Em 27 de junho, DeepSeek lançou o relatório técnico do DSpark e a base de código DeepSpec. O modelo básico do DeepSeek-V4 não mudou. A novidade é um módulo de decodificação especulativa do lado do servidor: DSpark. DeepSeek coloca isso de forma muito direta na página do modelo HuggingFace: V4-Pro-DSpark e V4-Flash-DSpark “não são modelos novos”. Essas duas páginas apontam para o mesmo ponto de verificação do modelo, mais a versão do serviço após especular sobre o módulo decodificado.

Isso significa que o DSpark não torna o modelo subitamente mais inteligente. O objetivo é fornecer respostas de maneira mais rápida e barata depois que o modelo estiver online.
O relatório técnico afirmou que o DSpark foi implantado no sistema de serviço online do DeepSeek-V4. Sob o tráfego real do usuário, em comparação com a linha de base de produção anterior do MTP-1, que é a solução de geração de especulação on-line da geração anterior da DeepSeek, a velocidade de geração por usuário do V4-Flash é aumentada em 60% a 85%, e do V4-Pro é aumentada em 57% a 78%, desde que as condições de transferência sejam correspondidas.
O “rápido” aqui também precisa ser moderado.Refere-se principalmente ao estágio de geração, ou seja, à velocidade com que o modelo continua a produzir tokens. Isso não significa que o tempo de resposta ponta a ponta de todas as solicitações dos usuários seja 85% mais rápido.O pré-preenchimento de palavras de prompt longas, a recuperação, a invocação de ferramentas, o enfileiramento e os atrasos de rede ainda afetarão o tempo de espera real dos usuários.
Depois que o modelo estiver online, ainda haverá uma conta de inferência
Isso não é tão animado quanto o lançamento de um novo modelo, mas está mais próximo da realidade que as empresas de IA enfrentam todos os dias:O custo não termina após o treinamento do modelo.
Chatbots, assistentes de código, agentes e produtos baseados em pesquisa continuam consumindo tempo de GPU em cada chamada. Se o modelo for mais lento, os usuários terão que esperar mais; se a inferência for mais cara, será mais difícil para os fabricantes abrirem modelos de alta qualidade para mais cenários.
A indústria de IA se acostumou mais a discutir custos de treinamento nos últimos dois anos: quantas GPUs uma empresa precisa comprar, qual o tamanho do cluster que ela deve construir e quanto custará para treinar o modelo da próxima geração. Mas depois que o modelo se tornar realmente um produto, outro tipo de custo continuará surgindo: a inferência.
O treinamento é como um grande projeto e o raciocínio é como uma conta de luz.Enquanto os usuários ainda fizerem perguntas, os agentes continuarem executando tarefas e os assistentes de código ainda gerarem patches, o modelo continuará consumindo poder computacional.
Os grandes modelos de serviços eventualmente retornarão a dois indicadores: velocidade e custo unitário do token. As páginas de preços da API geralmente cobram com base em tokens de entrada e tokens de saída, e as empresas também dividirão diferentes modelos, caches, rotas e comprimentos de contexto em itens de custo internamente.
O DSpark não pode ser diretamente equiparado à redução de preço, mas se o mesmo cluster de GPU puder permitir que os usuários obtenham respostas mais rapidamente com rendimento semelhante, isso significa que o mesmo hardware pode atender mais usuários ou a mesma experiência de usuário pode ser fornecida com menos placas.
"Adivinhe primeiro, depois teste"
A ideia de decodificação especulativa pode ser entendida aproximadamente como “adivinhe primeiro, depois teste”.
Quando um modelo grande gera texto, ele geralmente gera token após token. Depois que o token anterior for lançado, o próximo token saberá o que pegar. Este método é estável, mas lento. A decodificação especulativa permitirá que um módulo de rascunho mais leve adivinhe um token candidato com antecedência, e o grande modelo alvo será verificado em lotes. A estimativa correta é aceita diretamente e a estimativa incorreta é corrigida.
Modelos pequenos não podem tomar decisões para modelos grandes. Quais tokens são finalmente aceitos ainda são verificados pelo modelo de destino; quando implementado corretamente, altera o método de geração e não altera a distribuição de saída do modelo alvo.A aceleração vem do fato de modelos grandes validarem candidatos em lotes, em vez de de forma incremental.
O que o DSpark mudou foi como gerar um rascunho
O artigo não para na explicação “adivinhe primeiro e depois teste”. Ele se concentra em como gerar rascunhos.

