A má notícia é que a lacuna entre os modelos de código aberto e de código fechado está ficando cada vez maior. Boas notícias, DeepSeek está de volta. Em 1º de dezembro, DeepSeek lançou dois novos modelos – DeepSeek V3.2 e DeepSeek-V3.2-Speciale.
O primeiro pode competir com o GPT-5 de um lado para o outro, e a versão posterior de alto desempenho explodiu diretamente o GPT e começou a ter uma lacuna de 50-50 com o modelo de código fechado teto-Gemini.
Ele também ganhou medalhas de ouro em uma série de competições como IMO 2025 (Olimpíada Internacional de Matemática) e CMO 2025 (Olimpíada de Matemática da China).
Este é o nono modelo lançado pela empresa este ano, embora o tão aguardado R2 ainda não tenha chegado.
Então, como o DeepSeek usa dados menores e menos placas gráficas para criar um modelo que possa competir com gigantes internacionais?
Abrimos o jornal deles e queríamos explicar esse assunto claramente a todos.
Para atingir esse objetivo, DeepSeek implementou muitos truques novos:
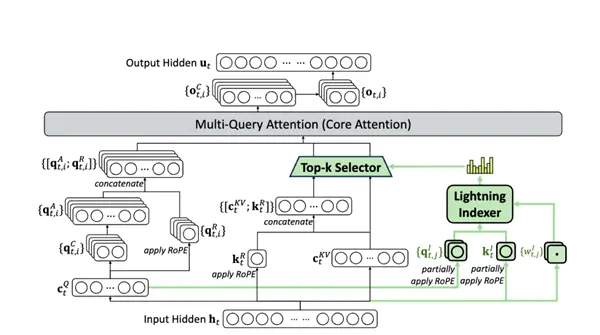
Primeiro, nosso velho amigo DSA - Dirty Attention se tornou normal.
Essa coisa apareceu na versão anterior V3.2-EXP. Naquela época, apenas testamos se o DSA afetaria o desempenho do modelo. Agora realmente colocamos isso no modelo principal.

Quando você costuma conversar com modelos grandes, descobrirá que quanto mais você conversa em uma caixa de diálogo, mais fácil será para a modelo falar bobagens.
Mesmo que falem demais, eles impedirão você de conversar diretamente.

Este é um problema causado pelo mecanismo de atenção nativo de modelos grandes. Sob a influência desta lógica antiga, cada token deve ser calculado em conjunto com cada token anterior.

Isso resulta na duplicação da sentença e no valor do cálculo do modelo que deve aumentar para quatro vezes. Se o comprimento do lado triplicar, o valor do cálculo será nove vezes maior, o que é muito problemático.
DeepSeek achou que isso não funcionaria, então adicionou um número fixo de páginas de diretórios (atenção escassa) ao modelo grande, o que equivale a ajudar o foco do modelo.
Depois de obter o índice, você só precisará calcular o relacionamento entre esse token e esses diretórios todas as vezes no futuro. É equivalente a ler primeiro o índice ao ler um livro. Depois de ler o índice, você pode determinar em qual capítulo está interessado e, em seguida, ler atentamente o conteúdo deste capítulo.
Desta forma, a capacidade dos grandes modelos de ler textos longos ficará mais forte.
Como você pode ver na imagem abaixo, à medida que as frases ficam cada vez mais longas, o custo de raciocínio da V3.1 tradicional torna-se cada vez maior.
Mas usando o 3.2 com pouca atenção, não há mudança...

