Ainda hoje, a lista mais recente do Code Arena foi divulgada! Qwen3.7-Max ficou entre os quatro primeiros do mundo com 1.541 pontos, ultrapassando GPT-5.5, Gemini 3.5 Flash e outros modelos top de uma só vez. Os únicos que restam à sua frente são Claude Opus 4.7 e Opus 4.6.
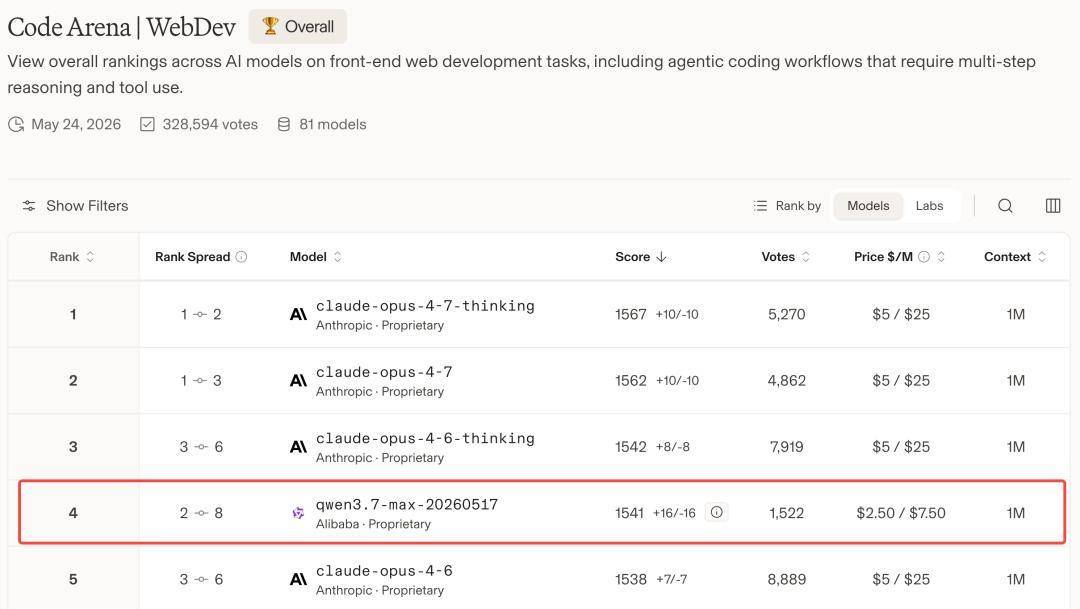
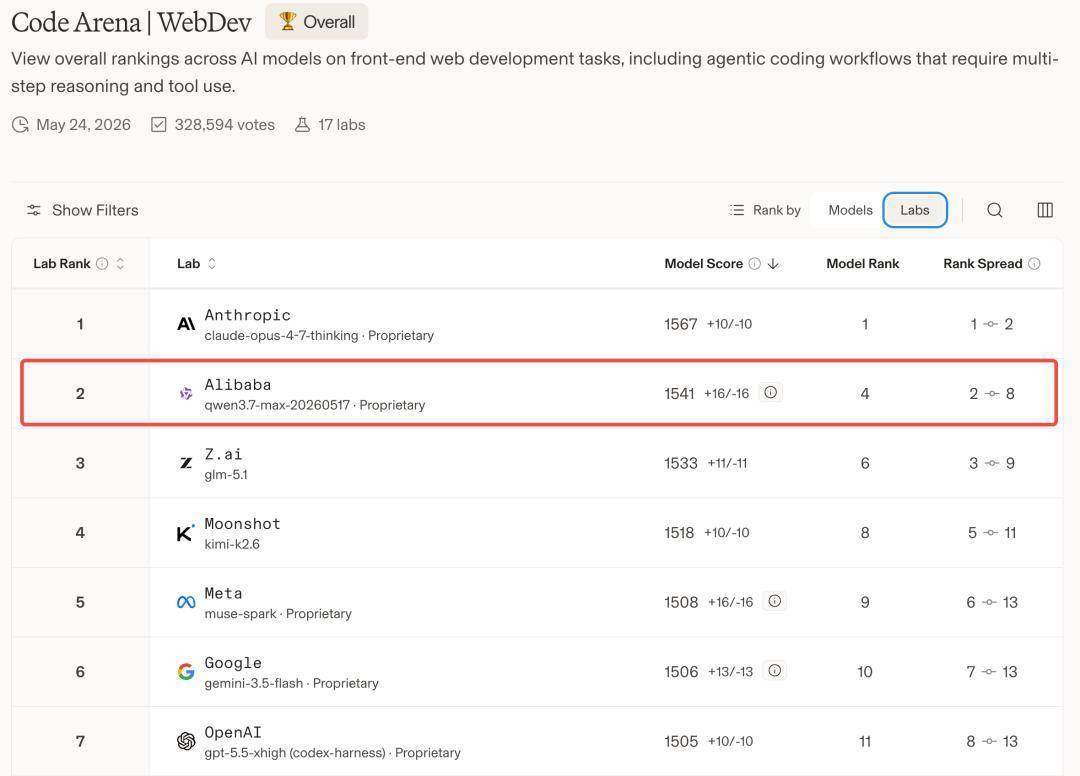
Ou seja, na arena do modelo de programação global, o Alibaba é o único fabricante chinês a entrar na tabela, ficando atrás apenas da Anthropic.