Os projectos de estratégias existentes enquadram-se, em termos gerais, em duas categorias. O redator autorregressivo é mais estável porque o token posterior verá o token anterior, mas à medida que o draft se torna mais longo, o atraso também aumentará. O redator paralelo é mais rápido e pode adivinhar um parágrafo inteiro de uma vez, mas cada posição é adivinhada separadamente. Os tokens posteriores são facilmente desconectados dos anteriores, e é mais provável que a taxa de aceitação diminua à medida que avança.
DSpark opta por fazer concessões.A palavra-chave no título do artigo é “Geração Semi-Autoregressiva”. Ele primeiro usa um método paralelo para propor um candidato e, em seguida, usa uma camada sequencial leve para modificar o relacionamento condicional dos tokens subsequentes. Isto não apenas mantém a velocidade da geração paralela, mas também permite que os candidatos subsequentes vejam o que foi adivinhado anteriormente.

Outro ponto importante é quanto tempo dura a verificação.
Quanto mais tokens candidatos você adivinhar, menos você economiza. Se você sabe que a segunda metade provavelmente será rejeitada e ainda assim a entrega a um modelo grande para verificação, você está gastando tempo de GPU em uma posição de baixo valor.O DSpark analisará a confiança do candidato e a carga atual do sistema para determinar dinamicamente a duração da verificação.Se a GPU estiver vazia, você poderá realizar vários testes; quando a carga é alta, o poder de computação é reservado para as peças com maior probabilidade de serem aceitas.
É disso que fala o “Programado de Confiança” no título do artigo.

DSpark aposta nas rotas técnicas existentes
DSpark especula sobre a rota de decodificação existente e é mais como uma referência pública depois que DeepSeek empurra essa rota técnica para serviços online.
SpecInfer colocou previsão de modelo pequeno, árvore de token e verificação paralela no sistema de serviço de modelo grande já em 2023; A Medusa propôs adicionar vários cabeçotes de decodificação ao modelo em 2024 para prever vários tokens subsequentes de uma só vez; a série EAGLE continua a melhorar a taxa de aceitação em torno de modelos de rascunho e árvores de rascunho dinâmicas. Estruturas de inferência como vLLM, SGLang e TensorRT-LLM há muito consideram a decodificação especulativa uma ferramenta importante para reduzir a latência.
A vantagem do DSpark é que ele lida com vários problemas de produção em conjunto: como gerar rascunhos, como manter os candidatos consistentes, como o comprimento da verificação muda com a carga e quanta velocidade pode ser melhorada sob tráfego online real.
Palavras-chave que aparecem repetidamente no documento também mudaram de “melhoria da capacidade do modelo” para termos do lado do serviço, como velocidade de geração por usuário, rendimento correspondente e acordo de nível de serviço (SLA).
Isso também explica por que você não pode simplesmente escolher o maior número para observar. Na verdade, existem dados de alto rendimento, como 661% e 406% no papel, mas eles vêm de metas de velocidade por usuário mais rigorosas: sob essa configuração, a antiga linha de base em si já está perto do limite das capacidades de serviço, e a vantagem relativa do DSpark será amplificada.
O que pode realmente ilustrar os benefícios normais é o conjunto anterior de números: taxa de transferência correspondente, distribuição real do tráfego e o objeto de comparação é MTP-1.
O que o DeepSpec pode reproduzir?
DeepSeek também abre o DeepSpec de código-fonte. Esta é uma biblioteca de códigos para treinar e avaliar modelos de rascunho de decodificação especulativa. Inclui processos de preparação de dados, treinamento e avaliação, e também libera pontos de verificação relevantes em Qwen3, Gemma e outros modelos.
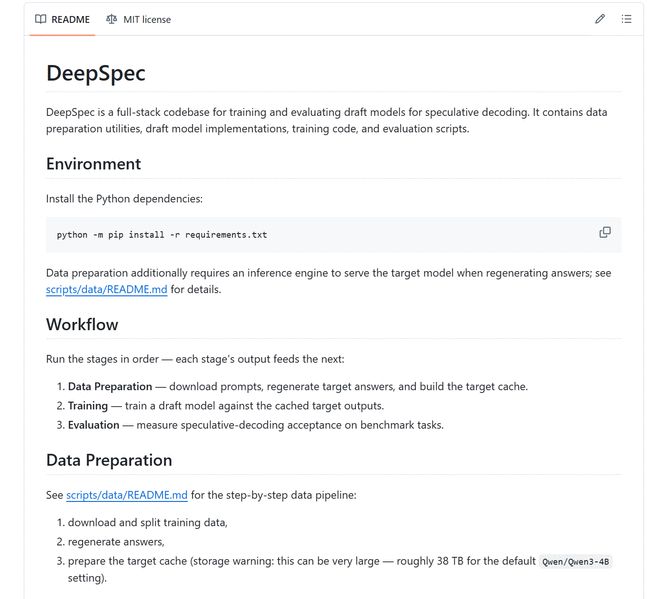
mas,Código aberto não significa “baixar e reproduzir”.A documentação do projeto indica que na configuração padrão Qwen3-4B, o cache do modelo de destino pode estar próximo de 38 TB; o script de treinamento padrão assume 8 GPUs em um único nó; para que os resultados do documento sejam alinhados, as configurações de treinamento devem ser estritamente consistentes e é necessário um ajuste adicional do modelo preliminar em áreas específicas.
