O GPT-5.6 está aqui, mas... que modelo é esse? Desta vez, o OpenAI não usou os nomes familiares Pro, Mini e Instant no passado. Em vez disso, surgiu três nomes ao mesmo tempo:GPT-5.6 Sol, GPT-5.6 Terra, GPT-5.6 Luna.Sol é o sol, Terra é a terra e Luna é a lua.
Parece sofisticado, como um novo modelo de universo. Mas na verdade estamos familiarizados com as camadas de produtos: o modelo principal mais forte, um modelo equilibrado para uso diário e um modelo leve que é barato, rápido e adequado para chamadas em grande escala.
A declaração oficial da OpenAI é:A série GPT-5.6 será totalmente aberta nas próximas semanas, mas atualmente está em pré-visualização limitada a um pequeno grupo de “parceiros de confiança” no Codex e API, a pedido do governo dos EUA.
Vamos primeiro dar uma olhada na inteligência disponível publicamente.

A nota mais alta tem o mesmo preço do GPT 5.5
A OpenAI atribuiu três níveis ao GPT-5.6 desta vez: Sol, Terra e Luna.
Segundo o comunicado oficial, o Sol é o modelo carro-chefe, o Terra é um modelo balanceado para o trabalho diário e o Luna é um modelo rápido, barato e leve.
Os modelos de três níveis foram lançados de uma só vez, correspondendo basicamente à estrutura de três camadas mais comum em produtos de modelos grandes: o modelo mais forte é responsável pelo limite superior de capacidades, o modelo intermediário é responsável pela maioria das tarefas diárias e o modelo leve é responsável pela velocidade, custo e altas chamadas simultâneas.
O nível dos três pode ser visto no preço.
De acordo com o preço da API anunciado pela OpenAI,GPT-5.6 é cobrado por 1 milhão de tokens: Sol custa US$ 5 para entrada e US$ 30 para saída; Terra custa US$ 2,5 para insumos e US$ 15 para produção; e Luna custa US$ 1 para insumos e US$ 6 para produção.
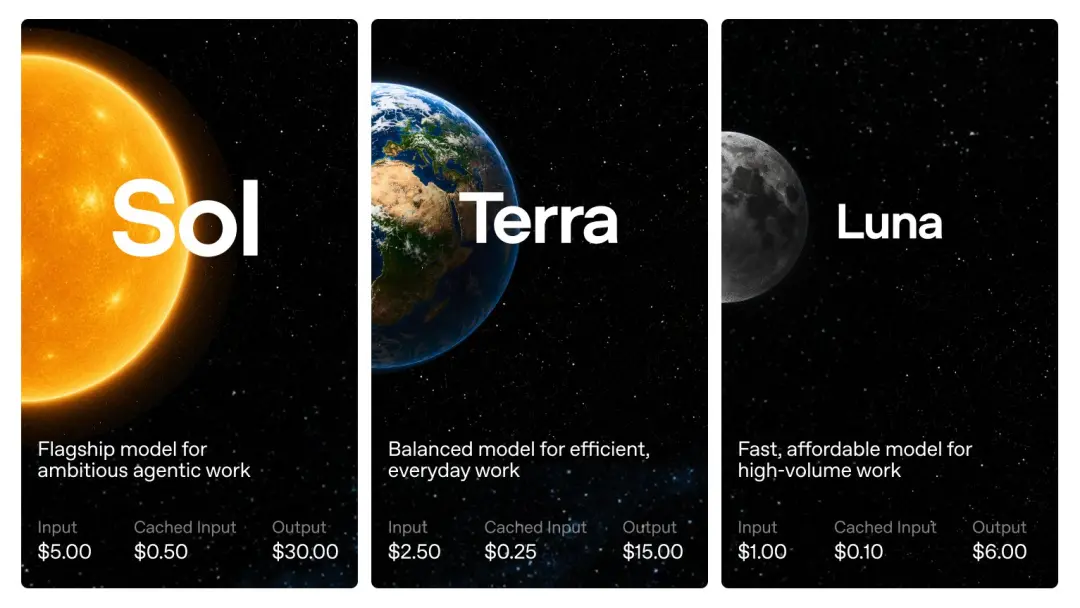
Acredito que você deve ter notado: embora o GPT-5.6 Sol seja um modelo carro-chefe da nova geração, o preço está alinhado com a versão padrão GPT-5.5, não com o GPT-5.5 Pro.