Qwen3.7-Max entra entre os cinco primeiros do mundo
O único modelo não-Claude
Na verdade, antes de Code Arena divulgar a lista, Qwen3.7-Max já havia se tornado famoso no círculo de desenvolvedores estrangeiros.
O Atomic Chat conduziu uma comparação direta, permitindo que Opus 4.7, GPT-5.5 e Qwen3.7-Max competissem no mesmo palco. A tarefa era escrever uma IA de Tetris que pudesse treinar sozinha.
Como resultado, o Qwen3.7-Max não apenas superou o Opus 4.7 e o GPT-5.5 com um custo simbólico de apenas US$ 1,32, mas também melhorou o desempenho em 56%.

Outro desenvolvedor estrangeiro escolheu Qwen3.7-Max para construir um modelo 3D do universo, e o efeito pode ser descrito como chocante.

Na tarefa de geração do "modelo de pagode em miniatura de vento de pixel 3D", a velocidade de saída e a qualidade do Qwen3.7-Max também venceram de forma abrangente.

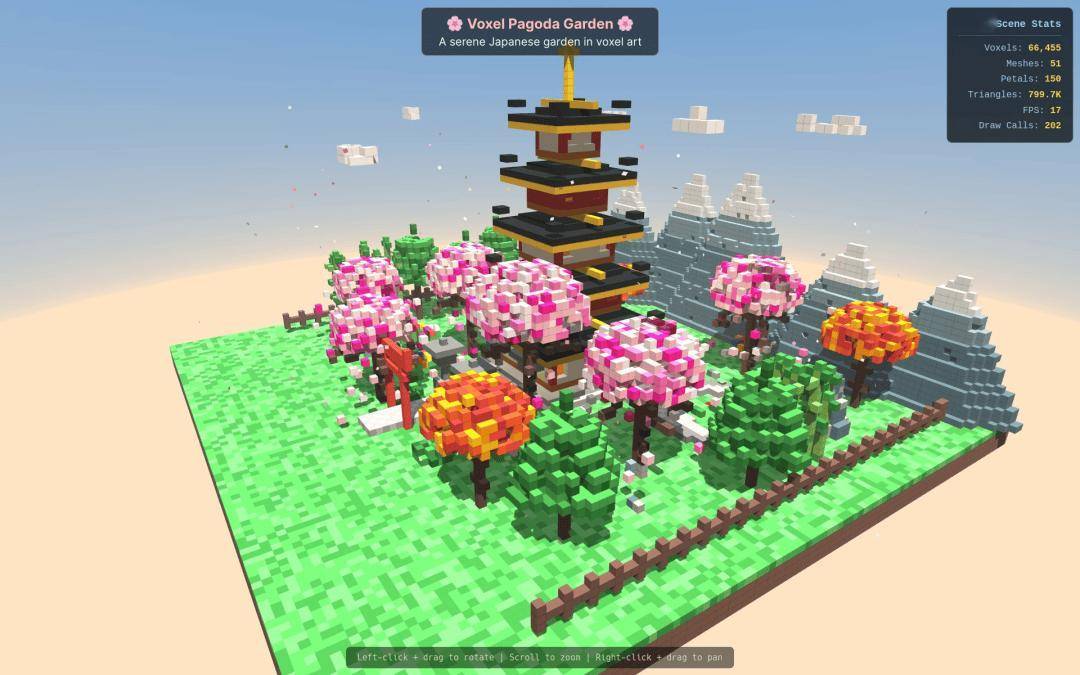