O mundo exterior pode verificar parte do método e também transplantar o DeepSpec para outros modelos de código aberto, mas o conjunto de números de melhoria de velocidade no serviço online DeepSeek-V4 ainda vem da própria escala de hardware, distribuição de tráfego e agendamento do sistema de produção do DeepSeek.
Código aberto é o método, não o ambiente.
A comunidade está mais preocupada com limites recorrentes
A discussão sobre
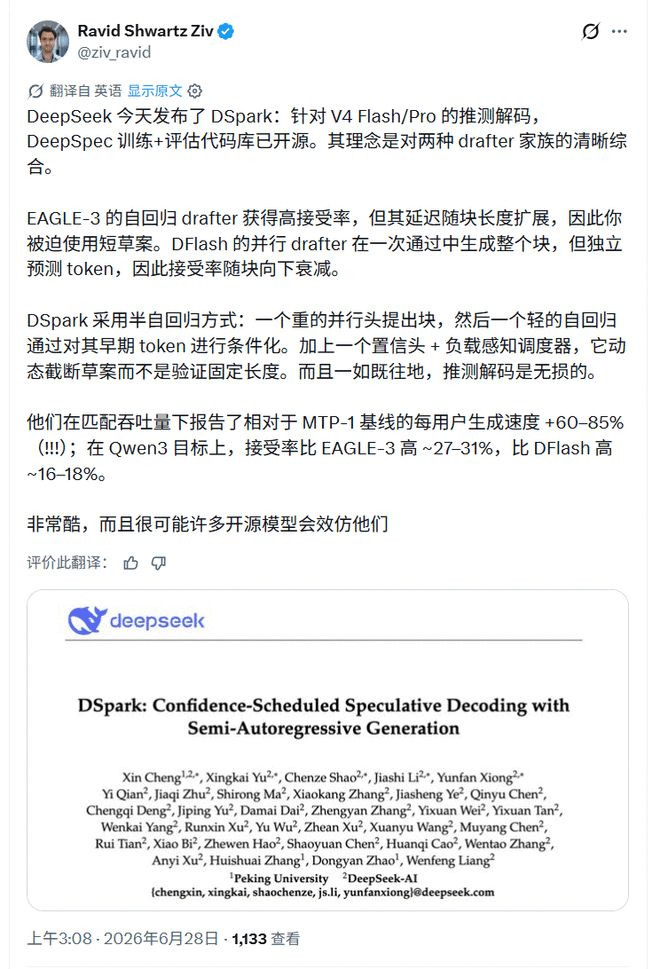
O pesquisador de IA Ravid ShwartzZiv resume o DSpark como um compromisso entre dois tipos de redatores: o redator paralelo é rápido, mas a taxa de aceitação diminui ao longo do bloco candidato; o redator autorregressivo é estável, mas o atraso aumenta com a duração do rascunho. Ele mencionou especificamente dois componentes adicionados ao DSpark: o cabeçote de julgamento de confiança e o agendador com reconhecimento de carga, e adicionou um limite principal: “Como toda decodificação especulativa, ela não tem perdas”.
