O Google lançou hoje oficialmente o Gemini 3.1 Flash-Lite, alegando que é o modelo mais rápido e econômico da série Gemini 3. Ele também disse que o 3.1 Flash-Lite foi projetado para cargas de trabalho de grande escala e alto rendimento de desenvolvedores e demonstra qualidade extremamente alta em sua faixa de preço e nível de modelo.
A partir de hoje, o Flash-Lite 3.1 estará disponível como uma prévia para desenvolvedores por meio da interface Gemini no Google AI Studio e estará disponível para usuários corporativos por meio do Vertex AI.
3.1 Flash-Lite custa US$ 0,25 por milhão de tokens de entrada (tokens de entrada) e US$ 1,50 por milhão de tokens de saída (tokens de saída). De acordo com o teste de benchmark da Artificial Analysis, o 3.1 Flash-Lite tem um desempenho melhor que o 2.5 Flash, mantendo a mesma qualidade ou superior. Sua velocidade de resposta da primeira palavra (Time to First Answer Token) aumentou 2,5 vezes e a velocidade de saída também aumentou 45%. O Google afirma que esse recurso de baixa latência é essencial para fluxos de trabalho de alta frequência, tornando-o um modelo ideal para os desenvolvedores criarem experiências responsivas e em tempo real.
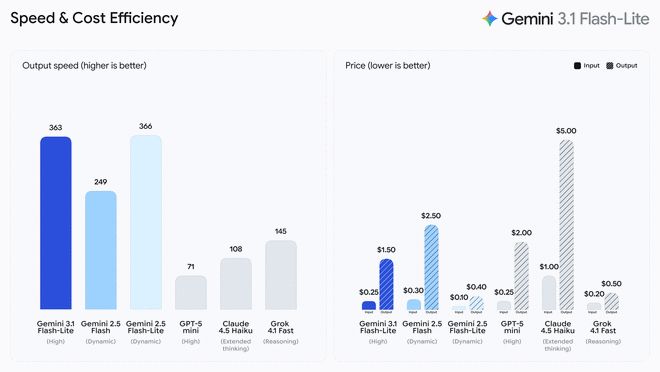
3.1 Flash-Lite marcou 1.432 pontos na tabela de classificação Arena.ai. Em diversos testes de benchmark de raciocínio e compreensão multimodal, seu desempenho supera outros modelos do mesmo nível. Por exemplo, alcançou uma pontuação de 86,9% no teste GPQA Diamond e 76,8% no teste MMMU Pro. Esse desempenho supera até mesmo as gerações anteriores de modelos maiores, como o 2.5 Flash.
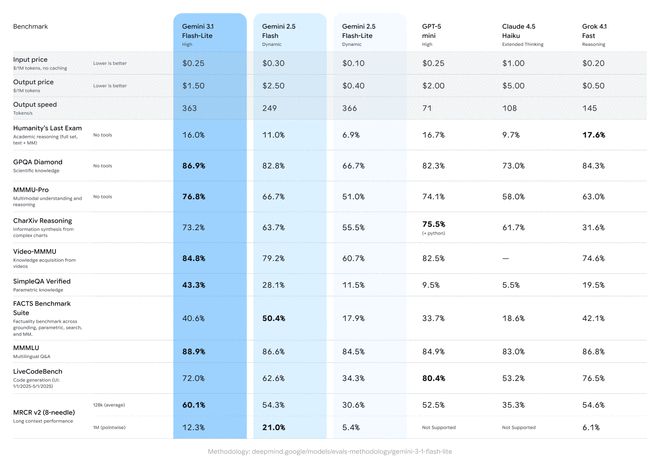
Além do desempenho nativo, o Gemini 3.1 Flash-Lite também vem com a funcionalidade "Thinking Level" no AI Studio e Vertex AI. Isso dá aos desenvolvedores a flexibilidade de controlar o quão profundamente seus modelos “pensam” em tarefas específicas, o que é fundamental para gerenciar cargas de trabalho de alta frequência. 3.1 O Flash-Lite é capaz de lidar com tarefas de grande escala, como tradução de alto volume e moderação de conteúdo com alto custo. Ao mesmo tempo, também é capaz de realizar tarefas complexas que exigem raciocínio profundo, como gerar interfaces de usuário e painéis, criar ambientes de simulação e seguir instruções complexas.
O Google disse que os desenvolvedores de acesso antecipado do AI Studio e Vertex AI, bem como empresas como Latitude, Cartwheel e Whering, já estão usando o 3.1 Flash-Lite para resolver problemas complexos em escala. Os primeiros testadores destacaram a eficiência e os recursos de inferência do 3.1 Flash-Lite. Eles disseram que o modelo pode lidar com entradas complexas com a precisão de modelos de grande escala, e pode seguir rigorosamente as instruções e manter um alto grau de consistência.