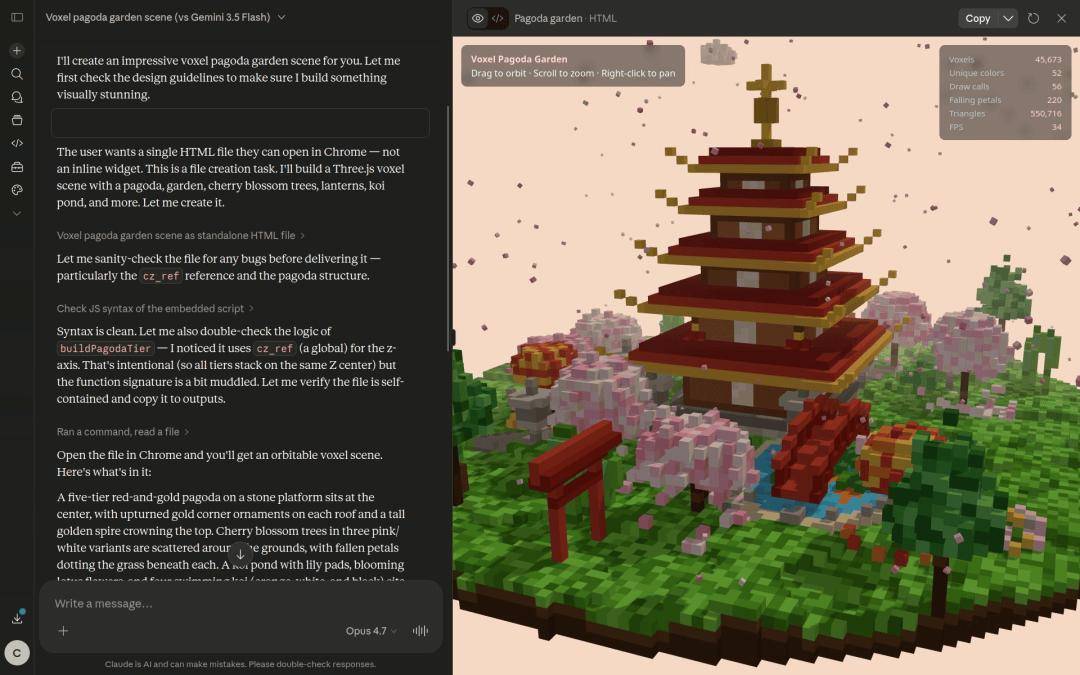
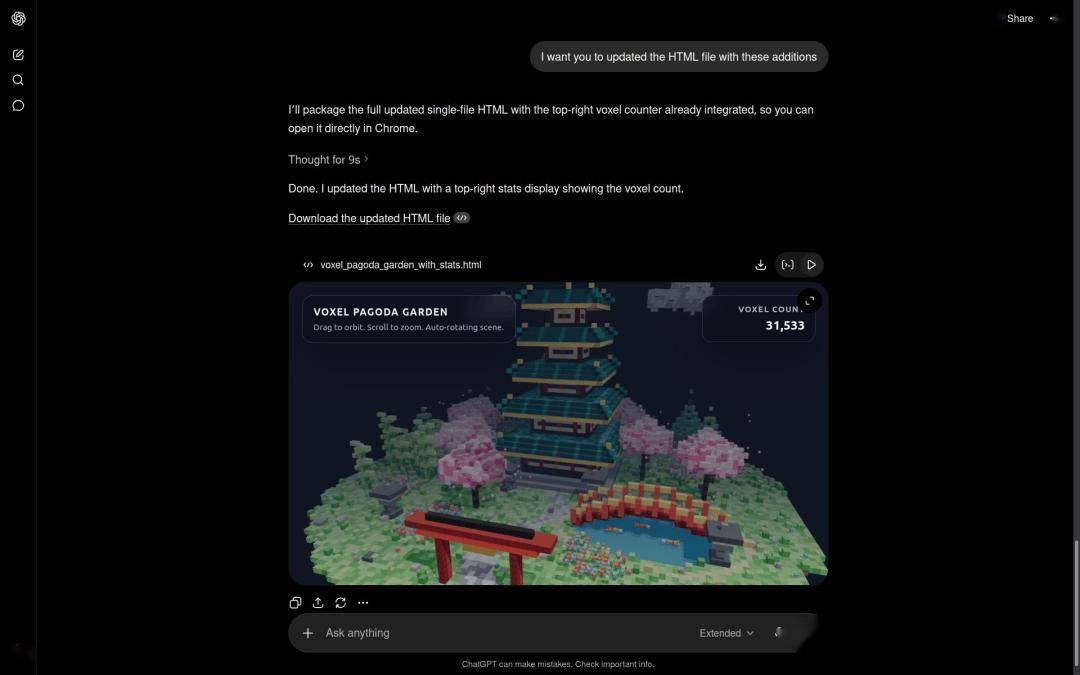
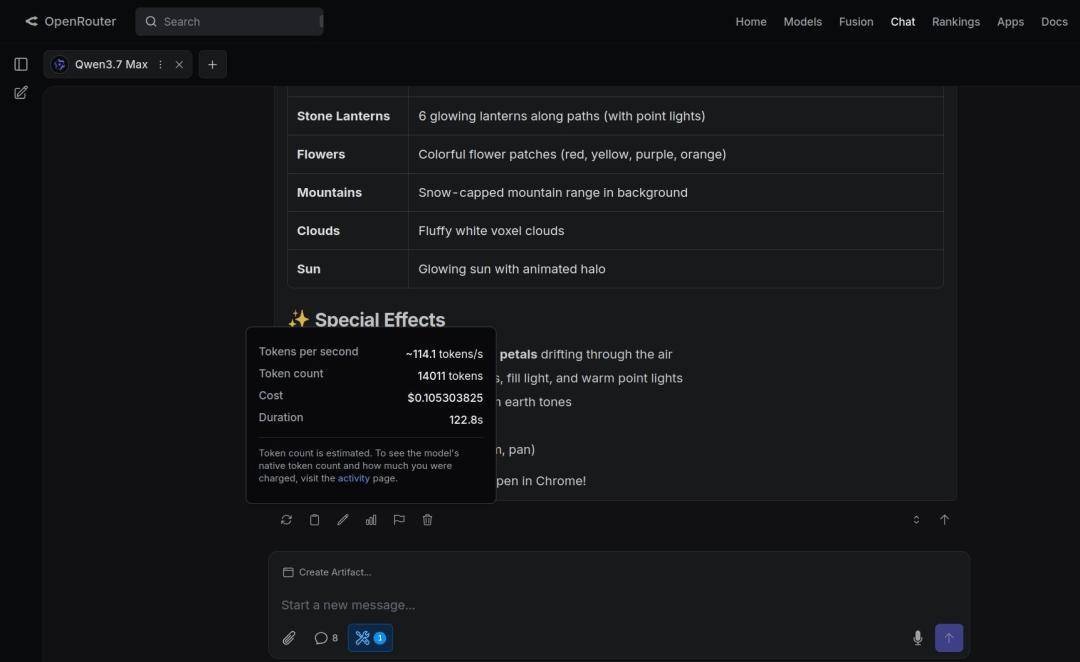
sobre
O desenvolvedor Paul Couvert até elogiou que depois que o Qwen3.7-Max estiver conectado ao Hermes Agent e ao OpenCode, ele poderá basicamente substituir o GPT-5.5 e o Opus 4.7.
A programação é tão incrível
No entanto, não importa quão alta seja a pontuação da corrida, é melhor praticar com espadas e armas reais.
