A versão prévia do DeepSeek-V4 foi finalmente lançada. Hoje, DeepSeek anunciou oficialmente que dois modelos, deepseek-v4-pro e deepseek-v4-flash, com contexto ultralongo de um milhão de palavras, foram lançados e de código aberto. A partir de agora, você pode fazer login no site oficial ou no aplicativo oficial para conversar com o DeepSeek-V4 mais recente e explorar a nova experiência de memória de contexto ultralonga de 1 milhão (milhão). O serviço API foi atualizado simultaneamente.

Artigo 丨 Coluna "BUG" Zhou Wenmeng

De acordo com o teste de benchmark oficial, em termos de comprimento de contexto, conhecimento, raciocínio e capacidades do agente, DeepSeek O desempenho do V4 é comparável ao principal código fechado internacional modelos e atingiu o nível de primeira classe de modelos internacionais de código aberto. Uma comparação na coluna "BUG" descobriu que em termos de preços de chamadas de API, a versão V4 do DeepSeek, que sozinha impulsionou cortes de preços na indústria doméstica de grandes modelos no ano passado, mais uma vez estabeleceu o "preço mais baixo" do setor.
"Embora o preço de compra por milhão de tokens de modelos domésticos não tenha caído muito, a longa duração do contexto e o bom desempenho proporcionam uma vantagem muito competitiva!" Alguns insiders expressaram seus sentimentos durante a comunicação com a coluna "BUG" Arrependimento: "Aquele grande açougueiro de preços de modelos está de volta!"De acordo com a introdução oficial do DeepSeek, a série V4 inclui duas versões do modelo: DeepSeek-V4-Pro com parâmetros totais de 1,6T, parâmetros de ativação de 49B e dados de pré-treinamento de 33T; DeepSeek-V4-Flash com parâmetros totais de 284B, parâmetros de ativação de 13B e dados de pré-treinamento de 32T; ambos suportam nativamente 1 milhão de contextos de token.
De acordo com os dados de teste de benchmark divulgados pela DeepSeek, nos testes de conhecimento e raciocínio, DeepSeek-V4-Pro-Max obteve o melhor desempenho nos testes Apex Shortlist e Codeforces, superando Claude-Opus-4.6-Max, GPT-5.4-xHigh, Gemin-3.1-Pro-Hight e outros modelos internacionais, demonstrando capacidades lógicas e de algoritmo extremamente fortes; no SimpleQA No teste verificado, está um pouco atrás do Gemini-3.1-Pro-High, mas à frente de Claude e GPT.
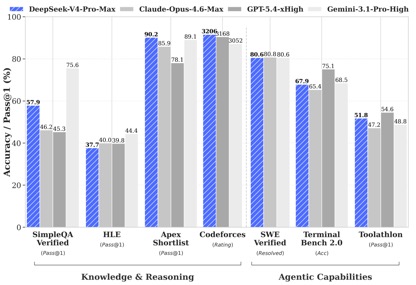
Na avaliação de capacidade Agentic, os três modelos V4, Opus-4.6 e Gemin-3.1-pro ficaram empatados na tarefa SWE Verified, e DeepSeek alcançou um nível atrás apenas de GPT-5.4-xHigh na tarefa Toolathlon, e no Terminal Bench 2.0 alcançou um nível melhor que o Opus-4.6, refletindo suas vantagens em cenários complexos de execução de instruções e chamada de ferramentas.
Atualmente o DeepSeek-V4 se tornou o modelo de codificação agente usado pelos funcionários da empresa. De acordo com o feedback da avaliação, a experiência de uso é melhor que a do Sonnet 4.5 e a qualidade de entrega está próxima do modo sem pensar do Opus 4.6.
Na avaliação de matemática, STEM e códigos competitivos, DeepSeek-V4-Pro superou a maioria dos modelos de código aberto que foram avaliados publicamente e alcançou resultados comparáveis aos principais modelos de código fechado do mundo.
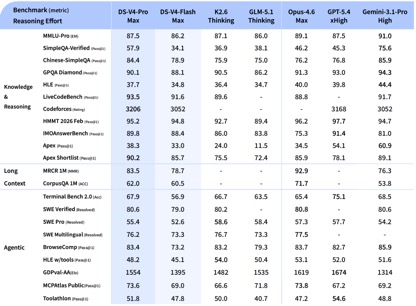