Terra caiu diretamente para metade do GPT-5.5, e Luna foi apenas um quinto do GPT-5.5.
GPT-5.5 Pro ainda é o modelo OpenAI mais caro atualmente. O preço é de US$ 30/milhão de tokens para entrada e US$ 180/milhão de tokens para saída. O preço é 6 vezes maior que a versão padrão GPT-5.5 e GPT-5.6 Sol. Não sei se haverá outro Universo GPT-5.6 que seja “mais adequado para tarefas profissionais” no futuro (brincadeirinha).
Sol é o modelo mais sofisticado desta série GPT-5.6 e também é o modelo que passa mais tempo apresentando no anúncio oficial.
A OpenAI considera o GPT-5.6 Sol o modelo mais forte atualmente, concentrando-se em suas capacidades de codificação, pesquisa biológica e segurança de rede.
Simplificando, Sol está posicionado como “o melhor modelo”. Não corresponde a cenários normais de chat, mas sim a tarefas mais complexas e mais próximas do trabalho real.
Por exemplo, em um cenário de código, ele pode continuar avançando em torno de um objetivo: primeiro entender o problema, depois dividir as etapas, depois chamar ferramentas, executar comandos, verificar os resultados e fazer correções se ocorrerem erros até que a tarefa seja concluída.
Para apoiar o Sol no processamento de tarefas mais difíceis, a OpenAI introduziu dois novos mecanismos no GPT-5.6.
O primeiro é chamadoesforço máximo de raciocínio, que pode ser traduzido como “máxima força de raciocínio”.
A compreensão popular significa que Sol tem mais tempo para pensar claramente sobre o problema e leva mais tempo para conduzir um raciocínio aprofundado. É adequado para tarefas complexas que não podem ser resolvidas pela primeira reação.
O segundo é chamadomodo ultra,Pode ser entendido como “supermodo”.
O foco deste modelo é permitir que vários subagentes participem juntos de tarefas complexas. Pode ser entendido como: no passado, um assistente de IA trabalhava por conta própria, mas agora um “gerente de IA” lidera vários assistentes para lidar com problemas separadamente, acelerando assim o avanço de trabalhos complexos.
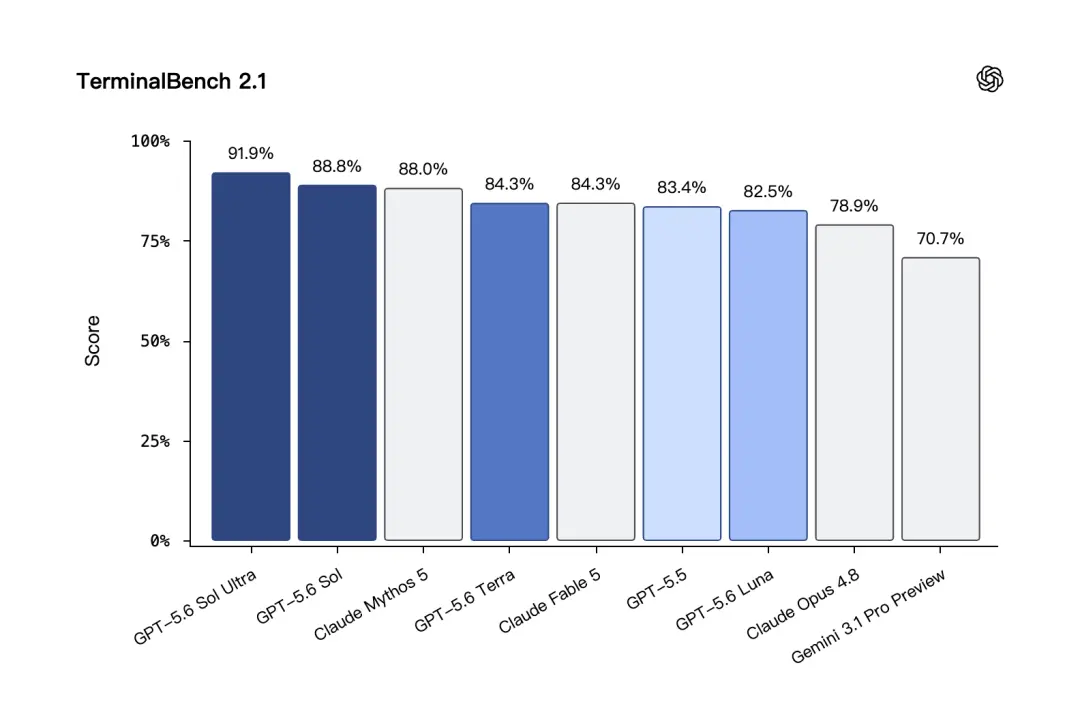
Terminal-Bench 2.1 é um teste mais próximo do processo real de desenvolvimento. Ele testa se o modelo pode resolver o problema passo a passo no ambiente de linha de comando. GPT-5.6 Sol alcançou uma pontuação alta de 88,8% neste teste, e a pontuação foi ainda maior no modo Ultra.