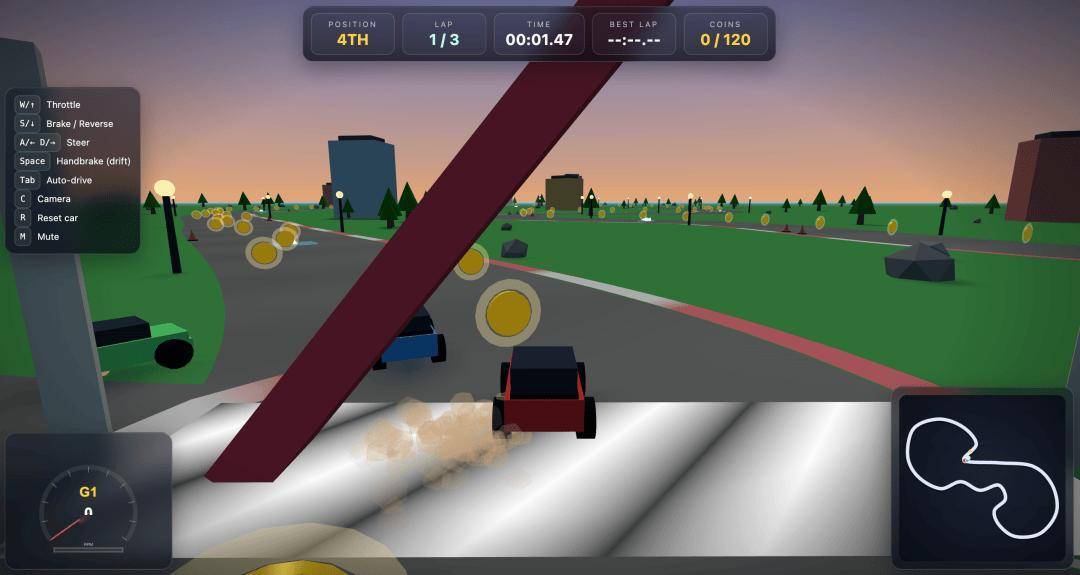
Organizamos um desafio difícil de "jogo de corrida" para Qwen3.7-Max.
Adicione um prompt detalhado e, depois de um tempo, Qwen3.7-Max produzirá diretamente um arquivo HTML reproduzível.

Houve um pequeno bug na primeira versão, as teclas de direção A/D estavam invertidas para a esquerda e para a direita.
Mas após a segunda rodada de ajustes simples de diálogo, foi lançado um jogo de corrida 3D com uma experiência completa.

No momento em que abri, para ser sincero, fiquei um pouco chocado.
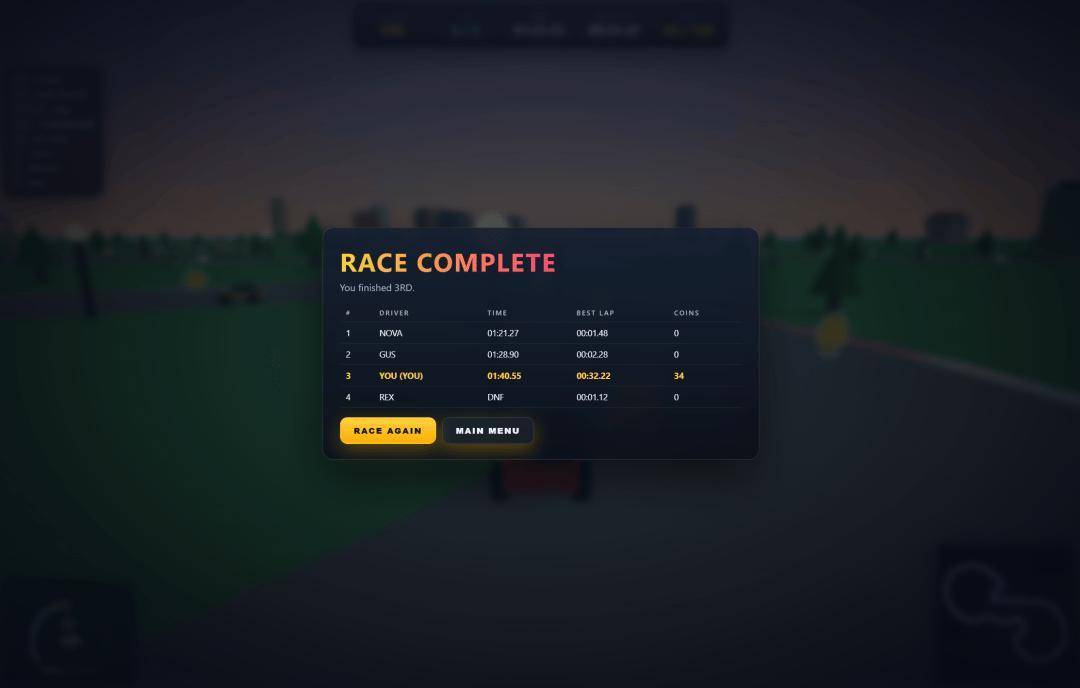
4 carros estão no mesmo palco, correndo em uma pista circular de 3 voltas. Existem mais de 100 moedas de ouro espalhadas pela pista. Se encontrar obstáculos, você diminuirá a velocidade e perderá o controle.
