Ontem, o Grupo Rakuten anunciou o lançamento do maior modelo de inteligência artificial do Japão: Rakuten AI versão 3.0. No entanto, logo após o lançamento do modelo, os internautas japoneses descobriram que ele foi treinado com base no modelo de pesquisa profunda DeepSeek-V3. O treinamento e o ajuste fino com base em modelos de código aberto não são um problema em si, mas os internautas na área de língua japonesa acreditam que o Grupo Rakuten recebeu a taxa de poder de computação patrocinada pelo governo japonês, mas não desenvolveu o modelo em si, por isso pode ser emocionalmente inaceitável.
No entanto, o Grupo Rakuten pode não ter considerado cuidadosamente as consequências antes de lançar este modelo, porque também foi descoberto que o modelo Rakuten AI 3.0 excluiu a licença de código aberto, o que já é uma violação grave do contrato de licença de código aberto.
A abordagem do Grupo Rakuten é a seguinte:
De fato, foi mencionado no comunicado de imprensa oficial que o Rakuten AI 3.0 é baseado nos excelentes resultados da comunidade de código aberto
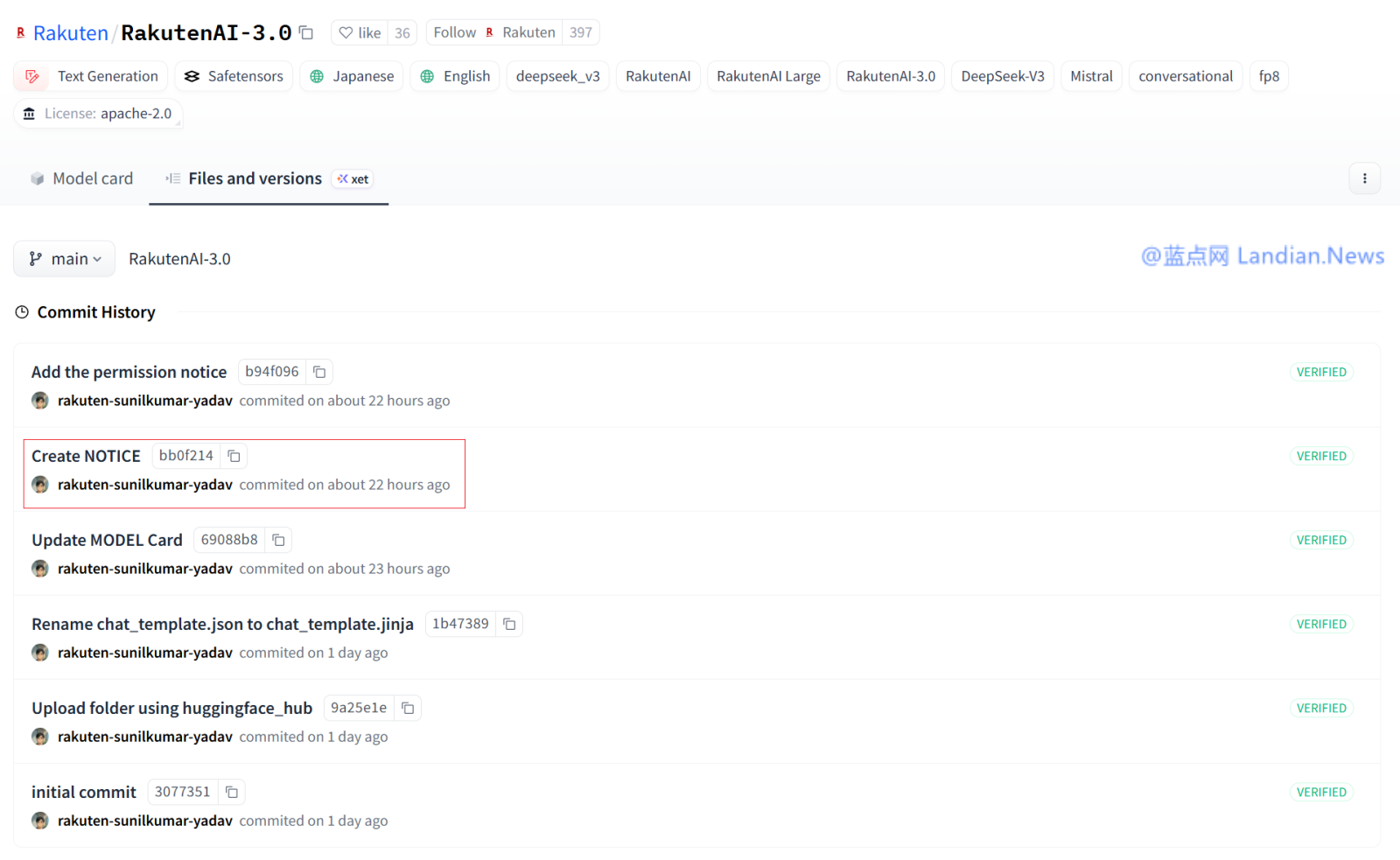
Na versão de código aberto, o arquivo de configuração do Rakuten AI 3.0 contém DeepSeek-V3 e outras palavras relacionadas
Rakuten Group remove o arquivo de licença de código aberto (LICENSE) do DeepSeek-V3 da versão de código aberto
