DeepSeek está redefinindo os limites da inclusão de grandes modelos. Em 26 de abril, a DeepSeek lançou oficialmente um anúncio de ajuste de preço da API. O preço de todos os acessos ao cache de entrada da API foi reduzido para um décimo do preço inicial. A atualização V4-Pro tem 25% de desconto por tempo limitado, e os acessos ao cache de entrada de um milhão de tokens chegam a 0,025 yuan, estabelecendo um novo mínimo no preço de modelos grandes no mundo.

De acordo com o anúncio na página oficial de preços da API do DeepSeek, esta redução de preço cobre todos os modelos da série V4, e os principais ajustes se concentram em cenários de acerto do cache de entrada. Entre eles, o preço de acerto do cache de entrada DeepSeek-V4-Flash caiu de 0,2 yuan/milhão de tokens para 0,02 yuan/milhão de tokens.
DeepSeek-V4-Pro para usuários de nível empresarial tem descontos ainda maiores. O preço original de 1 yuan/milhão de tokens foi reduzido para 0,1 yuan para entrada de cache. Uma oferta especial de 25% de desconto por tempo limitado será adicionada antes de 5 de maio de 2026, o que na verdade equivale a apenas 0,025 yuan/milhão de tokens. A entrada de falta de cache foi reduzida de 12 yuans para 3 yuans, e a saída foi reduzida de 24 yuans para 6 yuans.
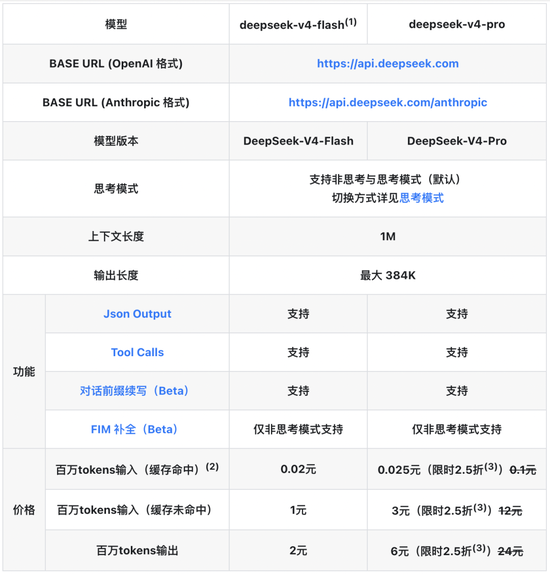
Fonte da imagem: site oficial do DeepSeek
DeepSeek mencionou que os dois nomes de modelos DeepSeek-Chat e DeepSeek-Reasoner serão descontinuados no futuro. Por razões de compatibilidade, os dois correspondem aos modos de não pensar e pensar do DeepSeek-V4-Flash, respectivamente.
Comparando os preços antes e depois do reajuste de preços, é fácil descobrir que o custo das chamadas de alta frequência e dos cenários de processamento de texto longo caiu mais de 90%. Aplicativos com altas taxas de acerto de cache, como base de conhecimento RAG, atendimento inteligente ao cliente e análise de documentos, podem realizar diretamente uma queda abrupta nos custos comerciais, ajudando a quebrar as amarras de custos da implementação de IA em larga escala.
A redução significativa de preço do DeepSeek está relacionada à atualização tecnológica do DeepSeek‑V4 e à colaboração profunda com o ecossistema Shengteng.
Em 24 de abril, a versão prévia do DeepSeek‑V4 foi lançada oficialmente. Os modelos Pro e Flash de código aberto suportam contextos ultralongos de 1 milhão de tokens. A arquitetura de atenção esparsa autodesenvolvida reduz bastante o consumo de poder de computação de inferência. O poder de computação de token único da versão Pro é de apenas 27% da V3.2, e o cache KV é reduzido para 10%, alcançando otimização de custos de baixo para cima.
Os parâmetros anunciados pelo DeepSeek mostram que o DeepSeek‑V4‑Pro possui parâmetros de ativação de 49B e dados de pré-treinamento de 33T, posicionando-o como um carro-chefe de alto desempenho; DeepSeek‑V4‑Flash possui parâmetros de ativação de 13B e dados de pré-treinamento de 32T, com foco em alta velocidade e baixo custo.
