Hoje, o Google anunciou um novo código abertoModelo de incorporação aberta EmbeddingGemma. Este modelo é pequeno e amplo, com308 milhões de parâmetros, projetado paraIA do lado do dispositivoProjetado para suportar a implantação de geração aprimorada de recuperação (RAG), pesquisa semântica e outros aplicativos em laptops, telefones celulares e outros dispositivos.

Uma característica importante do EmbeddingGemma é sua capacidade deGere vetores de incorporação de alta qualidade com boa privacidade, mesmo emDesconectadoEle pode funcionar normalmente mesmo em circunstâncias normais e seu desempenho está no mesmo nível do Qwen-Embedding-0.6B, que tem o dobro do tamanho.
▲ Captura de tela da página de código aberto Hugging Face
Abraçando o endereço do rosto:
https://huggingface.co/collections/google/embeddinggemma-68b9ae3a72a82f0562a80dc4
Segundo o Google, o EmbeddingGemma possui os seguintes destaques:
1. Melhor da classe:No Massive Text Embedding Benchmark (MTEB), o EmbeddingGemma ocupa a posição mais alta entre os modelos abertos de incorporação de texto multilíngue abaixo de 500 milhões. EmbeddingGemma é construído na arquitetura Gemma 3 e foi treinado para mais de 100 idiomas. É pequeno e pode funcionar com menos de 200 MB de memória após a quantificação.
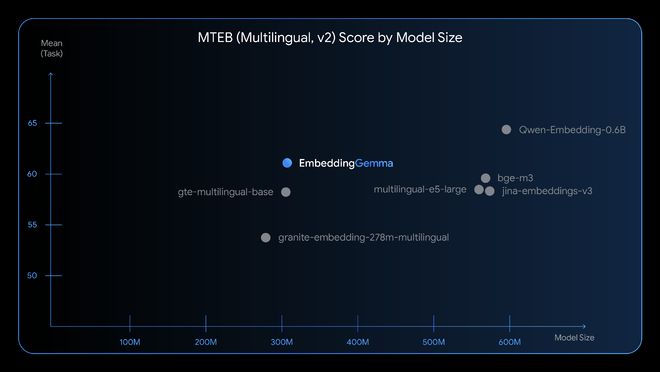
▲ Pontuação MTEB: O desempenho do EmbeddingGemma é comparável aos modelos de topo com o dobro do tamanho
2. Projetado para trabalho offline flexível:Pequeno, rápido e eficiente, ele fornece tamanho de saída personalizável e uma janela de contexto de token de 2K, e pode ser executado em dispositivos comuns, como telefones celulares, laptops e desktops. Ele foi projetado para funcionar com Gemma 3n, trabalhando em conjunto para desbloquear novos casos de uso para pipelines RAG móveis, pesquisa semântica e muito mais.
3. Integre-se com ferramentas populares:Para facilitar a introdução do EmbeddingGemma, ele já funciona com as ferramentas favoritas dos usuários, como transformadores de frases, llama.cpp, MLX, Ollama, LiteRT, transformers.js, LMStudio, Weaviate, Cloudflare, LlamaIndex, LangChain e muito mais.
1. Ele pode gerar vetores de incorporação de alta qualidade e o RAG final gera respostas mais precisas.
EmbeddingGemma irá gerar vetores de incorporação. No contexto deste artigo, pode converter texto em vetores numéricos e representar a semântica do texto no espaço de alta dimensão; quanto maior a qualidade do vetor de incorporação, melhor será a representação das nuances da linguagem e dos recursos complexos.
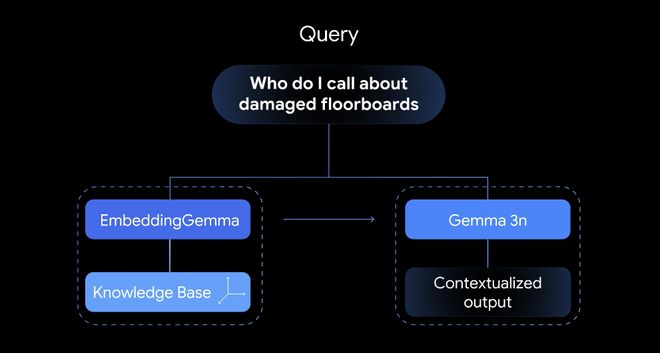
▲ EmbeddingGemma irá gerar vetores de incorporação
Existem dois estágios principais na construção de um processo RAG: recuperar o contexto relevante com base na entrada do usuário e gerar respostas bem fundamentadas com base nesse contexto.
Para implementar a função de recuperação, os usuários podem primeiro gerar um vetor de incorporação da palavra prompt e, em seguida, calcular a semelhança entre esse vetor e os vetores de incorporação de todos os documentos do sistema - desta forma, os fragmentos de texto mais relevantes para a consulta do usuário podem ser obtidos.
Os usuários podem então alimentar esses trechos de texto, juntamente com a consulta original, em um modelo generativo como o Gemma 3 para gerar respostas contextualmente relevantes. Por exemplo, o modelo pode entender o número de telefone necessário para ligar para um carpinteiro para consertar um piso danificado.
