de rastrear e usar seu banco de dados de metadados de mídia e estrutura de associação de dados exclusiva em grande escala sem autorização e sem pagar quaisquer taxas, para treinar grandes modelos de linguagem que suportam produtos comerciais como ChatGPT, constituindo grave violação de direitos autorais e colocando em risco seu negócio principal.
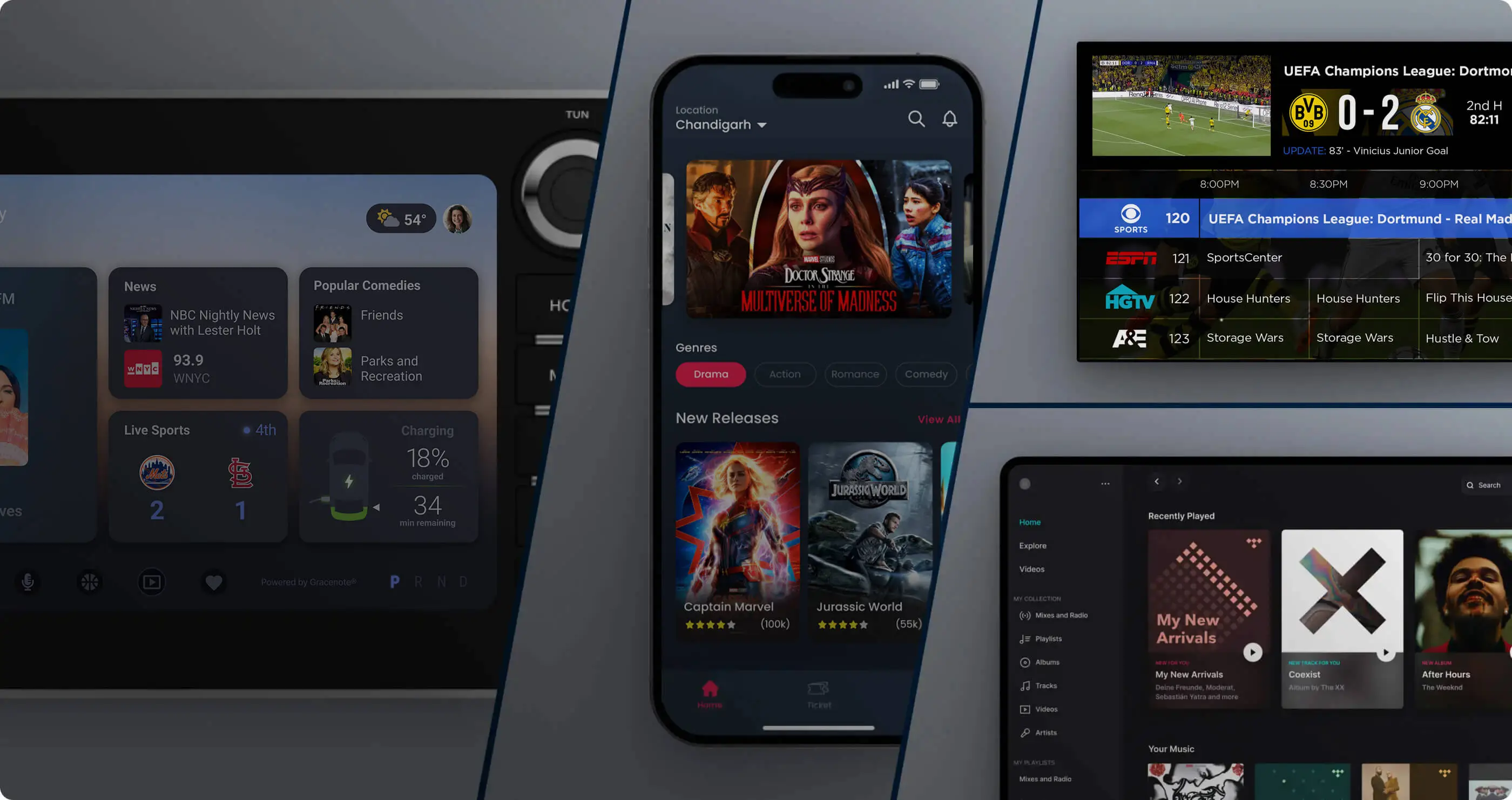
A Gracenote afirmou na reclamação que confiou em centenas de editores ao longo dos anos para editar e anotar manualmente conteúdos de filmes, televisão, música e esportes em todo o mundo, e estabeleceu um "banco de dados de programas" que inclui introduções de programas, descrições de recursos de vídeo, identificadores de conteúdo exclusivos e gráficos de relacionamento complexos, e concluiu o registro no Escritório de Direitos Autorais dos EUA. A empresa acredita que esta base de dados não contém apenas conteúdo textual específico, mas também inclui um desenho estrutural proprietário para classificar, associar e organizar diferentes obras. Essa “estrutura de relacionamento” é uma importante fonte de valor para seus serviços para clientes empresariais, como plataformas de streaming de mídia e fabricantes de smart TVs.