OpenAI mencionou especificamente que quando o modelo for mais aberto, um conjunto mais completo de resultados de avaliação será divulgado.
Terra é a faixa intermediária.
A introdução da OpenAI no Terra não é tão longa, mas seu posicionamento é claro: é um modelo equilibrado para o trabalho diário.
Ou seja, não persegue necessariamente os mais fortes, mas estabelece um equilíbrio entre efeito, velocidade e custo. As autoridades enfatizaram que as capacidades do Terra estão próximas do GPT-5.5, mas o preço é metade do preço.
Na visão da OpenAI, o Terra provavelmente será o mais usado na série GPT-5.6. As tarefas comuns de escritório geralmente não exigem os recursos mais elevados como o Sol, mas precisam ser estáveis, baratas e fáceis de usar.
No teste Terminal-Bench 2.1,GPT-5.6 Terra obteve 84,3%, o mesmo que Claude Fable 5.
Luna é a faixa de menor custo.
O posicionamento do Luna pela OpenAI também é muito simples: rápido, barato e adequado para tarefas de grande escala, alta frequência e sensíveis ao custo.
Por exemplo, resumo em lote, classificação de texto, extração de informações, perguntas e respostas simples, etc. Essas tarefas em si não são necessariamente complexas, mas o volume de chamadas pode ser muito grande. O papel do Luna é executar essas tarefas leves a um custo menor.
Entre esses três modelos, o Sol é responsável pelas capacidades mais altas, o Terra é responsável pelo trabalho diário e o Luna é responsável pela velocidade e custo. Parece sofisticado, mas o OpenAI apenas reembala as camadas já maduras da grande indústria de modelos.
Mas acho que o nome não importa, desde que seja barato e fácil de usar.

Custo-benefício
Só de olhar para o anúncio oficial, os benchmarks divulgados pelo GPT-5.6 Sol desta vez não são muitos. A própria OpenAI disse que agora é apenas para que o mundo exterior conheça antecipadamente o desempenho do modelo, para que primeiro compartilhe um conjunto de resultados de avaliação.
Mas o conjunto de benchmarks divulgado tem uma direção clara, concentrando-se em três áreas: código, biologia e segurança de rede.
O referido Terminal-Bench 2.1 pertence à direção do código. Ele testa se o modelo pode completar o processo real de desenvolvimento no ambiente de linha de comando, incluindo planejamento, modificações repetidas, chamada de ferramentas e verificação de resultados.
Além do código, a OpenAI também destacou um benchmark biológico: GeneBench v1.
