Na conferência Cloud Next da semana passada, o Google anunciou que o modelo Gemini 2.5 Flash chegará em breve e trará melhorias significativas. Hoje, o Google anunciou a visualização do Gemini 2.5 Flash na API Gemini por meio do Google AI Studio e Vertex AI. Este novo modelo também está disponível para usuários Gemini através do seletor de modelos e funciona com Canvas para otimizar facilmente documentos e códigos.

Seguindo a geração anterior Gemini 2.0 Flash, o Gemini 2.5 Flash melhorou significativamente os recursos de inferência, reduzindo custos e latência. O Google afirma que este novo modelo tem uma excelente relação custo-benefício. Os preços específicos são os seguintes:
US$ 0,15 por 1 milhão de tokens de entrada
por 1 milhão de saídaselemento de palavraCobrar $ 0,60 (sem necessidade de fundamentação)
US$ 3,50 por 1 milhão de tokens de saída (incluindo inferência)
Esta é uma versão inicial do Flash 2.5, mas já apresenta enormes melhorias de desempenho em relação à versão Flash 2.0.
Se desejar, você pode desativar totalmente o recurso think e usar este modelo como um substituto imediato para o Flash 2.0.
Está disponível nos aplicativos Gemini API, AI Studio, Vertex e Gemini!
- Logan Kilpatrick (@OfficialLoganK)
Gemini 2.5 Flash é o primeiro modelo de inferência totalmente híbrido do Google, permitindo que os desenvolvedores optem por ativar ou desativar a inferência. Diz-se que isso ajuda os desenvolvedores a otimizar as respostas com base na qualidade, custo e latência alvo. Confira abaixo os benchmarks deste novo modelo.
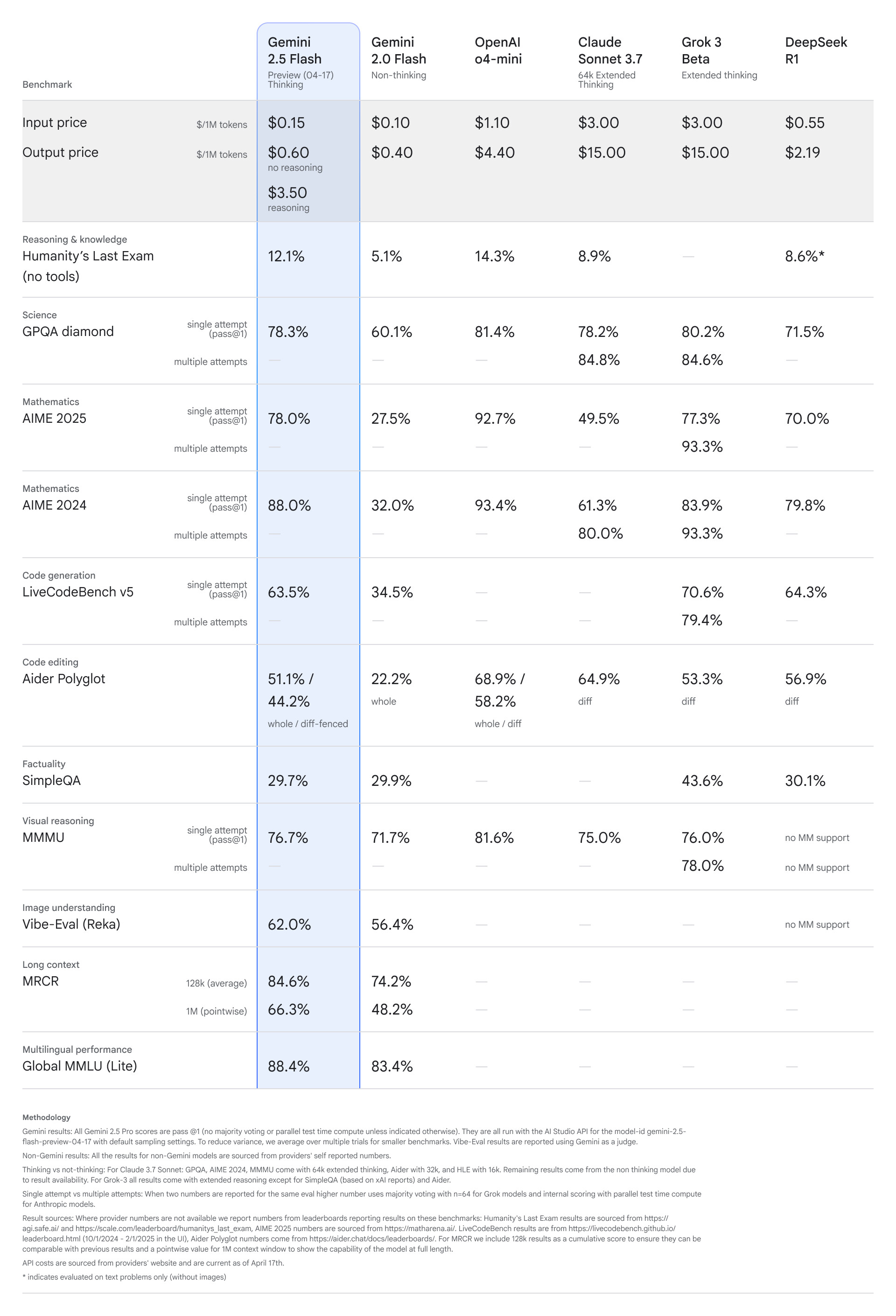
Como mostra a tabela acima, apesar do baixo custo, o Gemini 2.5 Flash ainda parece resistir aos modelos de ponta da Anthropic e Grok. O o4-mini lançado recentemente da OpenAI parece ter um desempenho melhor do que a visualização do Gemini 2.5 Flash, mas o preço é muito mais alto.