Em comparação com o modelo da geração anterior, os recursos do agente do DeepSeek-V4-Pro foram significativamente aprimorados. Na avaliação de Agentic Coding, o V4-Pro alcançou o melhor nível dos modelos de código aberto atuais e também teve um bom desempenho em outras avaliações relacionadas a agentes. É relatado que DeepSeek-V4 se tornou o modelo de codificação Agentic usado pelos funcionários internos da DeepSeek. De acordo com o feedback da avaliação, a experiência de uso é melhor do que o Sonnet 4.5, e a qualidade de entrega está próxima do modo não-pensativo de Claude Opus 4.6, mas ainda há uma certa lacuna com o modo de pensamento do Opus 4.6.
Na avaliação do conhecimento mundial, DeepSeek-V4-Pro está significativamente à frente de outros modelos de código aberto e ligeiramente inferior ao modelo de código fechado Gemini-Pro-3.1. Na avaliação de matemática, STEM e códigos competitivos, o DeepSeek-V4-Pro superou todos os modelos de código aberto atualmente avaliados publicamente e foi comparável aos principais modelos de código fechado do mundo.
Comparado com o DeepSeek-V4-Pro, o DeepSeek-V4-Flash é ligeiramente inferior em termos de reserva de conhecimento mundial, mas mostra capacidades de raciocínio próximas. Como os parâmetros e ativações do modelo são menores, o V4-Flash pode fornecer serviços de API mais rápidos e econômicos.
DeepSeek-V4 também foi pioneiro em um novo mecanismo de atenção que comprime a dimensão do token e o combina com a atenção esparsa do DSA (DeepSeek Sparse Attention) para obter recursos de contexto longo líderes mundiais e reduzir significativamente os requisitos de computação e memória gráfica em comparação com os métodos tradicionais.
O que é ainda mais digno de nota é que toda a gama de produtos de super nós Ascend suporta os modelos da série DeepSeek V4. Isso também significa que o DeepSeek libera mais sinais de localização.
DeepSeek-V4 mencionado em um relatório técnico: "O esquema EP (Expert Parallel) refinado foi verificado em duas plataformas, GPU NVIDIA e Huawei Ascend NPU. Comparado com a poderosa linha de base não fundida, o esquema alcançou aceleração de 1,50-1,73 vezes em tarefas de raciocínio geral; em cenários sensíveis à latência (como implementação de aprendizagem por reforço (RL) e serviços de agente de alta velocidade), ele pode atingir até 1,96 vezes de aceleração."
DeepSeek enfatizou que, à medida que toda a gama de produtos de super nós Ascend for lançada em lotes no segundo semestre do ano, espera-se que o preço da versão Pro seja significativamente reduzido.
Após o lançamento do DeepSeek-V4, a Goldman Sachs divulgou um relatório de análise apontando que o principal significado do DeepSeek V4 é apoiar a implementação de aplicações de agentes mais complexas a um custo menor, abrindo assim um novo espaço para a escala de aplicações de IA. No que diz respeito à inclusão dos super nós Ascend, a Goldman Sachs acredita que a competitividade de custos do DeepSeek será ainda mais fortalecida, criando condições para uma gama mais ampla de aplicações. Além disso, num contexto de aperto contínuo dos chips, a tendência de migração dos principais modelos de IA da China para o poder de computação nacional foi claramente endossada pelos principais intervenientes.
O relatório do Goldman Sachs também citou notícias de que Tencent e Alibaba estão negociando para investir na DeepSeek em uma avaliação de mais de US$ 20 bilhões. Os valores de mercado mais recentes da Zhipu e MiniMax são de aproximadamente US$ 53 bilhões e US$ 31 bilhões, respectivamente. Esta transação potencial reflete a lógica da competição dos gigantes pelas escassas capacidades de IA de alto nível.
A Huatai Securities acredita que o mercado interpreta facilmente V4 como "redução de custos e redução de poder de computação e requisitos de armazenamento", mas a mudança marginal mais importante é que após a diminuição do custo do contexto longo, a disponibilidade de agentes complexos, análise de vários documentos, tarefas de longo prazo, aprendizagem on-line e outros cenários aumentarão, e espera-se que o número de chamadas de inferência e a frequência de acesso ao armazenamento aumentem.