A reclamação afirma que a OpenAI rastreou e assimilou os dados acima sem permissão e, quando os usuários fizeram perguntas por meio do ChatGPT, gerou uma descrição que era altamente semelhante ou até mesmo completamente consistente com a introdução do programa Gracenote de maneira quase literal. Os exemplos fornecidos pela Gracenote incluem quando um usuário pediu ao ChatGPT para descrever a popular série de TV Game of Thrones, e o modelo apresentou conteúdo quase idêntico à versão escrita pelos editores da Gracenote. A empresa também disse que múltiplas versões do ChatGPT foram capazes de recitar grandes pedaços de descrições de programas em seu banco de dados com muito poucas palavras de alerta, indicando que o texto relevante e sua estrutura organizacional subjacente foram diretamente copiados e incorporados ao modelo.
Gracenote propôs que o uso não autorizado de seus metadados e estrutura relacional pela OpenAI não apenas infringia textos protegidos por direitos autorais e estruturas de banco de dados, mas também fornecia aos distribuidores de conteúdo de mídia e fabricantes de equipamentos a possibilidade de construir serviços alternativos de metadados baseados em "dados rastreados gratuitamente", enfraquecendo diretamente a competitividade de mercado de produtos similares da Gracenote. A denúncia alerta que, se tal comportamento não puder ser interrompido e remediado, os fabricantes de terminais, como as TVs inteligentes, podem contar com dados “derivados reversamente” de modelos de IA para construir suas próprias plataformas de metadados que concorram com a Gracenote, sem ter que pagar quaisquer taxas de licenciamento.
Em termos de reclamações, a Gracenote baseia-se no facto de a sua base de dados ter sido registada no Gabinete de Direitos de Autor dos EUA e, além de procurar compensação por perdas reais, também procura danos legais para lidar com o que alega ser uma violação contínua e em grande escala. Os chamados danos legais referem-se a um montante fixo ou intervalo predeterminado por lei para tipos específicos de violação de direitos de autor, enquanto os danos reais são utilizados para compensar o titular do direito pelas perdas económicas reais sofridas devido à violação.
Em resposta a uma entrevista à Axios, um porta-voz da OpenAI disse que seus modelos “permitem a inovação” e são treinados em “dados disponíveis publicamente” e apoiados pelo “uso justo”. Muitas empresas de IA, incluindo a OpenAI, têm argumentado consistentemente que modelos de formação através do rastreio de conteúdos públicos da Internet são consistentes com a determinação do uso justo ao abrigo da atual lei de direitos de autor dos EUA, alegando que estes dados podem fornecer aos utilizadores serviços e informações novos e úteis depois de serem transformados pelo modelo.
Outra razão pela qual o processo da Gracenote está a atrair a atenção é que a empresa sempre esteve aberta à cooperação com empresas de IA e alcançou vários acordos de licenciamento de dados relacionados com IA com a Samsung, Google e outras empresas. A Gracenote afirmou na reclamação que contactou a OpenAI várias vezes para discutir questões de licenciamento, mas foi “repetidamente rejeitada ou ignorada durante um longo período de tempo” e, portanto, teve de recorrer a litígios para proteger os seus direitos e interesses. O CEO da empresa, Jared Grusd, enfatizou em comunicado que “Apoiar o desenvolvimento da IA e se opor ao roubo não são inconsistentes. Eles são o único caminho para o desenvolvimento sustentável da indústria”, dizendo que o processo visa proteger este futuro.
Os profissionais jurídicos acreditam que, com múltiplas disputas de direitos autorais entre empresas de mídia e informação e empresas de IA que aguardam decisões judiciais, este caso provavelmente se tornará uma referência importante para os juízes examinarem se "obras não tradicionais", como estruturas de banco de dados e mapas de associação de metadados, podem obter proteção de direitos autorais e como determinar o "limite de uso justo de grandes modelos". A Gracenote enfatizou em sua reclamação que grande parte do conteúdo produzido pela OpenAI é “quase idêntico” aos metadados licenciados para seus clientes. Portanto, não deriva novas informações, mas é uma cópia substancial do conteúdo existente. Este se tornará um dos principais pontos de disputa que distingue este caso de outros casos de direitos autorais de IA.