No geral, em termos de processamento de conhecimento e capacidades de raciocínio, o DeepSeek-v4 alcançou uma liderança geral sobre os modelos domésticos de código aberto e é comparável às capacidades de avaliação internacionais. No entanto, em termos de capacidades Agentic, embora o DeepSeek-v4 mais recente tenha feito boas melhorias, a lacuna entre as capacidades de primeiro nível nacionais e internacionais não aumentou, e cada uma está à frente.
" Padrão" 1 milhão de contexto, O açougueiro de preços "está de volta"
Em comparação com as vantagens de desempenho refletidas em vários testes de benchmark, a maior característica desta versão V4 é o avanço nas capacidades de texto longo e a redução adicional nos preços das chamadas API.
Graças ao novo mecanismo de atenção lançado pelo DeepSeek-V4, o V4 alcança recursos de contexto longo líderes mundiais, compactando a dimensão do token e combinando-a com a atenção esparsa do DSA (DeepSeek Sparse Attention). Em comparação com os métodos tradicionais, reduz significativamente os requisitos de computação e memória de vídeo, tornando o contexto de 1M (um milhão) o padrão para todos os serviços oficiais do DeepSeek.
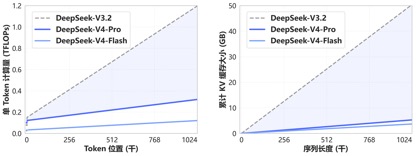
Há um ano, 1 milhão de contextos era o trunfo exclusivo de Gêmeos. Mesmo na maioria dos modelos de código aberto nacionais lançados recentemente, o comprimento dos contextos do modelo estava principalmente na faixa de 128K-200K. DeepSeek transformou diretamente milhões de contextos de "funções de código fechado de ponta" em configurações padrão de código aberto.
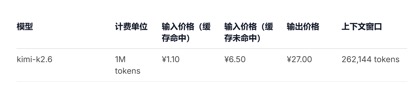
Em termos de chamadas de preços de API, em comparação com o preço unitário de entrada atual do GLM-5.1 de 1,3 yuan-2 yuan/milhão de tokens (acerto de cache) e Kimi-K2.6 1,1 yuan/milhão de tokens (acerto de cache), DeepSeek-v4 -Para as versões pro e flash, os preços unitários de entrada são 1 yuan/milhão de tokens e 0,2 yuan/milhão de tokens, respectivamente. Embora os preços não tenham caído muito, ambos são os mais baixos e a duração do contexto foi ampliada várias vezes.
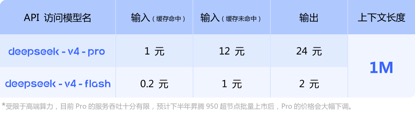
(preço de chamada de API do modelo da série DeepSeek-v4)
[GT20GT ]
(preço de chamada de API do modelo Kimi-k2.6)
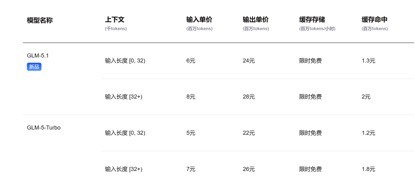
(preço de chamada API do modelo GLM-5.1)
"O avanço no desempenho trazido pelo lançamento do DeepSeek-v4 é menos impactante do que o lançamento do DeepSeek-R1. O desempenho ainda está no primeiro escalão, mas a liderança não foi totalmente ampliada." Na opinião de especialistas do setor, “o lançamento do modelo V4 tem mais a ver com a melhoria dos recursos de texto longo e a redução adicional de preço”.
[ GT1GT] Esta pessoa lamentou: “Após o lançamento anterior dos modelos DeepSeek-V3 e R1, as vantagens de desempenho trazidas pela inovação tecnológica subjacente promoveram diretamente a redução coletiva de preços de toda a indústria nacional de grandes modelos."O poder de computação da Huawei será adicionado em lotes no segundo semestre do ano e o preço do Pro será significativamente reduzido."
É importante notar que na parte inferior das informações de preços da API divulgadas pelo DeepSeek-v4, o oficial observou especificamente: "Limitado pelo poder de computação de ponta, a taxa de transferência de serviço atual do Pro é muito limitada e espera-se que suba 950 supernós no segundo semestre do ano. Após o lançamento em massa, o preço do Pro será significativamente reduzido. "

