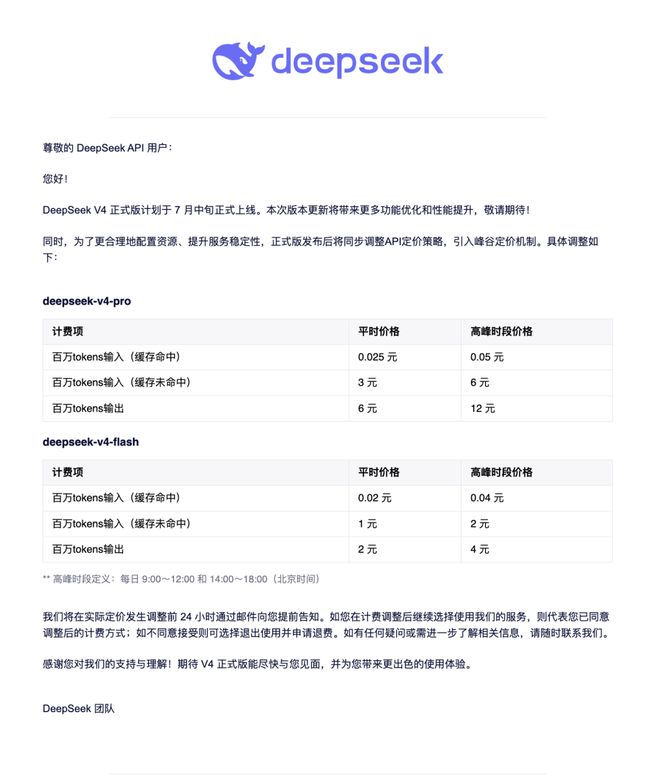
Em 29 de junho, um e-mail de lembrete de atualização enviado pelo DeepSeek aos usuários mostrou que a versão oficial do DeepSeek V4 está programada para ser lançada oficialmente em meados de julho e com ela virão mais otimizações de recursos e melhorias de desempenho, bem como um mecanismo de preços de pico e vale. De acordo com o e-mail, das 9h às 12h e das 14h às 18h, horário de Pequim, todos os dias são listados como horários de pico e o preço da chamada é o dobro do preço normal. Ao mesmo tempo, DeepSeek afirmou que notificará os usuários por e-mail com 24 horas de antecedência antes que ocorram ajustes relevantes.
“Redução permanente de preços” antes de “aumento de preços”
É relatado que esta não é a primeira vez que DeepSeek ajusta os preços este ano. O documento oficial da API mostra que o DeepSeek é cobrado por milhão de tokens e cobrado separadamente com base em acertos, perdas de cache e tokens de saída. Ao mesmo tempo, a própria série DeepSeek V4 possui altos requisitos de poder de computação.
Em 24 de abril, quando DeepSeek lançou o V4 Preview, ele afirmou que o V4 Pro tinha 1,6 trilhão de parâmetros totais e 49 bilhões de parâmetros de ativação, e o V4 Flash tinha 284 bilhões de parâmetros totais e 13 bilhões de parâmetros de ativação. Ambos suportam contexto de 1 milhão de tokens.
O documento oficial também mostra que o limite de simultaneidade do V4 Flash é 2.500; enquanto o modelo de alto desempenho do V4 Pro tem um limite de simultaneidade de 500 e sua elasticidade de fornecimento é mais fraca que o Flash.
Em 23 de maio, DeepSeek anunciou que converteria o desconto anterior de 75% no V4 Pro em um preço permanente, e a taxa de API seria reduzida do máximo anterior de 24 yuans/milhão de tokens para um máximo de 6 yuans/milhão de tokens. O mercado especulou na época que isso poderia estar relacionado ao aumento da oferta de chips Ascend 950 da Huawei, mas a DeepSeek não respondeu a isso.
Após a redução permanente de preço, o preço normal atual do V4 Pro é de 0,025 yuan/milhão de tokens para entrada de acertos de cache, 3 yuans/milhão de tokens para cache miss e 6 yuans/milhão de tokens para saída. Os preços correspondentes do V4 Flash são 0,02 yuan, 1 yuan e 2 yuan, respectivamente. Durante os horários de pico, esses preços dobrarão, mas ainda serão mais baixos do que quando foram divulgados anteriormente.