O painel de resultados pós-corrida inclui classificação, tempo, número de moedas de ouro e volta mais rápida.
Mas o que é realmente surpreendente são dois detalhes que apenas o Qwen3.7-Max consegue alcançar.
Uma é a interface inicial. Depois que os quatro modelos foram testados horizontalmente, apenas ele criou uma página inicial séria para o jogo, e você clicou em “Iniciar” para entrar na competição. Os outros três estão todos abertos e rodando, sem sequer tela de título.
Outro são os efeitos sonoros. Ao final do prompt, houve um pedido, além dos efeitos sonoros do motor roncando e das moedas de ouro sendo comidas. Entre os quatro modelos, é o único que incorpora esse bônus, com sons de motor e jingles de moedas de ouro todos organizados.
Vejamos o desempenho de outros jogadores.
A imagem do Gemini 3.5 Flash é obviamente um pouco mais fina, sem aquela sensação tridimensional vívida.
Também há problemas com o layout da IU. As informações do painel estão espalhadas nos quatro cantos da tela e o foco visual está espalhado.
Em contraste, o método de processamento do Qwen3.7-Max consiste em concentrar os principais indicadores no centro da tela, o que está mais alinhado com o ponto de pouso natural da linha de visão do jogador.

O efeito de Claude Opus 4.6 é um pouco difícil de descrever.
Não só há poucas moedas de ouro na pista, mas os três carros de IA estão dirigindo quase simultaneamente, sem nenhuma aleatoriedade, como se tivessem sido copiados e colados.
Finalmente, existe o GPT-5.5.
Pode-se observar que a qualidade da imagem é realmente muito melhor que as duas anteriores e o funcionamento é mais suave.
Mas não sei porquê, as moedas de ouro foram transformadas em “donuts” amarelos…
O estilo é uma questão trivial. A chave é que Gemini, Claude e ChatGPT tiveram que corrigir várias rodadas de bugs antes que pudessem executar todas as funções.
Apenas as conquistas da primeira rodada da geração Qwen3.7-Max são basicamente jogáveis.
As pontuações atuais são próximas, o teste real é preciso e o preço é apenas uma fração do preço. As conclusões restantes são deixadas para os desenvolvedores votarem com os pés.
O modelo “pedestal” na era do Agente
A resposta para o motivo pelo qual o Qwen3.7-Max é capaz de ter um desempenho de tão alto nível na área de programação mais exigente está no posicionamento de seu produto.
Há poucos dias, quando o Alibaba lançou o Qwen3.7-Max, deu-lhe um rótulo muito especial:Modelo base de agente.
Nasceu paraExecute tarefas de forma autônoma por longos períodos de tempoModelo de projeto.
Dados de testes internos mostram que em uma tarefa de programação independente, o Qwen3.7-Max funcionou continuamente por 35 horas e executou 1.158 chamadas de ferramenta.
O código final gerado atinge uma surpreendente aceleração média geométrica de 10x em comparação com a implementação de referência Triton.