Eu sou um super campeão de economia de dinheiro.
Por outro lado, DeepSeek começou a prestar atenção ao trabalho pós-treinamento de modelos de código aberto.
O processo de começar do pré-treinamento até a pontuação do teste para o modelo grande é, na verdade, um pouco como o processo de nós, humanos, começando do ensino fundamental e estudando até o vestibular.
O pré-treinamento anterior em grande escala equivale a ler todos os livros didáticos, cadernos e trabalhos do ensino fundamental ao segundo ano do ensino médio. Esta etapa é a mesma para todos. Quer se trate de um modelo de código fechado ou de código aberto, todos estão estudando honestamente.
Mas é diferente quando se trata da etapa sprint do vestibular. Na fase pós-treinamento do modelo, os modelos de código fechado costumam contratar professores famosos para aprimorar as questões, iniciar diversos aprendizados por reforço e, por fim, deixar o modelo obter bons resultados no teste.
No entanto, os modelos de código aberto gastam menos tempo nisso. De acordo com a DeepSeek, o investimento em computação dos modelos de código aberto anteriores no estágio pós-treinamento foi geralmente baixo.
Isso leva ao fato de que esses modelos podem ter capacidades básicas implementadas, mas há poucos problemas difíceis de resolver, resultando em pontuações baixas nos testes.
Portanto, desta vez, DeepSeek decidiu fazer aulas de reforço com professores famosos e desenvolveu um novo protocolo de aprendizagem por reforço. Após o pré-treinamento, ele gastou mais de 10% do poder computacional total do treinamento para fazer pequenas melhorias no modelo para compensar a peça que faltava.
Ao mesmo tempo, também foi lançada uma versão especial que pode pensar por muito tempo - DeepSeek V3.2 Speciale.
A ideia por trás disso é esta:
No passado, os modelos grandes tinham limitações no comprimento do contexto, por isso faziam algum trabalho de rotulagem e penalização durante o treinamento. Se o conteúdo do pensamento aprofundado do modelo fosse muito longo, pontos seriam deduzidos.
Quanto ao DeepSeek V3.2 Speciale, o DeepSeek simplesmente cancelou este item de dedução.Em vez disso, o modelo é encorajado a pensar por quanto tempo e como quiser.
No final, este novo DeepSeek V3.2 Speciale competiu com sucesso com o popular Gemini 3 há alguns dias.
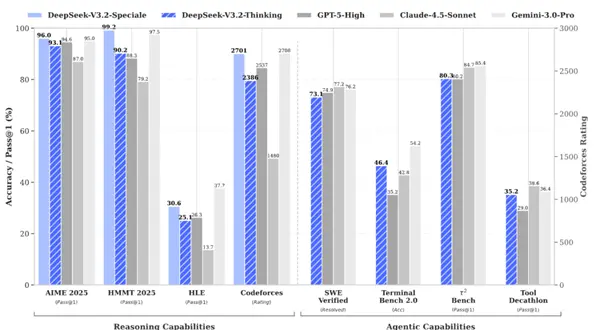
Além disso, DeepSeek também atribui grande importância à capacidade do modelo em termos de agentes inteligentes.
Por um lado, para melhorar as capacidades básicas do modelo, DeepSeek construiu um ambiente virtual e sintetizou milhares de dados para auxiliar no treinamento.
DeepSeek-V3.2 usa 24.667 tarefas de ambiente de código real, 50.275 tarefas de pesquisa reais, 4.417 cenários de agente geral sintético e 5.908 tarefas de interpretação de código real para pós-treinamento.

Por outro lado, DeepSeek também otimiza o processo de utilização de diversas ferramentas para o modelo.
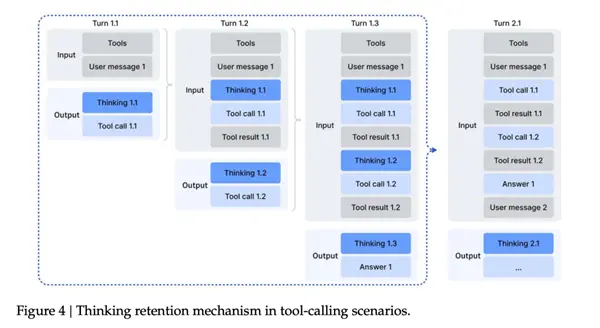
Um problema típico das gerações anteriores do DeepSeek é que ele separa o pensamento do uso de ferramentas.
Uma vez que o modelo chama uma ferramenta externa, o pensamento anterior está basicamente concluído e o trabalho está concluído. Quando a ferramenta volta após verificar os resultados, muitas vezes é necessário expor as ideias novamente.
Isso leva a uma experiência muito estúpida - mesmo que você verifique algo tão simples como "qual é a data de hoje", o modelo reconstruirá toda a cadeia de raciocínio do zero, o que é uma enorme perda de tempo...
Na V3.2, DeepSeek não aguentou mais e derrubou diretamente essa lógica e a refez.
As regras agora se tornam:Durante toda uma série de chamadas de ferramentas, o “processo de pensamento” do modelo será mantido. Somente quando o usuário enviar uma nova pergunta essa rodada de raciocínio será zerada; e os registros e resultados das chamadas da ferramenta permanecerão no contexto, como os registros do bate-papo.
Através dessas três etapas de modificação da arquitetura do modelo, prestando atenção ao pós-treinamento e fortalecendo as capacidades do Agente, DeepSeek finalmente deu ao seu novo modelo a capacidade de competir novamente com os principais modelos de código aberto do mundo.
É claro que mesmo com tantas melhorias, o desempenho do DeepSeek não é perfeito.
Mas o que Tony mais gosta no DeepSeek é a disposição de admitir suas deficiências.
E isso será escrito diretamente no papel.
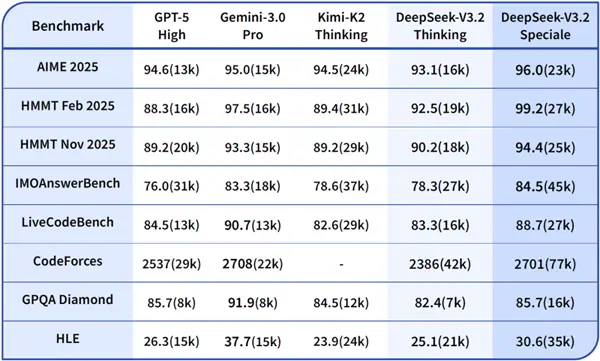
Por exemplo, este artigo mencionou que desta vez o DeepSeek V3.2 Speciale pode competir 50-50 com o Gemini 3 Pro do Google.