Isso significa que os modelos da série v4 lançados desta vez foram adaptados para o super nó Ascend 950 da Huawei. Enquanto o Ascend 950 for lançado, a maioria dos usuários poderá usar o DeepSeek-v4 baseado em poder de computação doméstico comparável aos principais modelos internacionais de código fechado.
No documento técnico oficial de código aberto, DeepSeek também mencionou isso, dizendo que v4 foi implementado na GPU NVIDIA e HUAWEI Ascend O esquema EP (paralelismo especializado) refinado foi verificado na plataforma NPUs. Comparado com a poderosa linha de base sem fusão, ele pode atingir um efeito de aceleração de 1,50-1,73 vezes em tarefas de raciocínio geral e pode atingir um efeito de aceleração de 1,96 vezes em cenários sensíveis a atrasos (como dedução de RL e serviços de proxy de alta velocidade).

Após o lançamento do V4, a Huawei Ascend também anunciou que “toda a gama de produtos super node suporta os modelos da série DeepSeek V4”. É relatado que o Ascend 950 reduz o cálculo de atenção e a sobrecarga de acesso à memória integrando kernel e tecnologia paralela multi-stream, melhorando significativamente o desempenho de inferência e combinando vários algoritmos de quantização para alcançar alto rendimento e baixa latência na implantação de inferência do modelo DeepSeek V4.
No início deste mês, o fundador da NVIDIA, Huang Jensen, estava aceitando Dwarkesh. Em uma entrevista exclusiva, Patel disse: "Se o DeepSeek for lançado primeiro na plataforma Huawei, será desastroso para o nosso país (os Estados Unidos)." Na opinião de Huang Renxun, embora o DeepSeek seja um modelo de código aberto e também possa ser usado em produtos NVIDIA, se o DeepSeek for especificamente otimizado para o poder de computação da Huawei, a NVIDIA estará em desvantagem devido a limitações como restrições na compra de poder de computação de ponta.
Agora parece que embora DeepSeek também tenha verificado a solução EP para o poder de computação da Nvidia, o que preocupava Huang Renxun ainda aconteceu. Aos olhos dos especialistas da indústria, "o V4 é um produto forçado pelo poder da computação. No próximo ano, os grandes modelos domésticos amadurecerão gradualmente ao rodar em cartões nacionais."
Os recursos multimodais ainda não apareceram
Infelizmente, embora o DeepSeek V4 tenha sido lançado, esta versão ainda é um modelo de texto puro, sem muitos recursos multimodais, como imagens e vídeos de Vincent. Isso também permite que usuários comuns experimentem e avaliem rapidamente um modelo, o que acrescenta muita dificuldade.

Afinal, à medida que as capacidades dos grandes modelos de linguagem continuam a melhorar e a taxa de alucinação diminui gradualmente, é difícil para perguntas e respostas de conhecimento convencional e único refletirem objetivamente as capacidades abrangentes de um modelo. Para a maioria dos usuários, se quiserem experimentar intuitivamente os recursos do modelo V4, eles terão que baixá-lo e usá-lo pessoalmente por um tempo.
Ao mesmo tempo que o lançamento da série de modelos V4, a DeepSeek também revelou recentemente que planeja arrecadar 50 bilhões de yuans. Pessoas próximas à DeepSeek revelaram que a avaliação de pré-financiamento da DeepSeek é de 300 bilhões de yuans, aproximadamente US$ 44 bilhões. Atualmente, a Tencent Holdings e o Alibaba Group estão negociando para investir na DeepSeek. No entanto, a DeepSeek não respondeu diretamente às perguntas da mídia sobre assuntos relacionados ao financiamento.
Talvez, para o fundador da DeepSeek, Liang Wenfeng, seja uma atitude sábia usar o lançamento do V4 para obter financiamento oportuno para fortalecer sua força quando o crescimento da "inteligência" dos grandes modelos globais está desacelerando, a competição por talentos da indústria está se intensificando e as tendências multimodais e de agência da indústria estão cada vez mais destacadas.