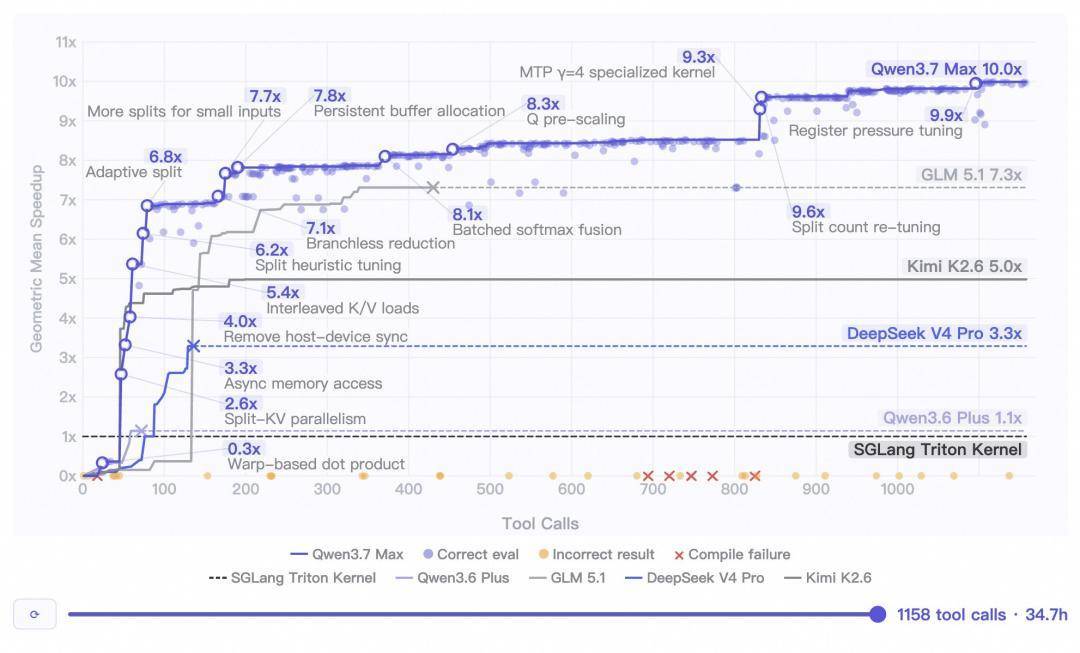
O que é ainda mais chocante é a sua capacidade de “guerra prolongada”——
Após a 30ª hora da dedução, o modelo permaneceu nítido e continuou a explorar novo espaço de otimização.
Zero degradação de contexto, zero desvio de instrução e zero loops infinitos em todo o processo!
Devo dizer que a dificuldade neste assunto não é a própria ferramenta 1000. Após o lançamento do protocolo MCP, não é incomum ajustar as ferramentas 1.000 vezes.
A dificuldade está em 35 horas de raciocínio coerente.
A maioria dos modelos entrará em colapso ao executar tarefas longas: ou o contexto se acumula e se torna confuso, e as metas estabelecidas na primeira metade são completamente esquecidas mais tarde; ou entram em um loop infinito e tentam repetidamente a mesma solução que falhou.
Qwen3.7-Max alcançou o objetivo de “fazer continuamente a coisa certa”.
Tecnologia central revelada
Salto de programação do Qwen3.7-Max, entendemos que o núcleo pode estar relacionado à atualização de dois métodos de treinamento.
primeirosim,Expansão ambiental.
Quando Qwen3.7-Max estiver fazendo treinamento de programação, cada tarefa será dividida em três dimensões independentes, a tarefa em si, a estrutura de execução e o método de verificação, e os três podem ser combinados livremente.
A mesma pergunta às vezes é feita na estrutura do Claude Code, às vezes no OpenClaw e às vezes usando outro método de verificação.
O efeito é como se um estagiário fosse transferido para todas as equipes do projeto. O que é forçado a aprender é uma estratégia geral para resolver problemas, e não “como tirar vantagem de uma estrutura específica”.
Isso explica um fenômeno contra-intuitivo. O desempenho do Qwen3.7-Max nas estruturas de Claude Code, OpenClaw e Qwen Code é muito estável e não há situação em que "é muito forte em sua própria estrutura, mas será estranho se você alterá-lo".

A segunda atualização é,Execução autônoma de longo alcance.
Durante o treinamento, a equipe introduziu a estrutura do “jogo dinâmico de sobrevivência cumulativa”.