Para usuários comuns, esse ajuste pode não se refletir diretamente nas alterações nas tarifas dos aplicativos de chat; os principais afetados são desenvolvedores, empresas de aplicativos de IA e clientes corporativos que acessam o modelo DeepSeek por meio de APIs.
Tomando o V4 Pro como exemplo, ao calcular tokens de saída, se um aplicativo de IA consumir 100 milhões de tokens de saída por dia durante os horários de pico, o custo normal será de cerca de 600 yuans e o preço de pico será de cerca de 1.200 yuans; se consumir 1 bilhão de tokens de produção por dia, o custo aumentará de cerca de 6.000 yuans para 12.000 yuans. Para aplicações de alta frequência, como atendimento ao cliente, assistentes de código, agentes de escritório e perguntas e respostas aprimoradas por pesquisa, dobrar o preço pode afetar diretamente as margens de lucro bruto e as estratégias de chamada.
Não se trata de desistir da rota do preço baixo
Atualmente, a introdução de preços de pico e vale no DeepSeek não significa desistir da rota de preço baixo. Para ser mais preciso, a DeepSeek apenas reestratificou os recursos de computação de acordo com os períodos de uso, de modo que sua estratégia de preços baixos começou a mudar de um preço baixo unificado para um preço barato refinado.
Porque apenas a julgar pelo preço dos tokens, o DeepSeek ainda está na faixa de preço baixo "realmente perfumado" após a introdução do horário de pico e vale, e ainda é muito competitivo no mercado internacional. Esta também é a razão do aumento de preço do DeepSeek.
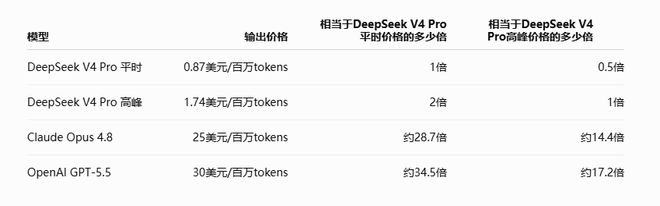
De acordo com a página de preços da API DeepSeek English, o preço de saída do V4 Pro é de US$ 0,87/milhão de tokens, o que é aproximadamente US$ 1,74 com base na duplicação do pico. Em contraste, a página de preços oficial da OpenAI mostra que o preço padrão da API do GPT-5.5 é de US$ 5 para entrada, US$ 0,5 para entrada de cache e US$ 30 para saída/milhão de tokens; o preço normal do Claude Opus 4.8 da Anthropic é de US$ 5 para entrada e US$ 25 para produção/milhão de tokens.
Se olharmos apenas para os tokens de saída, o preço dos modelos topo de linha do OpenAI e Anthropic ainda é cerca de 14 a 17 vezes o preço máximo do DeepSeek V4 Pro.
Por outro lado, à medida que o modelo de preços dos grandes modelos nos mercados estrangeiros muda de assinaturas fixas para facturação por tokens, os custos de utilização das empresas começaram a aumentar dramaticamente. Muitas empresas estrangeiras com orçamentos limitados estão recorrendo cada vez mais a modelos de baixo custo, como o DeepSeek.
De acordo com relatórios anteriores, tomemos como exemplo o software de chamada de táxi Uber. Após a mudança no modelo de precificação de grandes modelos, o orçamento de IA da empresa para o ano inteiro foi rapidamente consumido em apenas 4 meses, resultando na necessidade de a empresa restringir seu uso pelos executivos. Foi uma sorte ser “a primeira grande empresa a parar de gastar dinheiro com IA”.
Executivos da Microsoft, Coinbase e outras empresas também começaram a enfatizar que muitas tarefas empresariais nem sempre exigem os modelos maiores e mais caros. Essas mudanças levaram as empresas a adotar mais "roteamento multimodelo", ou seja, atribuir tarefas simples a modelos baratos e tarefas complexas a modelos de última geração.
Portanto, os dados do OpenRouter mostram que os modelos de código aberto representaram cerca de 65% do volume de processamento de tokens em sua plataforma. Entre eles, o uso de modelos de baixo custo na China, representados pelo DeepSeek, aumentou significativamente, o que reflete intuitivamente que os usuários estrangeiros entraram na era da "consciência de custos".