Para que este processo RAG seja eficaz, a qualidade da etapa inicial de pesquisa é crítica. Vetores de incorporação de baixa qualidade podem resultar na recuperação de documentos irrelevantes, resultando em respostas imprecisas ou sem sentido.
A vantagem de desempenho do EmbeddingGemma se reflete nisso - ele pode fornecer representação (texto) de alta qualidade e fornecer suporte básico para aplicativos finais precisos e confiáveis.
2. Qwen-Embedding-0.6B, que tem um desempenho que quase dobrou em tamanho, mas é pequeno em tamanho.
O EmbeddingGemma fornece recursos de compreensão de texto de última geração, proporcionais à sua escala, com desempenho particularmente forte na geração de incorporação multilíngue.
Comparado com outros modelos de incorporação populares, o EmbeddingGemma tem um bom desempenho em tarefas como recuperação, classificação e clustering.
EmbeddingGemma alcançou completamente o modelo gte-multilingual-base do mesmo tamanho em Média (Tarefa), Recuperação, Classificação, Clustering e outros testes. Os resultados do seu teste também estão próximos do Qwen-Embedding-0.6B, que tem o dobro do tamanho.
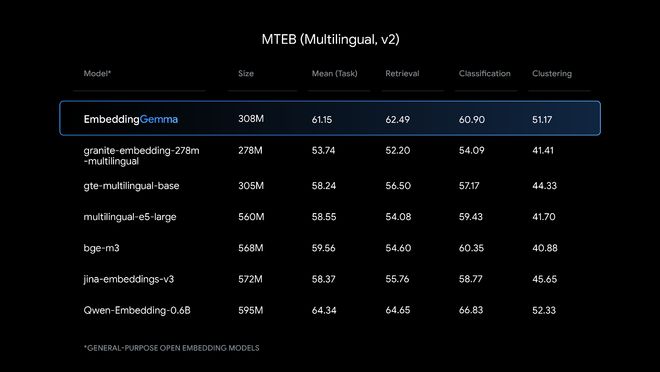
▲ Status de avaliação de EmbeddingGemma
O modelo EmbeddingGemma possui parâmetros de 308M, compostos principalmente por aproximadamente 100M de parâmetros de modelo e 200M de parâmetros de incorporação.
Para obter maior flexibilidade, o EmbeddingGemma aproveita o Matryoshka Representation Learning (MRL) para fornecer vários tamanhos de incorporação em um único modelo. Os desenvolvedores podem usar o vetor completo de 768 dimensões para obter melhor qualidade ou truncá-lo para dimensões menores (128, 256 ou 512) para aumentar a velocidade e reduzir os custos de armazenamento.
O Google reduziu o tempo de inferência incorporado (256 tokens de entrada) para <15ms no EdgeTPU, quebrando o limite de velocidade, o que significa que a função de IA do usuário pode fornecer resposta em tempo real e obter interação suave e instantânea.
Usando o treinamento com reconhecimento de quantização (QAT), o Google reduziu significativamente o uso de RAM para menos de 200 MB, mantendo a qualidade do modelo.
3. Ele pode ser usado quando desconectado da Internet e pode funcionar com menos de 200 MB de memória.
O EmbeddingGemma permite que os desenvolvedores criem aplicativos flexíveis e com foco na privacidade no dispositivo. Ele gera incorporações de documentos diretamente no hardware do dispositivo, ajudando a manter seguros os dados confidenciais do usuário.
Ele usa o mesmo tokenizer do Gemma 3n para processamento de texto, reduzindo assim o consumo de memória dos aplicativos RAG. Os usuários podem usar o EmbeddingGemma para desbloquear novos recursos, como:
Pesquise arquivos pessoais, textos, e-mails e notificações de uma só vez, sem conexão com a Internet.
Chatbots de suporte offline personalizados, específicos do setor e com RAG e Gemma 3n.
Classifique as consultas do usuário em chamadas de função relevantes para ajudar no entendimento do agente móvel (necessidades do usuário).
A imagem abaixo é uma demonstração interativa do EmbeddingGemma, que visualiza a incorporação de texto no espaço tridimensional. O modelo funciona inteiramente no dispositivo.

▲ Demonstração interativa de EmbeddingGemma (Fonte: Joshua da equipe Hugging Face)
Endereço da experiência de demonstração:
https://huggingface.co/spaces/webml-community/semantic-galaxy)
Conclusão: O tamanho pequeno e as grandes capacidades aceleram o desenvolvimento da inteligência final
O lançamento do EmbeddingGemma marca um novo avanço para o Google em miniaturização, multilíngue e IA do lado do dispositivo. Não só está próximo de modelos maiores em desempenho, mas também equilibra velocidade, memória e privacidade.
No futuro, à medida que aplicações como RAG e pesquisa semântica continuarem a se espalhar para dispositivos pessoais, o EmbeddingGemma poderá se tornar uma pedra angular importante na promoção da popularização da inteligência do lado do dispositivo.