Ou seja, deixe o modelo tomar mais de mil etapas de decisões contínuas em um ambiente de simulação em constante mudança, estabelecer suas próprias suposições, ajustar estratégias com base no feedback e não causar "corrupção de contexto" porque é executado por muito tempo.
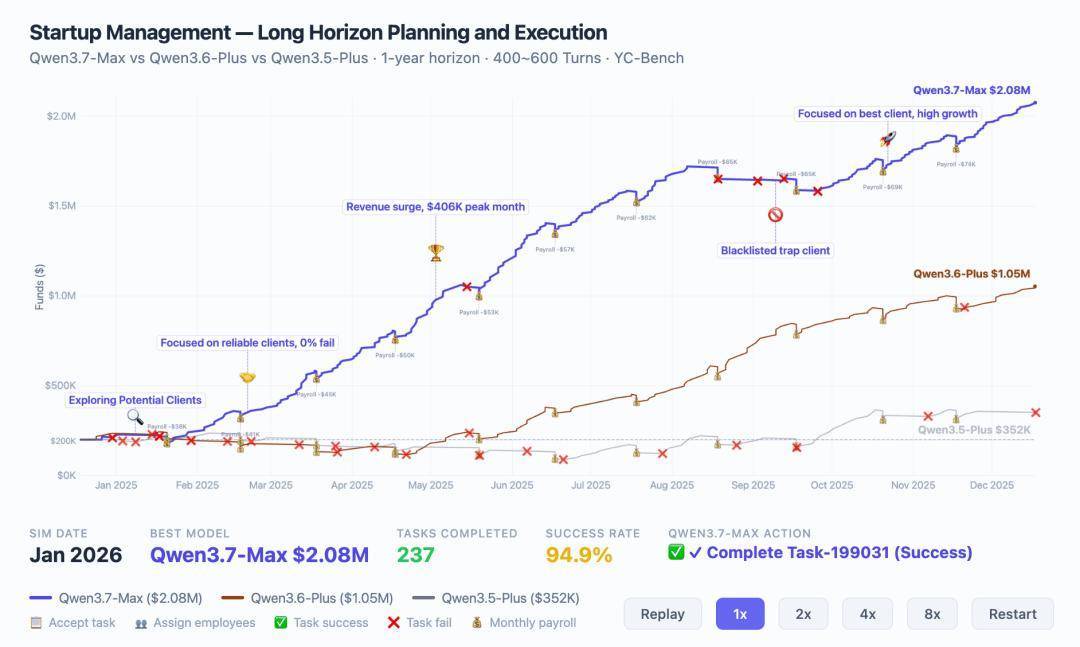
Aqui estão alguns dados intuitivos. YC-Bench simula o funcionamento de uma empresa startup durante um ano inteiro. Qwen3.7-Max obteve receita de 2,08 milhões de dólares americanos, o dobro da geração anterior (1,05 milhão).
Mais importante ainda, mostra a evolução da sua estratégia. Ele pode ajustar sua direção de forma independente ao enfrentar uma crise no médio prazo, identificar e bloquear clientes mal-intencionados e, finalmente, convergir para um ciclo de execução estável.
Este é o suporte subjacente para o caso de otimização do kernel de 35 horas e é por isso que no Kernel Bench L3, Qwen3.7-Max pode obter efeitos de aceleração em 96% dos cenários.
E a programação é apenas o primeiro campo de batalha. A base deste conjunto de raciocínios e ferramentas de longo alcance aponta para uma ambição maior – uma base universal de Agentes.
Tem mais um spoiler nas finais da programação
Desde o lançamento do Code Arena, o teste sempre foi um trabalho árduo. Raciocínio em várias etapas, orquestração de ferramentas e entrega completa do projeto são habilidades reais no nível do agente.
Hoje, Qwen3.7-Max passou para a quarta posição com uma pontuação de 1.541 pontos, ficando entre o Opus 4.6 Thinking e o Opus 4.6.
Nesta pista onde Claude domina há mais de meio ano, deu a sua própria resposta. Os modelos chineses não são apenas caçadores, mas também podem ser definidores.
A competição global de modelos de programação não é mais um espetáculo individual no Vale do Silício.