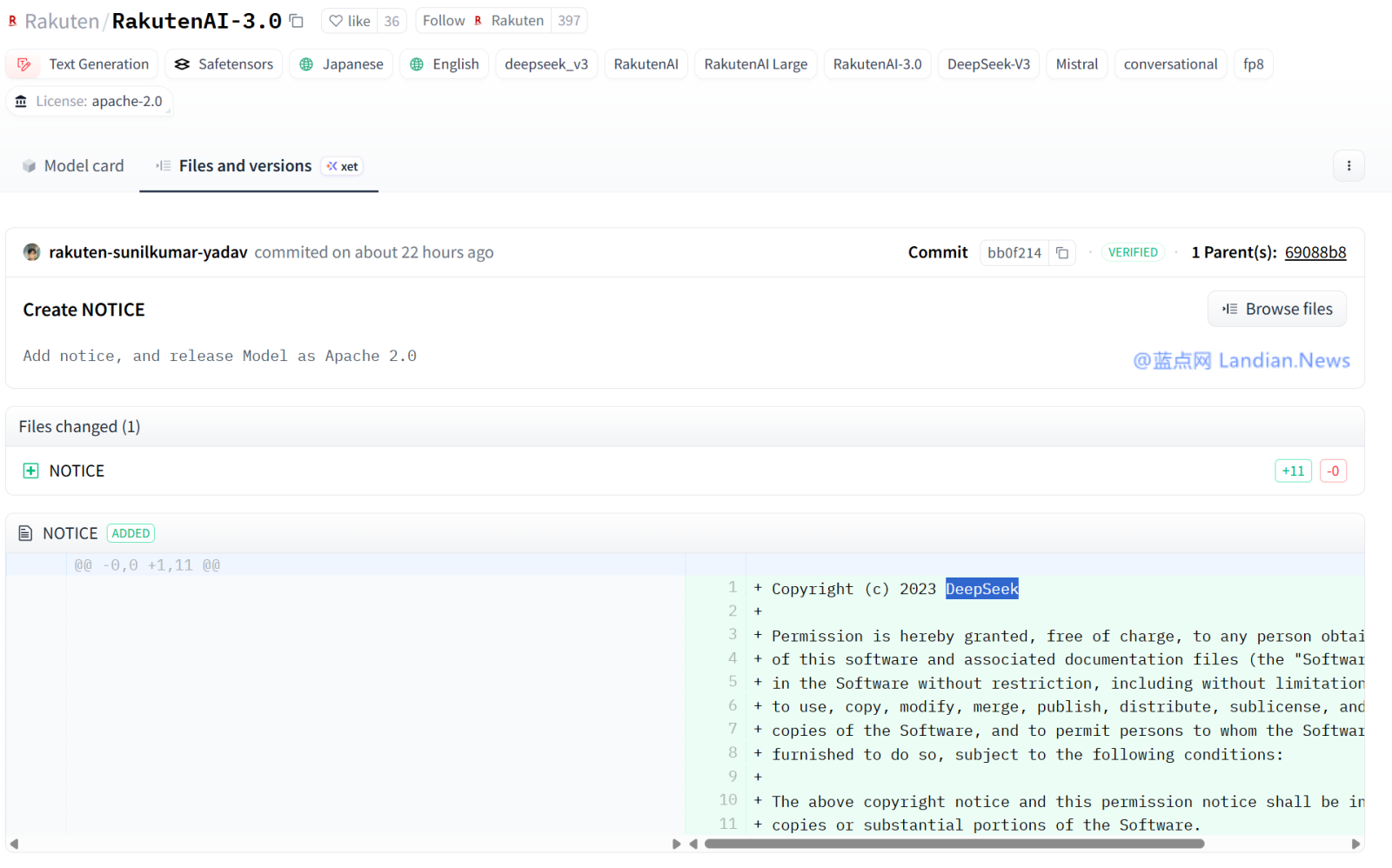
Depois de ser capturado por internautas, Rakuten adicionou novamente um arquivo chamado NOTICE (notice ou prompt), que contém a declaração original do DeepSeek-V3
Remediação após uma violação inicial:
A licença de código aberto usada pelo Deep Search é a licença MIT, que é extremamente flexível. O Grupo Rakuten não incluiu a licença LICENSE na versão inicial, o que já era uma violação. Posteriormente, ele corrigiu o problema enviando um arquivo AVISO. A licença MIT não exige que a declaração de código aberto esteja no nome LICENSE, portanto o Rakuten Group cumpriu após a solução.
Acontece que esta abordagem é antiética e inconsistente com as normas da comunidade de código aberto, por isso tem causado grande controvérsia. Esta abordagem oculta foi criticada pela comunidade como baixa, mas pelo menos agora está claro que não viola o acordo de código aberto após a remediação.
Quanto à questão controversa entre os internautas na área japonesa de que receberam subsídios japoneses, mas não treinaram seus próprios modelos, eles só podem esperar pela discussão entre o governo japonês e o Grupo Rakuten (os desafios relevantes não proíbem o treinamento ou o ajuste fino com base em modelos de código aberto).