Em 18 de junho, o pesquisador multimodal DeepSeek Chen Xiaokang postou que o modo de reconhecimento de imagem do DeepSeek foi lançado oficialmente na web e no aplicativo. A consulta descobriu que o modo de reconhecimento de imagem no lado do aplicativo do DeepSeek ainda exibe "A função de compreensão de imagem está em teste interno", mas não existe tal aviso na página da web.
No entanto, testes de mídia descobriram que o DeepSeek é menos preciso na identificação de pessoas. Por exemplo, não conseguiu reconhecer o seu chefe, Liang Wenfeng. Num momento o reconheceu como Wang Xing e no outro momento o reconheceu como outra pessoa.


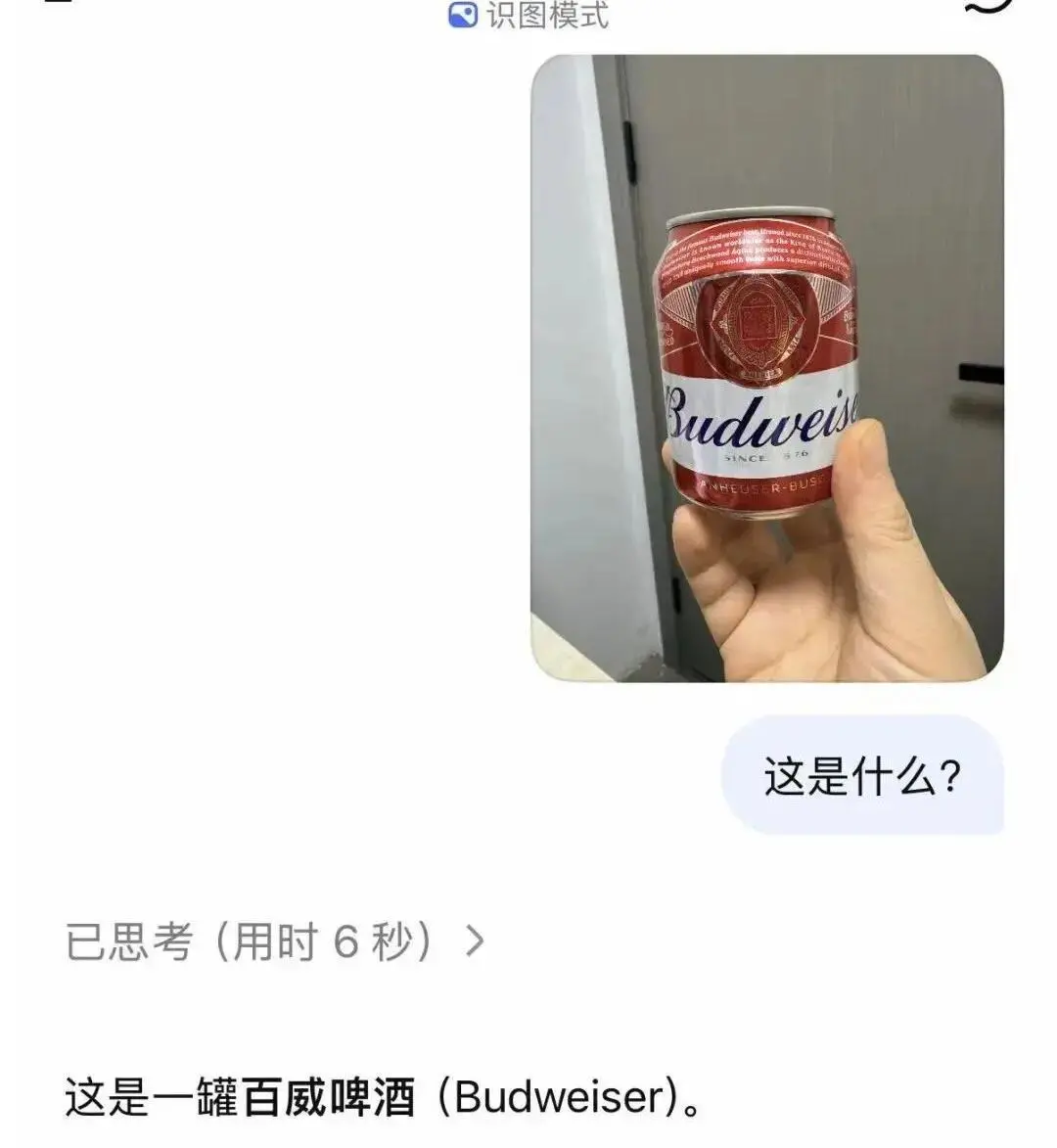
No entanto, a identificação de objetos comuns e edifícios conhecidos tem sido relativamente precisa.
Segundo relatos, há dois meses, o modo de reconhecimento de imagem DeepSeek foi lançado oficialmente em escala de cinza. Como um portal de interação visual nativo, o modo de reconhecimento de imagem DeepSeek é uma função independente de primeiro nível, juntamente com o modo rápido e o modo especialista. Ele elimina completamente as limitações de capacidade dos primeiros modelos de texto puro e alcança uma experiência de diálogo integrada com imagens e texto.
Deve-se lembrar que o modo de reconhecimento de imagem DeepSeek não é uma ferramenta simples de extração de texto de imagem ou uma ferramenta simples de OCR, mas depende do mecanismo de fluxo causal visual DeepSeek-OCR2 autodesenvolvido para construir um ciclo fechado de compreensão visual completo. Os usuários só precisam fazer upload diretamente de imagens com perguntas de texto, e o sistema pode concluir simultaneamente o reconhecimento de objetos, análise de cena, desmontagem de gráficos, extração de texto fino e mineração de detalhes.
É relatado que a DeepSeek concluiu recentemente seu financiamento da Série A, com um montante de financiamento de aproximadamente 51 bilhões de yuans e uma avaliação corporativa pós-investimento de aproximadamente 400 bilhões de yuans.