Mas para responder à mesma pergunta, o DeepSeek precisa gastar mais tokens.
Eu também testei, selecionei aleatoriamente uma pergunta do banco de questões do "Exame Final da Humanidade" e joguei-a nos dois modelos Gemini 3 Pro e DeepSeek V3.2 Speciale ao mesmo tempo.

O tópico é:
Os beija-flores são únicos entre os podomorfos por possuírem ossos ovais pareados bilateralmente, um osso caudal embutido na aponeurose cruzada expandida que deprime os ossos multigrãos. Quantos pares de tendões esse osso sesamóide suporta? Por favor responda com números.
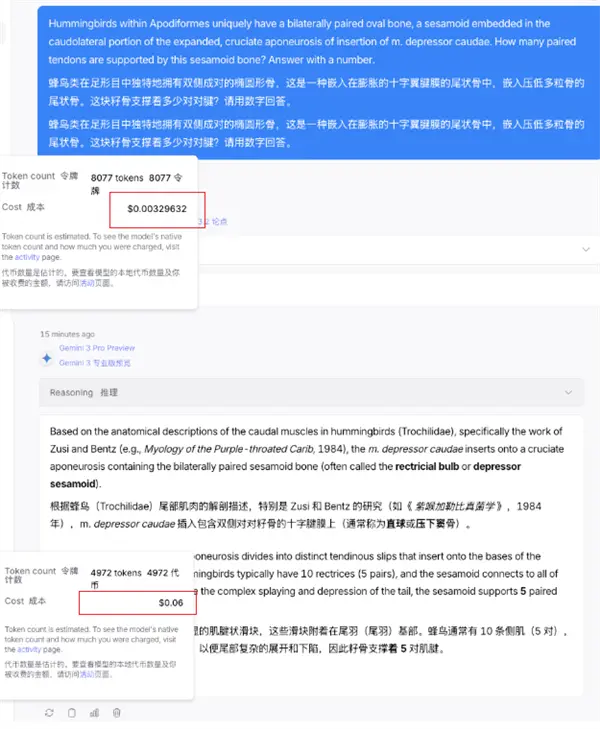
Acontece que Gêmeos só precisa de 4.972 Tokens para responder à pergunta.

Quanto ao DeepSeek, foram necessários 8.077 tokens para descobrir o problema.

Olhando apenas para o uso, o consumo de tokens do DeepSeek é quase 60% maior, o que é realmente uma grande lacuna.
Mas então novamente.
Embora o DeepSeek consuma muitos tokens, seu preço é barato...
Ainda fazendo a mesma pergunta, olhei novamente para a conta com atenção.
DeepSeek mais de 8.000 tokens e me custou US$ 0,0032.
Mas do lado do Google, custou-me menos de 5.000 tokens, mas custou US$ 0,06? Isso é 20 vezes maior que o DeepSeek.
Dessa perspectiva, sinto que o DeepSeek é melhor...
Por fim, voltemos ao início do artigo.
Como disse DeepSeek, a lacuna entre os modelos de código aberto e os modelos de código fechado tem aumentado nos últimos seis meses.

Mas eles ainda usam seu próprio caminho para compensar essa lacuna.
As várias operações de economia de energia e dados do DeepSeek realmente me lembraram de uma entrevista com Ilya Sutskever no mês passado.

A antiga alma da OpenAI acredita que não há futuro apenas adicionando parâmetros cegamente ao modelo.
AlexNet usa apenas duas GPUs. Quando o Transformer apareceu pela primeira vez, a escala dos experimentos estava principalmente na faixa de 8 a 64 GPUs. Pelos padrões atuais, isso equivale ao tamanho de várias GPUs, e o mesmo vale para o ResNet.Nenhum artigo pode ser concluído sem um enorme cluster.
Comparada com o acúmulo de poder computacional, a pesquisa sobre algoritmos é igualmente importante.
Isso é exatamente o que o DeepSeek está fazendo.
Do MoE do V2 à atenção latente de múltiplas cabeças (MLA) do V3, ao mecanismo de autoverificação do DeepSeek Math V2 atual, a atenção escassa (DSA) do V3.2.
DeepSeek nos mostra o progresso, que nunca é singular e depende da melhoria proporcionada pelo empilhamento da escala de parâmetros.
Em vez disso, estamos a pensar em formas de utilizar dados limitados para acumular mais inteligência.
Uma mulher inteligente faz papel de boba
Então, quando o R2 chegará?