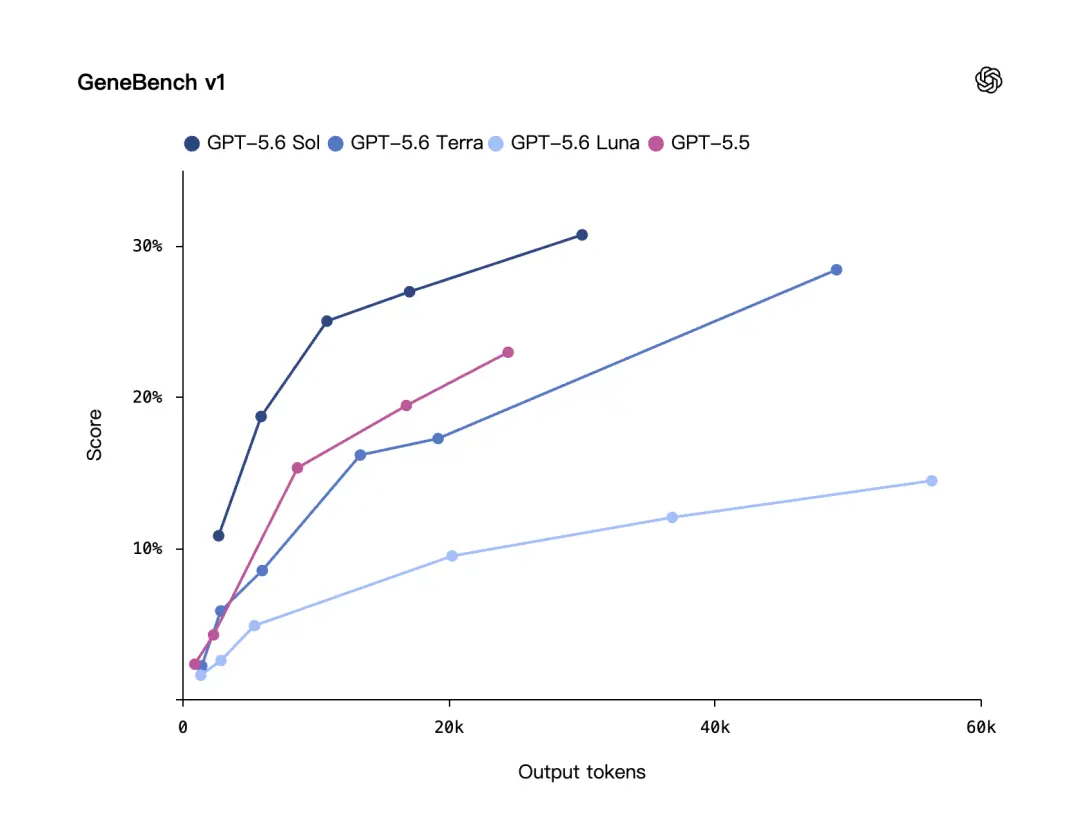
GeneBench v1 avalia genômica de longo prazo e tarefas de análise biológica quantitativa, concentrando-se em se o modelo pode lidar com problemas de análise mais próximos do processo real de pesquisa científica.
De acordo com a OpenAI, o GPT-5.6 Sol tem desempenho melhor que o GPT-5.5 no GeneBench v1, eUse menos tokens.
A terceira direção principal é a segurança da rede. A OpenAI afirma que o GPT-5.6 Sol é o seu modelo de segurança de rede mais forte atualmente, especialmente para tarefas de segurança de longo prazo (incluindo pesquisa de vulnerabilidades e tarefas relacionadas à exploração de vulnerabilidades).
Há um benchmark aqui chamado ExploitBench – não é uma pergunta e resposta geral de segurança, mas uma avaliação mais próxima dos cenários de exploração de vulnerabilidades.
OpenAI disse que no ExploitBench,O desempenho do GPT-5.6 Sol é comparável ao Mythos Preview, mas usa apenas cerca de um terço dos tokens de saída.
Porém, ainda existe uma certa lacuna no quadro oficial.
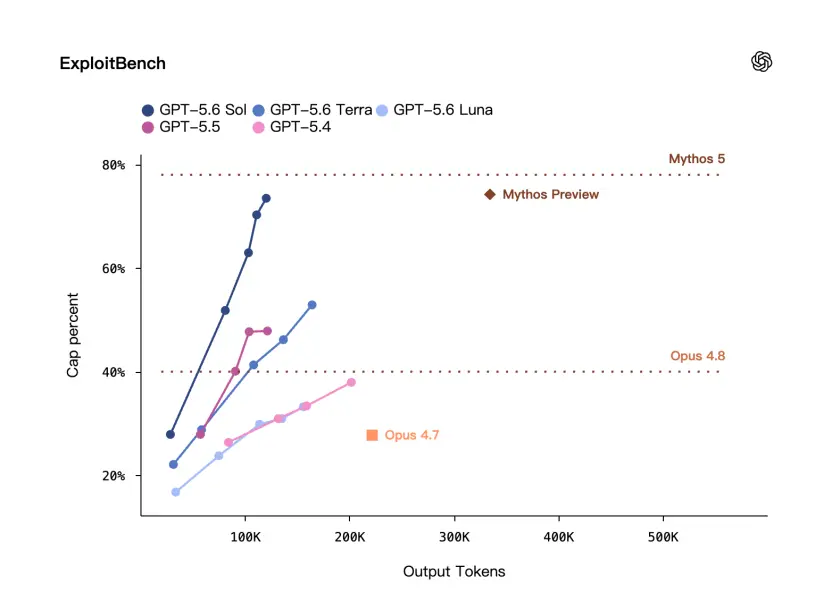
Pode-se ver que a OpenAI enfatizou repetidamente desta vez:Embora sejam altamente capazes, também são extremamente eficientes.