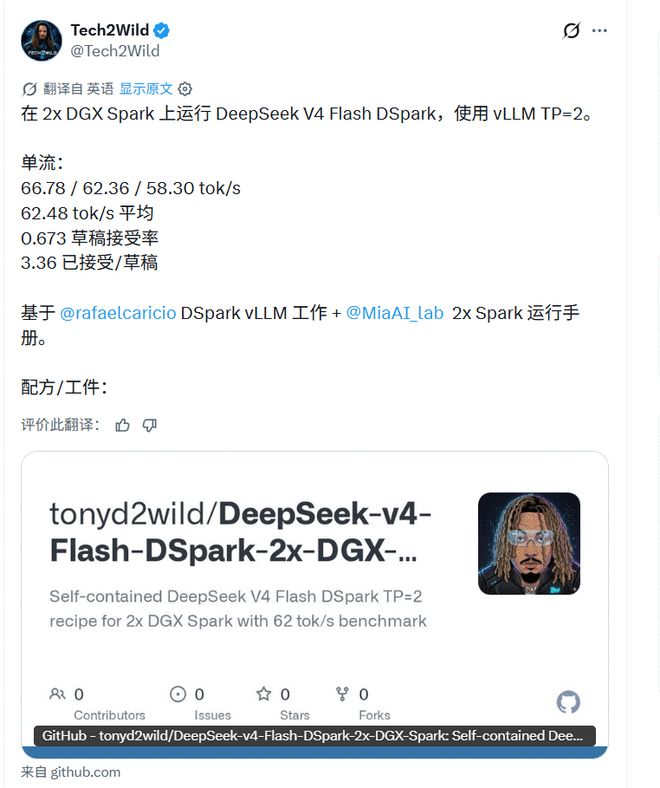
Os engenheiros estão mais preocupados se ele pode funcionar. O contribuidor do vLLM, Rafael Caricio, disse que executou o modo DSpark do DeepSeek-V4-Flash em DGX Spark GB10 duplo, e a decodificação de fluxo único foi de cerca de 60 tok/s, o que é cerca de 1,5 vezes a do MTP-1.
Ele também mencionou que a sessão de código real expôs problemas que os benchmarks sintéticos não conseguiam ver: o gargalo não é apenas a velocidade do núcleo de computação, mas a taxa de aceitação do rascunho cairá significativamente em um contexto longo.
A Tech2Wild também forneceu dados locais em uma direção semelhante, mostrando que o V4-Flash-DSpark foi testado em um ambiente vLLM específico. No entanto, tais resultados são altamente dependentes do modelo de hardware, da versão do patch da estrutura, do comprimento do contexto e das configurações de simultaneidade. Os resultados podem ser completamente diferentes em outro ambiente.
Também há pessoas que lembram especificamente os limites. AcingAI apontou em
Isso nos lembra que parte da vantagem do DSpark vem do agendamento com reconhecimento de carga, e o efeito do agendamento depende naturalmente da escala de tráfego e da configuração de hardware do ambiente de produção.
Mesma potência, menos potência de computação
Em um relatório de 28 de junho, o South China Morning Post analisou o DSpark em termos de gargalos de inferência, pressão do chip e tempo de espera do usuário. Essa perspectiva está mais próxima da realidade do produto do que “Qual modelo o DeepSeek lançou novamente?”
As empresas de IA continuarão a comparar as capacidades dos modelos, mas quando a lacuna de capacidades for reduzida, quem puder fornecer as mesmas capacidades de forma mais rápida e barata também se tornará parte da concorrência.
Empresas como a DeepSeek precisam deixar isso especialmente claro. DeepSeek sempre considerou o baixo custo e a alta eficiência como um importante ponto de entrada para o mundo exterior entendê-lo. Da narrativa de treinamento do modelo ao preço da API, o que mais chama a atenção não é se ela possui uma escala de parâmetros maior, mas se pode baratear os mesmos recursos.
O DSpark continua esta linha: isso não prova que o V4 ficou subitamente mais inteligente, ele prova que o V4 pode desperdiçar menos poder computacional de raciocínio ao atender os usuários.
Se ampliarmos um pouco mais nossa perspectiva, a otimização de inferência também afetará a ecologia do modelo de código aberto. O modelo de código aberto costumava ser considerado “barato”, mas quando for realmente implantado, memória gráfica, rendimento, simultaneidade, latência e complexidade de operação e manutenção se tornarão custos.
Se um modelo pode ser de código aberto, isso significa apenas que todos podem obtê-lo; se ele pode atender a um grande número de usuários de maneira barata depende se a pilha de inferência consegue acompanhar.
A DeepSpec divulgou Qwen3, Gemma e outros pontos de verificação, indicando que esse assunto não para no próprio DeepSeek-V4. A extensão da migração depende do progresso real da adaptação da comunidade, do apoio ao quadro e da compatibilidade do hardware; mas, a julgar pelas informações públicas atuais, o DeepSeek seguiu esse caminho fora de seu próprio modelo.
O valor do DSpark está aqui.Ele adiciona uma camada de ferramentas de serviço de inferência à V4 que está mais próxima do sistema de produção, em vez de apenas um novo rótulo de capacidade.
O que vale a pena observar a seguir não é apenas a velocidade com que o DeepSeek pode ser executado, mas também quantas pessoas podem passar por esse caminho. DeepSpec lançou pontos de verificação e processos de treinamento, e especula-se que a decodificação está deixando de ser uma escolha de engenharia da empresa para se tornar um meio comum de inferência de código aberto para reduzir custos.Isso presumindo que outras estruturas e hardware possam acompanhar.