Menos tokens de saída significam que o modelo pode ser mais conciso e ter menos desvios ao concluir tarefas semelhantes, e também pode significar que o custo real da chamada é mais controlável.
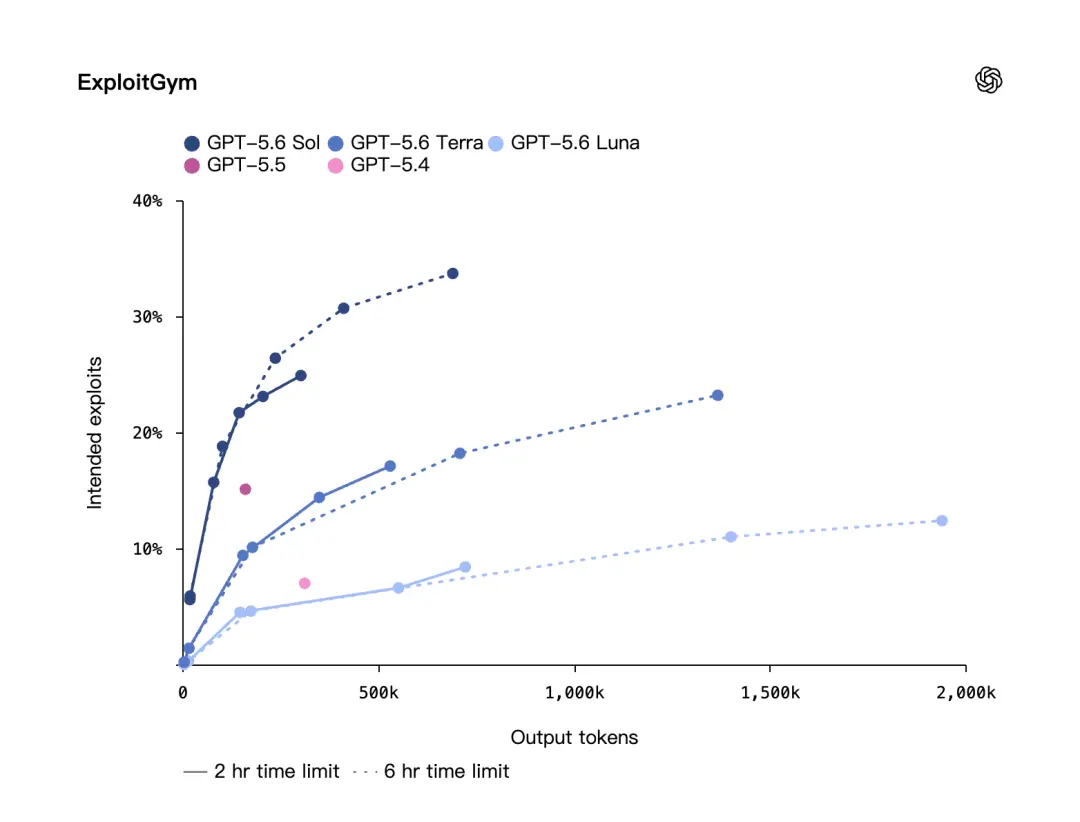
A OpenAI também mencionou outro benchmark de segurança cibernética: ExploitGym.
Este benchmark foi criado por pesquisadores da UC Berkeley em colaboração com OpenAI e outros laboratórios de ponta. OpenAI disse que no ExploitGym, os modelos GPT-5.6 Sol, Terra e Luna mostram melhorias significativas nas capacidades de segurança de rede e, à medida que a intensidade de inferência aumenta, o desempenho se tornará mais forte.
Isso significa que a melhoria do GPT-5.6 não se trata apenas do corpo do modelo mais forte, mas também do método de raciocínio. Dê ao modelo mais tempo para pensar e deixe-o fazer uma cadeia de raciocínio mais longa, e os resultados serão melhores.

Sobre a visualização limitada
Se Sol, Terra e Luna são mudanças superficiais do GPT-5.6, então o que merece mais atenção é que o OpenAI não foi totalmente aberto desta vez.
De acordo com o anúncio oficial, atualmente o GPT-5.6 estará disponível apenas para visualização limitada no Codex e API para um pequeno grupo de “parceiros confiáveis”.
Além disso, esta pré-visualização limitada foi realizada “a pedido do governo dos EUA”, e a lista de parceiros participantes na pré-visualização foi partilhada com o governo dos EUA.
Nos últimos tempos, o governo dos EUA aumentou significativamente o seu envolvimento em modelos de IA de ponta, especialmente aqueles com código mais forte, segurança de rede e capacidades de agente.
Em Junho deste ano, o governo dos EUA emitiu uma nova ordem executiva relacionada com a segurança cibernética da IA, propondo estabelecer um quadro voluntário para permitir que os criadores de modelos de ponta contactem e avaliem o modelo antes de este ser divulgado de forma mais ampla.
A interpretação desta ordem administrativa pela comunidade jurídica é que não se trata de uma licença compulsória nominal, nem de um sistema formal de aprovação, mas criou um quadro institucional para a participação do governo no modelo de avaliação pré-lançamento.
O modelo de lançamento do GPT-5.6 Sol de “primeira visualização em pequena escala e compartilhamento da lista com o governo” pode ser visto como o primeiro traço claro de intervenção governamental no processo de lançamento do modelo de ponta.
A própria OpenAI também explicou no anúncio que a razão para adotar esta abordagem é explorar um processo repetível com o governo para apoiar futuros lançamentos de modelos.
A principal razão por trás da intervenção governamental é a segurança da rede.
No anúncio oficial, a segurança de rede ocupa muito espaço: OpenAI enfatiza que GPT-5.6 Sol é seu modelo de segurança de rede mais forte atualmente e pode fornecer ajuda mais forte em tarefas de longo prazo, como pesquisa de vulnerabilidades, análise de vulnerabilidades e defesa de segurança; por outro lado, gasta muito espaço explicando que não ultrapassou seu próprio limite de Crítica Cibernética.
Na estrutura de preparação da OpenAI, as capacidades de alto risco são divididas em diferentes níveis. Alcançar Alto significa que o modelo pode amplificar os riscos graves existentes; atingir o nível Crítico significa que o modelo pode trazer riscos sérios novos e sem precedentes.
A OpenAI enfatizou repetidamente que o GPT-5.6 Sol não atinge o nível Cibercrítico. Na verdade, está a dizer ao governo, aos clientes e ao público: este modelo é muito forte, especialmente em tarefas de segurança de rede, mas não é suficientemente forte para completar de forma independente as cadeias de ataque à rede mais perigosas.
Os recursos de segurança de rede são como uma faca de dois gumes. Quanto mais fortes forem, mais poderão ajudar os defensores a encontrar vulnerabilidades, escrever patches e realizar testes de segurança; mas precisamente porque são tão fortes, o governo também se preocupará com o seu abuso.
Embora a OpenAI tenha admitido que esta versão exige a exploração do processo com o governo, também deixou claro no anúncio oficial que não acredita que este processo de acesso do governo deva se tornar o mecanismo padrão de longo prazo.
A justificativa: se as ferramentas mais poderosas atrasarem, os usuários, desenvolvedores, empresas, defensores da rede e parceiros em todo o mundo atrasarão a obtenção das melhores ferramentas.
De certa forma, os modelos de última geração estão entrando em uma nova fase de lançamento.
Quando as capacidades de grandes modelos estiverem concentradas em áreas como código, biologia, segurança de rede e execução de agentes, ela começará a ser considerada uma tecnologia com potencial para impactar a segurança do mundo real.
Uma vez que a tecnologia é vista desta forma, é difícil que os direitos de publicação permaneçam completamente nas mãos da própria empresa.